



정윤진 피보탈 랩 프린시플 테크놀로지스트
[컴퓨터월드]

| 1. 스프링 부트 <2017.5월호> 2. 스프링 클라우드 Config server <2017.6월호> 3. 스프링 클라우드 Service discovery <이번호> 4. 스프링 클라우드 Zuul 5. 스프링 클라우드 Hystrix 6. 스프링 클라우드 Zipkin |
서비스 디스커버리
클라우드 환경은 동적으로 자원을 할당받고 해제하는 것이 언제든 일어나는 동적인 환경이다. 기존에 고정된 수량의 시스템을 운용하는 데 익숙해진 경우, 이것이 장점이 아닌 단점으로 받아들여지는 경우가 많다. 그렇지만 서버가 부족해 추가하려는 경우나 너무 많이 구매해서 다시 되팔고 싶은 경우를 생각해본다면 클라우드가 제공하는 장점이 매우 중요하다는 것을 알 수 있게 된다.
문제는, 이들을 운용하는 입장에서는 동적으로 변화하는 각종 설정으로 인해 자동화되지 못한 수작업들이 매우 자주, 그리고 반복적으로 발생하고, 이것을 정확하게 처리하지 못한다면 즉각 장애로 연결되는 환경이기 때문에 더욱 민감해질 수 있다. 즉, 고정된 수량의 시스템을 운용할 때 사용하던 기법들이 수량이 동적으로 변경하는 환경에서는 그다지 쓸모가 없거나, 아니면 다른 도구로 대체돼야 한다. 그것들 중 대표적인 것이 바로 DNS를 ‘서비스 디스커버리’라 불리는 방법으로 대체하는 것이다.
서비스 디스커버리에 앞서 DNS 체계에 대해 잠시 생각해보자. 시스템의 입장에서 DNS는 보통 /etc/resolv.conf 에 설정된 네임서버를 참조해 도메인을 IP정보로 바꿔주는 역할을 한다. 문제는 이 레코드가 업데이트되고 참조되는 방식이 1970년대 3600bps 모뎀을 사용하던 시절 이전의 기술이라는 것이다.
열악한 네트워크를 가진 환경일수록 캐시의 사용이 권장된다. 네트워크 너머로 질의가 많이 발생하면 발생할수록 네트워크에 사용되는 비용이 증가하고 응답을 기다리는 동안 사용자경험이 엄청나게 떨어지므로, 더 빠른 응답을 위해 한번 질의 및 응답된 도메인에 대해서는 지정한 TTL 값만큼 연관된 시스템들에서 보존하게 된다. 첫 번째 문제는 바로 이 TTL 자체에 있다.
다른 하나는 동일한 도메인에 새로운 호스트가 등록되거나, 기존에 등록된 호스트를 제거하거나, 변경을 위해 업데이트를 하는 경우엔 Zone file 이라고 불리는 파일을 업데이트하고 프로세스를 재시작해야 하는 문제가 있다. 이전처럼 일 년에 한두 번 정도 서버가 추가되거나 업데이트되는 환경이라면 작업 공지를 하고 네임서버를 업데이트하는 것이 가능하지만, 동일한 동작이 수분 내에 수십 대 이상의 서버에서 발생하는 환경이라면 어떨까.
네임서버는 기본적으로는, 그러니까 기본적으로는 네임서버가 응답하는 도메인과 연결된 호스트들에 대한 헬스체크를 수행하지는 않는다. 즉 관리자가 설정한 호스트의 IP가 동작하는지의 여부와는 관계없이 지정된 응답만을 제공하도록 동작하는 체계라는 것이다.
물론 최근의 네임서버들은 다양한 요구를 반영하기 위해 고도로 발달하고 있는 것은 사실이다. 질의하는 클라이언트의 지리적 위치를 참조해 가까운 지역의 서버를 응답한다든지, 지리적으로 다수의 네임서버를 준비하고 이들을 동일한 IP주소로 묶어 any cast 같은 방법으로 고가용성을 구현한다든지, 그리고 네임서버에 등록된 호스트들이 동작하는지 여부를 주기적으로 헬스체크를 수행하고 문제가 발생한 경우 지정한 fallback 호스트 그룹으로 응답을 우회하거나, TTL을 0에 가깝게 설정해서 변화에 더 빠른 대응을 하도록 한다든지 하는 것들이 바로 그렇다.
네임서버는 인터넷에서는 없어서는 안 될 존재기는 하지만, 그리고 위에 열거한 다양한 기능들과 함께 서비스의 유연성을 높여줄 수 있는 방법들이 존재하기는 하지만, 만약 내부 서비스 간 연동을 위해 네임서버가 필요한 경우라면 어떨까.
우리는 매우 자주, 서비스에 별도의 내부 네임서버를 배치하는 것을 볼 수 있다. 이것은 시스템의 환경 설정을 네임서버로 분리함으로써 변경에 조금 더 유연함을 확보할 수 있다. 하지만 전술했듯, 하루에 수 대, 또는 수십 대, 아니면 수백 수천 대의 호스트가 생겨나고 사라진다면 어떻게 해야 할까. 이를 위해 내부 네임서버를 업데이트하는 스크립트라도 쓰기엔 너무 비효율적이며, 네임서버 관리라는 작업이 애초에 그다지 쉬운 일이 아니다.
