



정윤진 피보탈 랩 프린시플 테크놀로지스트
[컴퓨터월드]

| 1. 스프링 부트 <2017.5월호> 2. 스프링 클라우드 Config server <2017.6월호> 3. 스프링 클라우드 Service discovery <2017.7월호> 4. 스프링 클라우드 Zipkin <이번호> 5. 스프링 클라우드 Zuul 6. 스프링 클라우드 Hystrix |
단일 서비스를 운영하거나 여러 개의 시스템을 사용해서 동작하는 서비스를 모니터링하는 것은 매우 중요한 일이다. 일반적으로 모니터링이라는 것은 시스템이 서비스에 유입되는 사용자들에게 제공하는 기능들을 적절히 제공하고 있는지 여부를 판가름할 수 있는 지표들을 일정 주기로 확인하는 형태로 운용되는 것을 말한다. 따라서 시스템에서 제공하는 스케줄러, 이를테면 크론과 같은 도구를 사용해 주기적으로 스크립트를 실행하거나, 아예 /proc과 같은 디렉토리에서 제공하는 정보 및 애플리케이션 정보를 취합하는 목적을 갖는 에이전트를 설치해 운용하는 경우도 있다.
가상화와 및 클라우드를 기반으로 한 서비스들을 사용하는 경우, 이런 시스템 수준의 모니터링은 함께 제공되는 경우가 많다. 이전에 실제 하드웨어 기반의 운영체제와 시스템을 사용하는 경우에는 시스템 각 부, 이를테면 프로세서나 메모리, 디스크 등의 활동 상태와 프로세스나 데몬의 동작 상태를 모니터링하기 위해 별도의 스크립트들을 돌렸다면, 이중 시스템과 관련된 부분들은 하이퍼바이저 또는 클라우드 서비스 공급자가 제공하는 지표를 통해 쉽게 모니터링이 가능해졌다는 뜻이다.
시스템의 동작이 정상이 아닌 경우에는 당연히 그 위에서 동작하는 애플리케이션도 동작하지 않는 경우가 일반적이다. 하지만 시스템이 정상이더라도 애플리케이션은 정상이 아닌 경우가 많다. 아니, 사실 거의 대부분의 장애로 취급되는 사건들은 시스템의 정지에서 발생하는 것이 아니라 애플리케이션이 정상적으로 동작하지 않는 상태에 빠졌기 때문에 문제가 되는 경우가 더 많다고 할 수 있다.
이런 이유로 인해 대부분의 시스템에서는 ‘로그’라는 것을 남긴다. 로그는 보통 시스템 및 시스템 관련 데몬, 그리고 애플리케이션에서 정의한 동작 상태를 시간의 흐름에 따라 사전에 정의된 형태로 파일에 추가하는 형태로 동작한다. 보통 텍스트 형태로 저장되며, 일정 시간, 즉 보통 하루 또는 파일의 크기가 지정한 규모가 되면 ‘로그 로테이트’라는 동작을 통해 압축되고, 새로 파일을 쓰는 형태로 동작한다. 따라서 현재 시스템 또는 애플리케이션이 물고 있는 로그파일에 tail –f를 수행하면 실시간으로 로그가 발생하는 현황을 살펴볼 수 있다.
이런 기법은 단일 시스템인 경우에는 유효하지만, 다시 여러 대의 서버로 동작하는 분산 환경에서는 매번 각각의 시스템에 로그인해서 로그 파일을 확인하는 것이 불가능하거나 매우 불편하다. 따라서 ‘원격 로깅’의 방법을 사용해 로그 파일을 원격 저장소에 주기적으로 저장하거나, 또는 syslog, rsyslog와 같은 방법을 사용해 원격지의 로그 서버에 저장해 동일한 용도의 호스트들이 만들어내는 로그는 한꺼번에 취합해서 볼 수 있는 환경을 사용해왔다.
로그라는 것의 특성이 원래 시스템의 동작 지표 또는 상태를 나타내는 어떠한 값이며, 이 값의 수치가 기준 이하인지 이상인지 여부에 따라 ‘얼럿’을 적용한다. 얼럿이란 시스템 또는 애플리케이션이 시간의 흐름에 따라 생성하는 로그가 관리자가 지정한 수치 범위 내에 있는지를 검사하고, 이 값이 범위를 벗어나는 경우에는 이메일, 문자메시지 등 적절한 방법을 통해 관리자 또는 개발자에게 그 사실을 통보하는 활동을 말한다.