따라서 우리는 서비스 내부에 애플리케이션과 애플리케이션이 서로를 찾고, 호스트가 다른 호스트를 찾아내는 동작이 아무리 많이, 그리고 자주 발생하더라도 지원할 수 있는 새로운 방법이 필요하다. 그리고 이 새로운 방법을 지칭하는 단어는 여러 개가 있을 수 있지만, 보통 ‘서비스 디스커버리’를 사용한다.
서비스 디스커버리로 지칭되는 도구들이 수행하는 동작의 핵심은 비교적 간단하다. 클러스터로 구성된 서비스 디스커버리 서버는 클라이언트에 자신이 갖고 있는 호스트의 정보를 전달 및 업데이트해준다. 클라이언트는 기동되는 순간 자신의 네트워크 정보, 구동하고 있는 애플리케이션 정보와 같은 내용을 서비스 디스커버리 서버에 전달한다.
서버는 전달받은 정보를 바탕으로 필요하면 헬스체크를 수행하고, 고가용성을 위해 클러스터링돼있는 다른 서버와 업데이트된 내용을 동기화한다. 디스커버리 클라이언트들은 서버로부터 전달받은 정보를 지정된 시간동안 캐싱을 수행함으로써, 서비스 디스커버리 서버가 동작하지 않는 경우에도 이미 저장된 리스트를 바탕으로 서버 응답 없이도 다른 호스트에 요청하는 것이 가능하다.
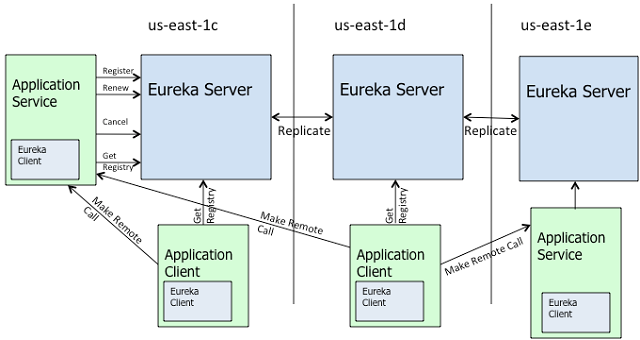
위 그림은 넷플릭스 유레카(Eureka)가 동작하는 방식을 보여준다. 유레카는 서버와 클라이언트로 이뤄져있으며, 클라이언트는 각 애플리케이션 안에서 에이전트처럼 동작한다. 넷플릭스에서는 유레카 서버를 다수의 데이터센터에 구성해 하나의 유레카 서버에 문제가 발생하더라도 전체 서비스에는 이상이 없도록 구성하고 있다. 이는 유레카 클라이언트들이 등록된 호스트의 정보를 받아오는데 하나의 서버만을 사용하도록 구성하지 않고 다수의 서버를 참조하도록 구현됐기 때문에 가능하다.
클라이언트 애플리케이션은 시작되는 순간 자신의 정보를 서버로 등록한다. 이렇게 등록된 신규 클라이언트 정보는 다른 클라이언트들에 전달되고, 이를 통해 다른 클라이언트 애플리케이션들은 ‘서로 통신이 가능한’ 상태가 된다. 이를 통해 클라이언트 애플리케이션에서는 ‘동적으로 변화하는 환경에 대한 정보’를 바탕으로 원하는 호스트 또는 애플리케이션에 직접 연결, 특정 호스트가 응답하지 않는 경우 다른 호스트로 밸런싱 등의 다양한 동작을 처리할 수 있는 능력이 생긴다.
따라서 클라우드에서 동작하는 거의 모든 넷플릭스의 애플리케이션들은 이 유레카 서비스에 자신을 등록하고, 다른 애플리케이션들에서 접근하는데 문제가 없도록 구성하고 있다. 그리고 이 애플리케이션은 마이크로서비스일 뿐만 아니라 캐시, 영구적 데이터저장소 등 매우 다양하다.
서비스 디스커버리의 구성은 클라우드 환경에서 매우 놀라운 장점들을 제공한다. 첫 번째는 높은 가용성이다. 예를 들어 특정 애플리케이션에 문제가 발생한 경우, 동일한 역할을 하는 애플리케이션을 새로운 서버 또는 컨테이너에 적재해 기동한다. 이 애플리케이션이 기동되고 나서 얼마 지나지 않아 다른 애플리케이션들은 신규로 생성된 서버에 요청을 보낼 수 있게 된다. 그리고 기존에 문제가 됐던 서버나 컨테이너는 유레카 서버의 리스트에서 사라진다.
즉, 문제가 되는 리소스를 빠르게 대처하거나 추가 처리량이 필요한 경우 리소스를 빠르게 추가하고, 필요 없을 때 제거하는 동작을 지원하기 때문에 높은 가용성을 제공하는 기본 도구로 사용할 수 있다.
두 번째는 클라이언트가 다른 클라이언트에 ‘애플리케이션 이름’을 통해 코드 내에서 클래스 수준에 필요한 리소스에 접근할 수 있다는 것이다. 대부분의 마이크로서비스 구조에서 하나의 마이크로서비스는 다른 마이크로서비스에 로드밸런서를 통해 접근한다. 하지만 서비스 디스커버리를 사용하게 되면 클라이언트가 직접 다른 클라이언트에 대한 네트워크 정보와 구동하는 애플리케이션에 대한 정보를 갖고 있으며, 이를 바탕으로 중간에 로드밸런서가 없어도 다른 애플리케이션에 접근이 가능하게 되는 것이다.
하루에 수천, 수만 개의 호스트에 변화가 발생하더라도 서비스에서 원하는 방법으로 동일하게 관리되고, 이를 통해 궁극적으로는 어느 호스트가 어디에 위치하는지에 대한 정보를 관리자가 별도 스크립트나 수동으로 관리하지 않아도 된다. 그리고 애플리케이션은 다른 애플리케이션이 동작하는 호스트를 FQDN이 아닌 ‘애플리케이션 이름’으로 접근이 가능하다는 추가적 장점을 제공한다. 이것은 즉, 애플리케이션 코드 내에서 참조돼야 하는 다른 서비스 또는 마이크로서비스를 호출하고자 하는 경우 네임서버에서 사용하는 도메인 이름이 아닌 애플리케이션 이름을 사용한다는 것이다.
스프링 클라우드 프로젝트에서는 이 넷플릭스의 유레카 서버와 클라이언트를 사용할 수 있도록 제공한다. 이 외에도 Consul, Zookeeper 등의 도구를 스프링부트의 방법으로 사용할 수 있다.
Config server를 사용하는 방법을 기억하고 있다면, 유레카 서버도 매우 손쉽게 시작할 수 있다. 유레카 서버 역시 Config server의 클라이언트가 될 수 있다. 아래 순서를 통해 스프링 클라우드의 유레카 서버를 준비할 수 있다.
▶ http://start.spring.io 에 접근한다.
▶ artifact에 discovery-service를 기입한다.
▶ dependencies에 Eureka Server, Config client를 추가하고 Generate project를 눌러 프로젝트를 다운로드한다.
다운로드한 프로젝트를 시작하기 전에, Config server를 준비해야 한다. 이전에 준비한 Config server에서 application.properties 파일의 다음 내용을 변경해주도록 하자. 지금부터는 다수 애플리케이션이 준비되므로 다른 애플리케이션의 설정을 변경하지 않도록 주의하자.
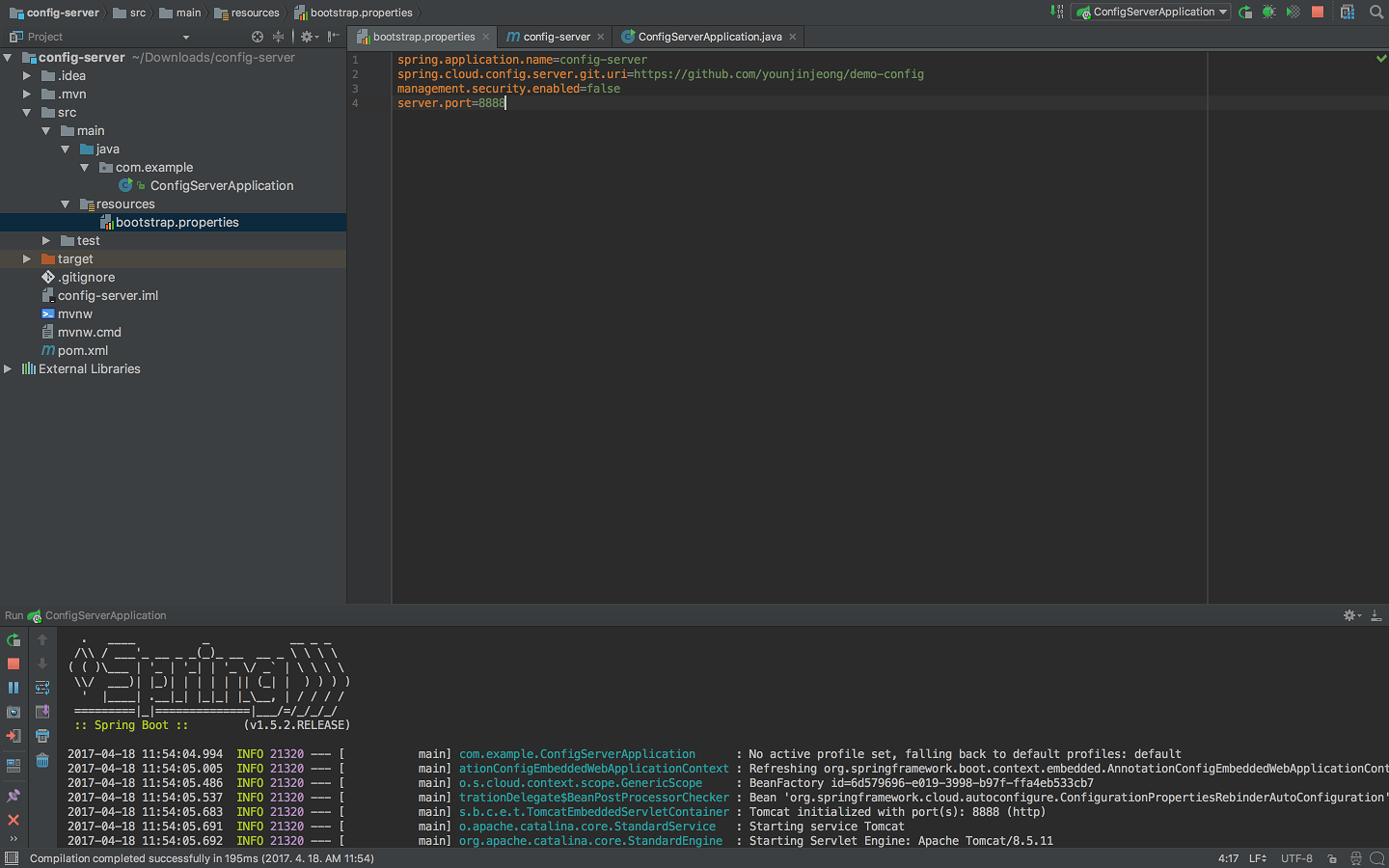
config-server의 application.properties를 bootstrap.properties로 리네임하고, 아래 내용을 넣는다.