대부분의 사업장에서, 클라우드가 아니더라도 이런 원격 로깅의 방법과 각 로그를 라인별 스트림으로 처리하는 기법은 매우 중요하다. 그리고 이렇게 모여진 로그를 바탕으로 언제 어떤 사건이 발생했는지, 사용자들의 서비스 이용패턴은 어떻게 되는지 등을 이해하는 기본 지표로 삼을 수도 있다. 하지만 대부분의 사업장에서 이런 근간이 되는 원격 로깅조차 적용하지 못하는 경우가 많다. 다양한 이유가 있겠지만, 보통 그 시스템 운영 방법과 관련 프로세스가 이런 식으로 원격 로깅을 취급하기보다는 이전 단일 시스템을 주로 사용하던 시절에 적합한 상태로 운용되기 때문인 것이 대부분이라 할 수 있다.
어쨌든 이렇게 ‘로그를 스트림으로’ 처리하는 것은 매우 중요하며 기본이 되는 것이기는 하지만, 로그 그 자체가 할 수 있는 기능에 대해서는 재고가 필요하다. 즉, 로그는 ‘어떤 사건이 현재 발생했다’와 같은 이벤트를 그 이벤트가 발생한 시간에 따라 차곡차곡 쌓여있는 형태로 운용한다. 예를 들어 ‘몇 시 몇 분 몇 초에 어떤 사용자에 의해 시스템에 재부팅이 발생했다’거나, ‘몇 시 몇 분 몇 초에 DB 연결에 타임아웃이 발생했다’와 같은 형태다.
문제는 이런 ‘사건이 일어난 일련의 흐름으로서의 기입’의 방법은 현재 시스템이 어떤 상태이거나 어떤 문제가 있는지는 알려줄 수 있지만, 대체 ‘왜’ 이런 일이 발생했는지에 대해서는 알려주지 않는다는 것이다. 따라서 대부분의 서비스를 운용하는 사업장에서는 ‘왜’를 설명할 수 있는 로그 발생 패턴을 찾아내고 분석하는 데 시간을 많이 사용한다.
분산 시스템 및 애플리케이션 아키텍처를 사용하는 것 중 하나인 ‘마이크로서비스’의 구현에 도착하게 되면, 그리고 이것이 클라우드상에서 동작하게 되면 이런 원격 로깅의 방법만으로는 충분치 않다. 서비스는 다른 서비스와 강력한 의존성을 갖고 동작하며, 다른 서비스에 문제가 발생한 경우에는 그 서비스를 호출한 서비스에도 장애가 번지는 요인이 될 수 있다. 이것은 다음 회에 설명할 ‘서킷 브레이커’에서 더 자세히 설명되겠지만, 어쨌든 마이크로서비스 구조에서 서비스와 서비스가 서로 어떤 상태로 동작하는지에 대한 모니터링은 매우 중요하다고 할 수 있겠다.
그렇다면 이 중요한 모니터링은 어떻게 수행하는 것이 좋을까? 이에 대한 접근방법으로 ‘분산 추적 시스템’에 대해 살펴보는 것을 추천한다. 이 분산 추적 시스템의 대표 격으로, https://opentracing.io 이 페이지에 접근해서 내용을 살펴보자.
‘오픈 트레이싱’으로 명명돼있지만, 실제 구현체는 ‘집킨(Zipkin)’이라고 불리는 도구다. 이것은 트위터에서 개발한 도구로, 현재 다양한 언어와 프레임워크를 지원한다. 물론 뒤에 소개되듯이 스프링 클라우드에도 포함돼있으며, 스프링 이니셜라이저를 통해 쉽게 사용할 수도 있다.
간략하게 주요 콘셉트를 소개하면 다음과 같다.
▶ 서비스에 유입되는 요청이 처리되는 전체 시간을 추적한다. (trace라 불림)
▶ 전체 서비스에 유입되는 호출이 다시 내부의 마이크로서비스들 간에 서로 넘어가는 이동경로와 각각의 시간을 추적한다. (span이라 불림)
▶ 각각의 요청은 고유의 식별부호를 갖고 동작하며, 이는 스프링 부트에서 사용하는 경우 로그로서 살펴볼 수 있다.