| spring.application.name=config-server spring.cloud.config.server.git.uri=https://github.com/younjinjeong/demo-config management.security.enabled=false server.port=8888 |
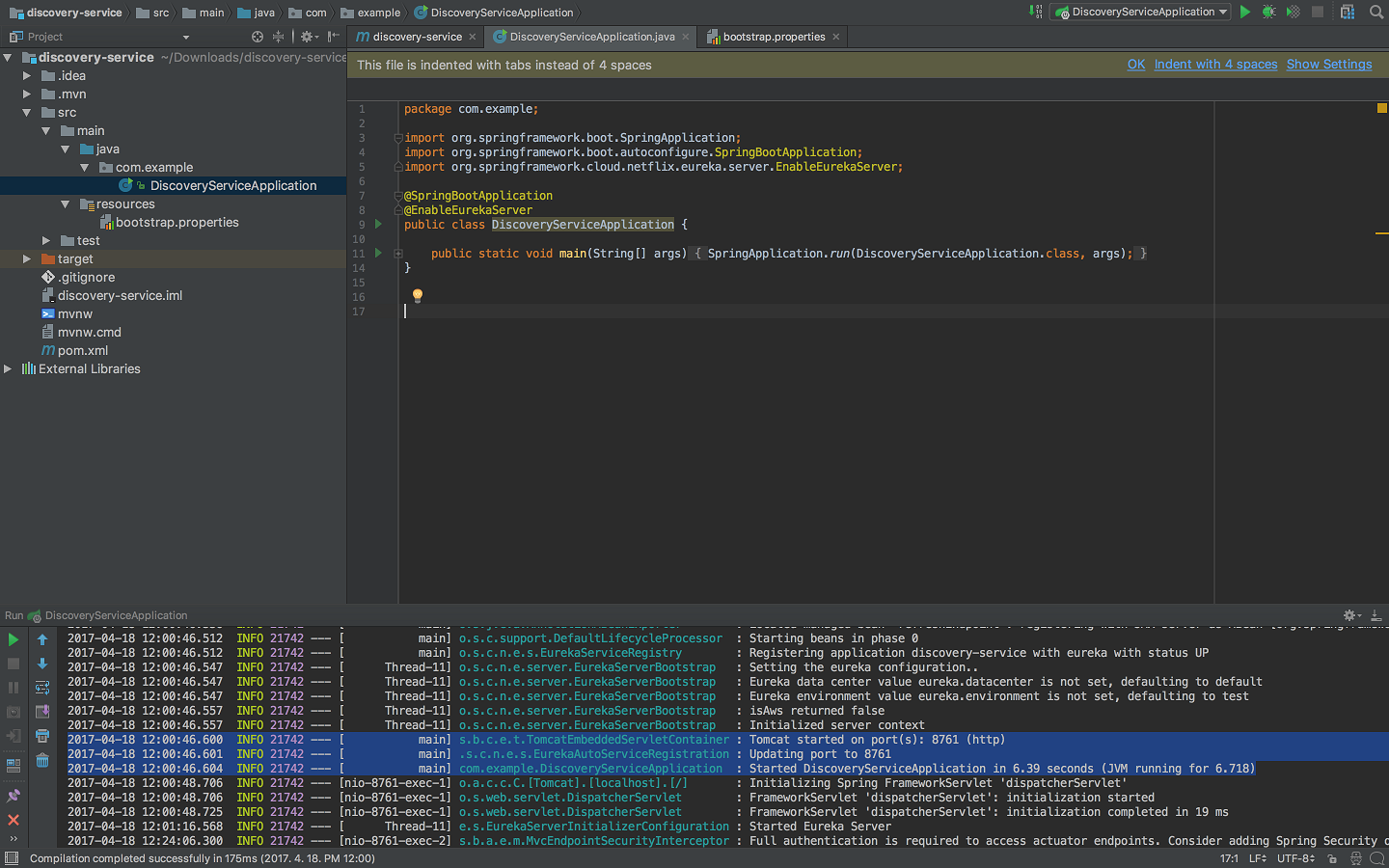
다운로드 받은 유레카 서버 프로젝트의 압축을 해제하고 IDE로 연다. com/example/DiscoveryServiceApplication.java 파일에 @EnableEurekaServer 의 어노테이션을 추가한다.
| package com.example; import org.springframework.boot.SpringApplication; @SpringBootApplication public static void main(String[] args) { |
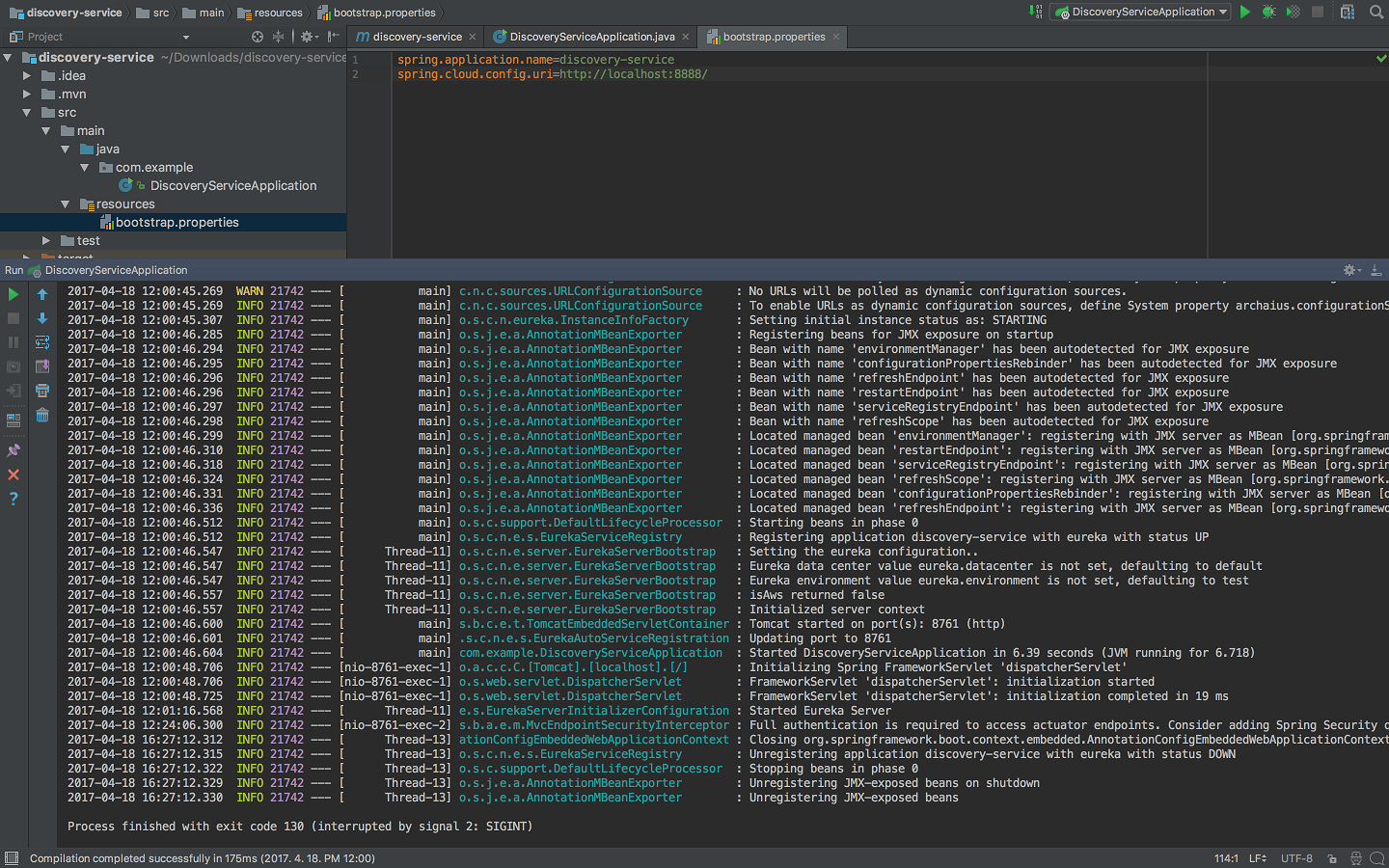
유레카 서버 프로젝트 하위의 application.properties 를 bootstrap.properties 로 바꾸고 아래의 내용을 넣는다.
| spring.application.name=discovery-service spring.cloud.config.uri=http://localhost:8888/ |
저장하고 스프링 부트 애플리케이션을 실행하고, 아래와 같은 메세지를 본다면 성공적으로 유레카 서버가 준비된 것이다.
| 2017-04-18 12:00:46.600 INFO 21742 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8761 (http) 2017-04-18 12:00:46.601 INFO 21742 --- [ main] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 8761 2017-04-18 12:00:46.604 INFO 21742 --- [ main] com.example.DiscoveryServiceApplication : Started DiscoveryServiceApplication in 6.39 seconds (JVM running for 6.718) |
로컬 호스트의 8761 포트에 유레카 서버가 시작됐다. 접속해보도록 하자. 브라우저를 사용하면 된다.
동작하고 있는 유레카 서버의 다양한 설정을 확인할 수 있다. 이들 중 ‘Instance currently registered with Eureka’ 항목에 유레카 서버에 등록된 클라이언트들의 정보가 나타난다. 현재 유레카 서버의 설정은 스스로가 시작되면서 등록하도록 했기에, 유레카 서버의 spring.application.name이 DISCOVERY-SERVICE로 등록된 것을 볼 수 있다.