▶ Zipkin을 사용한 추적은 ‘서비스에 유입되는 모든 요청’에 수행하는 것이 아니라, ‘샘플링’을 통해 ‘현재 우리 서비스의 외부 요청 처리 상태’를 파악하는 데 목적을 둔다. 즉, 이 Zipkin용 DB에 DW를 사용하는 등의 형태 같은 게 아니라, 메모리나 간단한 DB를 사용해 그때그때의 상태를 모니터링하는 데 사용한다는 것이다.
예를 들어, 외부 요청을 받는 엣지 서비스가 있고, 이 엣지 서비스는 내부의 적절한 마이크로 서비스에 데이터를 요청하기 전에 캐시 서비스에 먼저 접근해 보는 구현을 사용한다고 하자. 이 경우, 전체 서비스 경험이 느려졌다는 고객의 피드백에 따라 시스템 로그를 각각 살펴본다고 하면 굉장히 많은 도구를 살펴야 할 것이며, 어느 부분이 문제인지 압축하는 것도 매우 쉽지 않을 것이다.
특히 클라우드 기반 서비스를 운용하다 보면 데이터도그(Datadog), 페이지듀티(Pageduty), 뉴렐릭(New Relic), 다이나트레이스(Dynatrace), ELK(엘라스틱서치-로그스태시-키바나)와 같은 다양한 도구들을 복합적으로 사용하게 마련인데, 각각 봐야 하는 지표가 다르고 기본적으로는 로깅의 형태이므로 ‘어떤 이벤트가 발생하고 있다’만 알 수 있지, 그게 ‘왜’ 서비스에 문제가 되는지 알기는 쉽지 않다.
이 경우 Zipkin을 운용하고 있다면 ‘어? 왜 캐시 서비스에서 응답이 느리지?’라는 것을 단번에 알아챌 수 있게 되고, 이를 통해 캐시 서비스의 로그를 참조해보면 ‘아 캐시 미스가 엄청 나고 있구나’를 알 수 있게 되며, 그럼 ‘왜 캐시 미스가 많이 나지?’에 대한 답으로 ‘어젯밤에 신규 유입된 데이터가 많아서 그러네’라는 형태로 문제를 추적해갈 수 있으며, ‘왜’에 대한 답변을 얻을 수 있게 된다. 이 경우 ‘왜 서비스가 느려졌는가’는 일차적으로 ‘캐시 서비스에서 캐시 미스가 많이 발생하고 있기 때문에’라고 거의 바로 설명할 수 있게 된다.

백문이 불여일견이고, 백견이 불여일행이라고 생각한다. 아래 예제를 살펴보자. 전술한 바와 같이 스프링 클라우드에서는 이 Zipkin을 손쉽게 사용할 수 있는 기능성을 제공한다.
먼저 zipkin-service.properties 파일을 demo-config에 추가한다. Config server가 참조하는 코드 저장소에 커밋하고 푸시한다.
| server.port=${PORT:9411} spring.datasource.initialize = false spring.sleuth.enabled = false zipkin.store.type = mem |
아래의 설정을 application.properties에 추가한다. 이 설정은 모든 서비스에 글로벌로 적용된다.
| spring.sleuth.sampler.percentage=1.0 spring.sleuth.log.json.enabled=true |
아래의 순서로 Zipkin 서버를 준비한다.
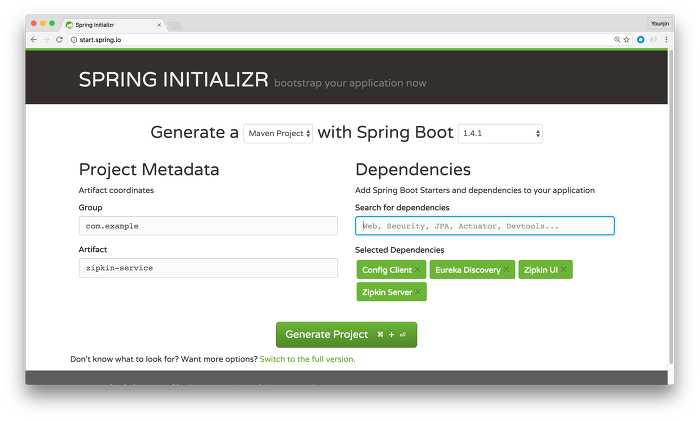
- http://start.spring.io 접속
- artifact에 zipkin-service 이름을 준다.
- dependencies에 Config client, Discovery, Zipkin UI, Zipkin server를 추가하고 프로젝트를 생성해 다운로드받는다.
- IDE를 열어 아래와 같이 애플리케이션에 Zipkin과 유레카(Eureka) 사용을 위한 어노테이션을 추가한다.
spring-cloud-zuul-proxy-demo/zipkin-service/src/main/java/com/example/ZipkinServiceApplication.java
| package com.example; import org.springframework.boot.SpringApplication; @SpringBootApplication public static void main(String[] args) { |
spring-cloud-zuul-proxy-demo/zipkin-service/src/main/resources/bootstrap.properties
- bootstrap.properties를 추가하고 Config server 참조를 위한 설정과 애플리케이션의 이름을 할당한다.
mvn spring-boot:run으로 서버를 구동시켜보자. 아래와 같은 화면이 보인다면 성공.
자, 그러면 이제 각 서비스로부터 실제 리퀘스트 데이터를 모아보기로 한다. 별도로 해줄 것은 없고, helloworld-client와 helloworld-service의 두 모듈의 pom.xml에 아래의 dependancy를 추가한다.
| <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> |
그리고 지난 포스팅에서와 마찬가지로 Config server, Eureka 서비스, 헬로 월드 서버, 헬로 월드 클라이언트, Zipkin 서비스의 순서대로 서비스를 모두 구동한다. 구동이 완료되면, Zuul 을 통해 서비스에 요청을 해보도록 하자. 그리고 Zipkin UI로 진입해 find 버튼을 누르면 아래와 같은 내용이 나타난다.
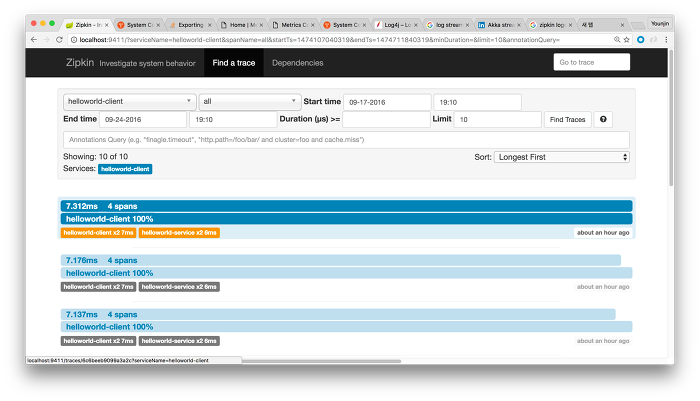
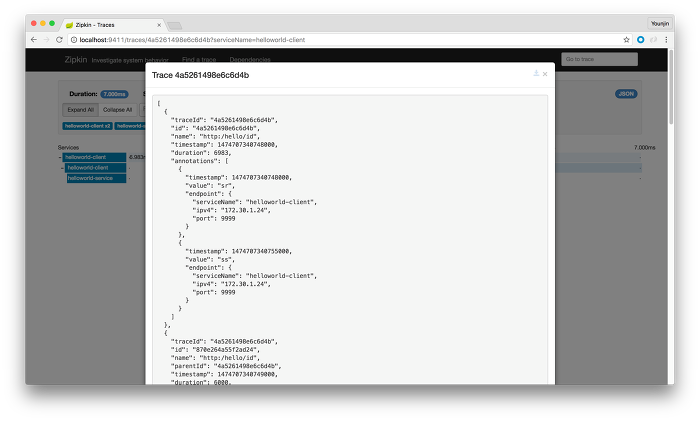
Zipkin에서 보이는 데이터는 크게 두개인데, 하나는 전체 요청을 추적하는 trace와, 다른 하나는 각각의 내부 서비스 간 요청과 응답을 기록하는 span의 두 가지다. 이 데이터를 통해 위와 같이 각 리퀘스트의 처리에 걸리는 시간을 보여준다. 하나를 클릭해보면 아래와 같은 세부정보를 볼 수 있다.