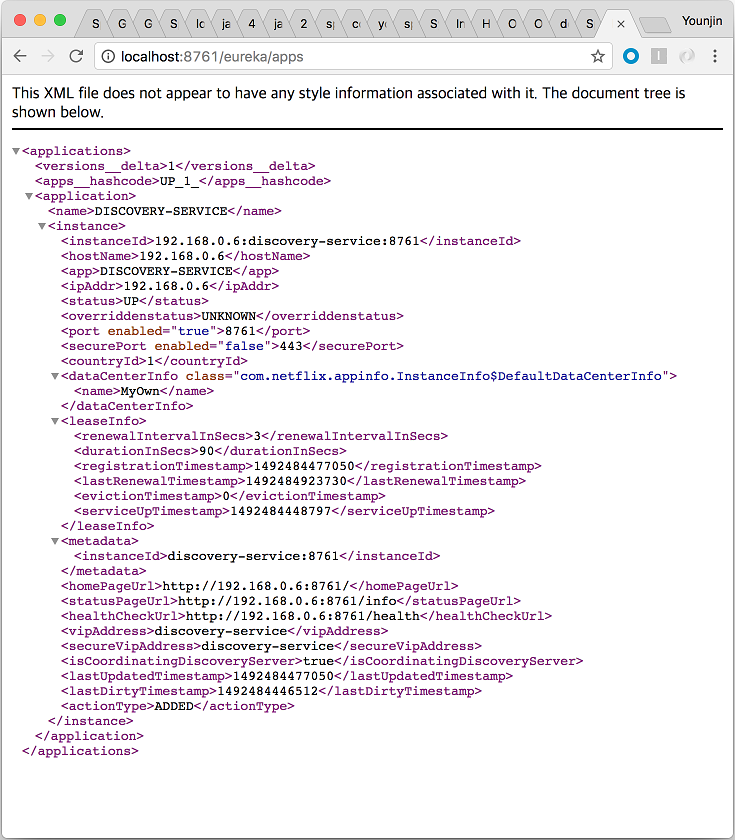
클라이언트를 시작하기에 앞서, 유레카 서버가 제공하는 정보를 조금 더 살펴보도록 하자. http://localhost:8761/eureka/apps 주소로 접근해보도록 한다. 네트워크 정보뿐만 아니라 현재 애플리케이션의 상태, 동작하는 포트, 애플리케이션의 이름 등 매우 다양한 정보를 확인할 수 있다. 유레카 시스템 체계는 이를테면 동적으로 공유되는 전화번호부 같은 것으로 이해하면 쉽다. 주소와 거주 상태가 자주 변경되는 세상에서 필요한 전화번호부다.
유레카 서버를 설정했다면, 이제 클라이언트를 연결해볼 차례다. 지난번 Config server를 설정하며 준비했던 simple-client를 재사용하기로 하자. simple-client를 스프링 이니셜라이저(start.spring.io)를 통해 생성할 때 Discovery client (Eureka client)를 추가하지 않았다면 의존성을 추가해줄 필요가 있다. 아래의 의존성 설정을 simple-client 프로젝트의 pom.xml 파일에 추가하도록 하자.
| <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> </dependency> |
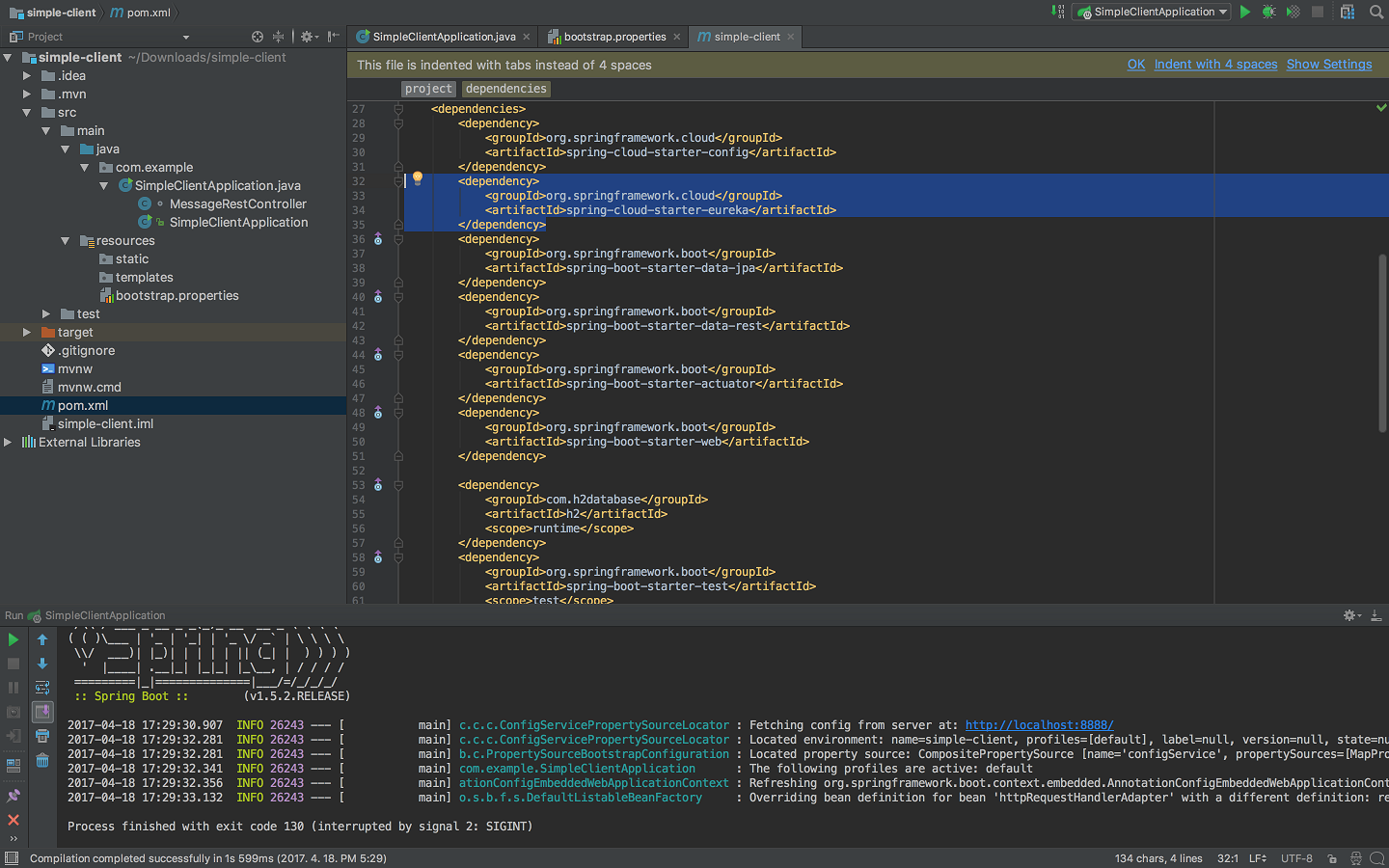
이후 simple-client 프로젝트의 com/example/SimpleClientApplication.java 파일에 유레카 클라이언트를 사용하기 위한 어노테이션을 아래와 같이 추가하자.
| package com.example; import org.springframework.beans.factory.annotation.Value; @SpringBootApplication public static void main(String[] args) { } @RefreshScope @Value("${message}") @RequestMapping("/msg") |
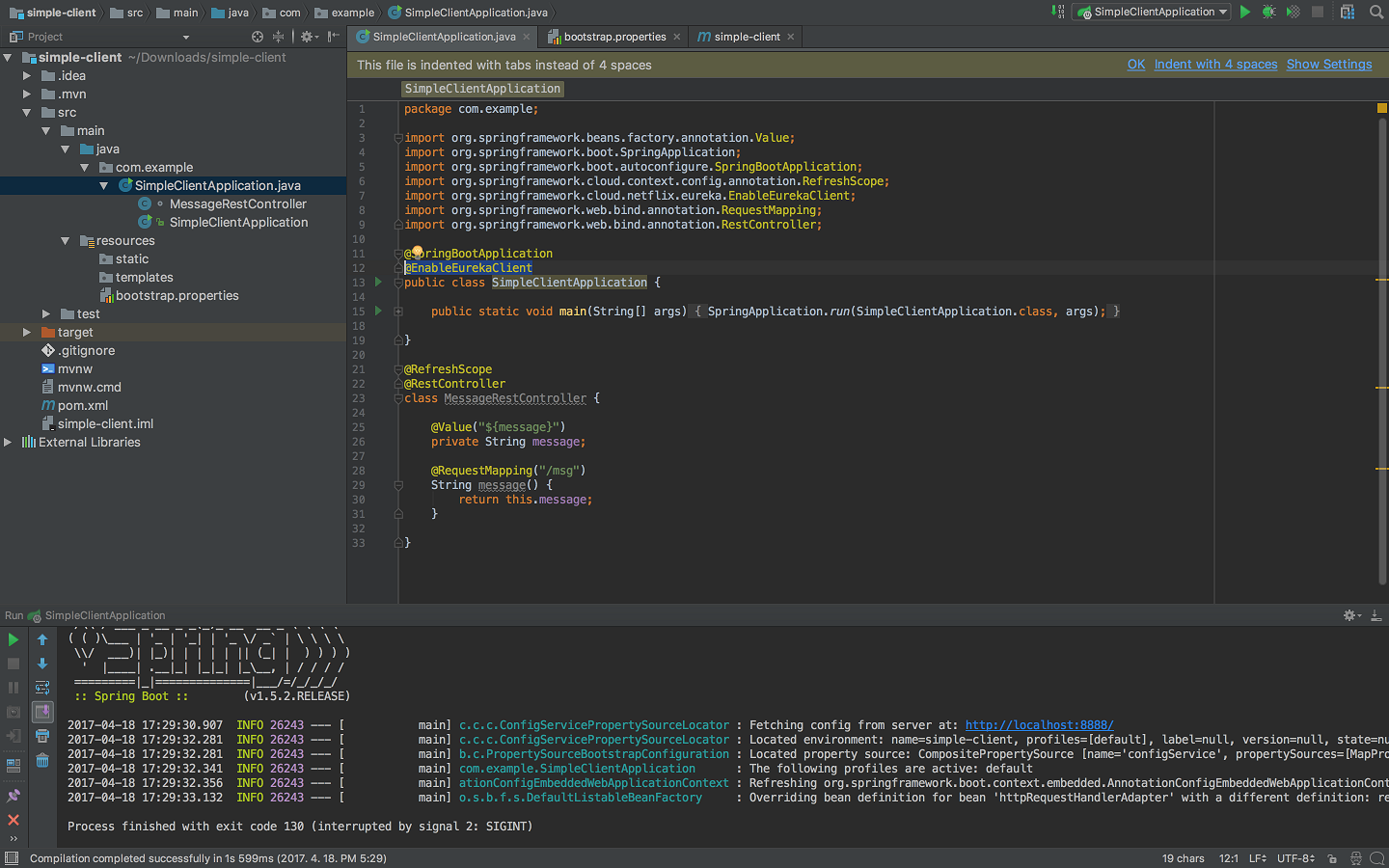
모든 준비가 끝났다. simple-client 스프링부트 애플리케이션을 구동해보도록 하자. 문제없이 구동됐다면 다시 유레카 서버 http://localhost:8761 에 접속해보자.