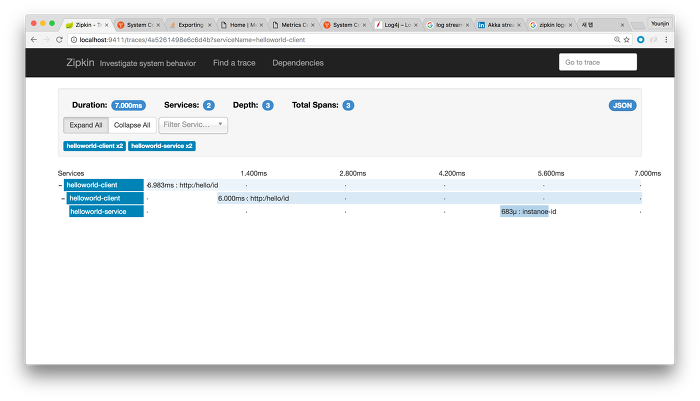
이는 외부로 요청을 받은 시점부터 이 요청을 처리하기 위해 내부 서비스 간 발생한 요청에 대한 처리시간을 보여준다. 헬로 월드 클라이언트는 헬로 월드 서비스로 요청을 포워딩했고 여기에 각각의 처리시간이 나타난다. 그리고 이 전체 요청의 처리에는 7ms가 걸렸음을 확인할 수 있다. 이런 방식으로 내부 서비스가 다수 존재한다면, 예를 들어 캐시 마이크로서비스가 존재하는데 여기서 지연시간이 증가했다면 서비스가 느려진 이유는 캐시 미스가 증가한 것으로 생각할 수 있다. 또는 별도의 DB나 메시지큐와 같은 서비스를 참조하는 마이크로서비스가 있다면 여기서 발생한 지연 역시 확인할 수 있다. 즉, 이 도구는 ‘왜’를 설명하기 위한 것이다.
우측상단의 JSON을 살펴보면 친절하게 JSON으로 만들어진 이 요청에 대한 데이터를 확인할 수 있다.
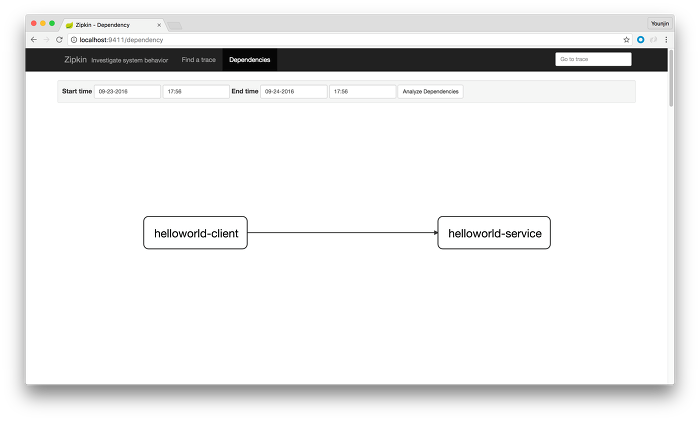
그리고 서비스 간 구조가 복잡하다면 아래의 그림과 같이 서로 어떻게 연관돼있는지 그림도 그려준다.
전술한 바와 같이, 이 도구는 데이터웨어하우징에 넣고 ‘우리 반년 전 상태가 어땠지?’하는 질문에 대한 답변으로 사용하는 도구가 아니다. 즉, 이 데이터는 길어야 하루나 이틀 정도를 두고 ‘현재 우리 서비스의 상태를 빠르게 참조할 수 있는’ 도구로 사용하는 것이 올바르다. 필요하다면 pgSQL(포스트그레스큐엘)과 같은 DB를 사용해 각 요청을 저장할 수도 있겠다. 본 데모에서는 메모리에 저장하는 옵션을 사용했다.
한 가지 더, 모든 요청을 기록할 필요가 없다. 위의 설정 내용을 보면 ‘spring.sleuth.sampler.percentage=1.0’ 이런 설정이 있는데, 이는 데모를 위해 전체 요청을 추적하는 것이다. 이럴 필요 없이 적절한 수량의 요청을 샘플로 사용해 서비스에 불필요한 부하를 주지 않도록 하자. 트위터의 경우에는 1/6,000,000의 비율로 샘플링을 수행한다고 한다. 즉, 6백만 요청당 1개를 Zipkin에 넣고 보는 것이다.
마이크로서비스의 구현에서, 분산 시스템의 구현에서, 그리고 클라우드에 최적화된 애플리케이션의 구현에서 이런 ‘분산 추적 시스템’ 없이 서비스를 운용하는 것은 캄캄한 밤에 헤드라이트도 없이 선글라스를 착용하고 운전하는 것과 같다. 서비스에 어떤 일이 발생하고 있는지 서로에 대한 API 호출 상태를 모니터링함으로써 어떤 API 호출이 어떤 처리의 흐름과 속도 그리고 데이터를 갖고 움직이는지에 대해 투명하게 살펴볼 수 있는, 이런 X레이와 같은 시스템 없이는 지속적으로 발생하는 장애와 문제에 적절히 대응할 수 없을 것으로 생각된다.