SIMPLE-CLIENT 서비스가 정상적으로 등록됐다. 아래 커맨드를 통해 더 많은 simple-client 서비스를 시작하고 종료해보도록 하자.
| $ cd simple-client $ PORT=9989 java -jar target/simple-client-0.0.1-SNAPSHOT.jar |
다시 유레카 서버에 접근해 보면 simple-client 애플리케이션의 status에 숫자가 변경되고, 애플리케이션의 링크가 추가된 것을 확인할 수 있을 것이다. 다시 애플리케이션을 종료하면 사라진다.
다음으로 넘어가기 전에 지금까지의 동작에 대해 정리해보도록 하자. 유레카 서버와 클라이언트의 설정은 모두 Config server를 통해 전달받고 있다. 먼저 config server가 참조하는 github의 설정이 담긴 코드 저장소의 위치는 여기(https://github.com/younjinjeong/demo-config)다. 링크에 담겨진 파일들을 살펴보면, application.properties 하나와 각 스프링부트 애플리케이션 이름으로 할당된 애플리케이션 설정 파일들이 존재한다.
스프링 부트 애플리케이션은 시작되면 먼저 빌드 시 참조한 bootstrap.properties(또는 yml)을 참조한다. 여기에는 보통 spring.application.name 또는 config server 위치와 같이 자주 변하지 않는 정보를 넣는다. 그렇게 시작된 애플리케이션은 지정된 config server로부터 설정을 내려 받는다.
이때 application.properties에 담긴 내용은 모든 애플리케이션이 공통적으로 참조하며, 여기에 자신의 애플리케이션 이름으로 지정된 설정 파일을 가져와 병합한다. 이때 더 높은 우선권을 가지는 설정은 애플리케이션 이름으로 특화된 설정 파일에 담긴 것이다.
본 내용에서는 소개되지 않았지만, 환경별로 프로파일을 지정해 적용하는 것도 가능하다. 이때는 스프링 부트 애플리케이션이 시작하는 서버나 컨테이너에 시스템 환경 변수에 profile 이 담긴 내용을 전달하는 방식으로 동작할 수 있다. 역시 코드의 변경 없이 각 환경에 종속적인 설정을 적용하는 매우 우아한 방법이라고 할 수 있겠다.
demo-config 코드 저장소의 내용에서 현재 적용되는 설정은 application.properties, discovery-service.properties, 그리고 simple-client.properties의 설정이라고 할 수 있다. 이것들은 시간이 되면 천천히 살펴봐도 무방하다.
Config server와 유레카 모두 더 높은 수준으로 가용성을 높이거나 인증 등을 통하는 방법으로 정보를 참조할 서비스를 제한할 수 있다. 이에 대한 자세한 설명은 각각 스프링 클라우드 서비스에 대한 매뉴얼을 참조하는 것을 권고한다.
이번에 살펴본 스프링부트, 스프링 클라우드의 Config server와 유레카 서버/클라이언트는 클라우드 기반 애플리케이션을 구현에 필요한 기본적인 접근을 수행하기에 매우 좋은 도구다. 마이크로서비스를 염두에 두는 경우, 각각의 마이크로서비스를 스프링부트를 통해 개발하고, 이들에 필요한 설정이나 다른 애플리케이션에 대한 정보를 공유하는 방법을 스프링 클라우드를 통해 사용할 수 있다.
스프링 클라우드에는 이 두 가지 외에도 API Gateway, Distributed tracking, 서킷 브레이커, 마이크로 프락시, 클라이언트 로드 밸런싱등 매우 다양한 도구가 포함돼있다. 이들은 클라우드 환경에서 동작중인 애플리케이션에 대한 가시성 확보, 다운타임 없이 클라이언트의 요청 흐름을 수정, 그리고 특정 서비스에 문제가 발생했을 때 전체 서비스에 문제가 확장되지 않도록 하는 등의 방법을 포함한다.
클라우드에서 애플리케이션을 개발하고 운영할 때는 '언제 어디서든 문제가 발생할 수 있다' 는 생각을 기본으로 갖고 있어야 한다. 인프라를 담당하는 엔지니어뿐만 아니라 애플리케이션을 개발하는 엔지니어도 “유레카 서버가 동작하지 않는 상태에서 캐싱된 클라이언트 리스트의 서버 중 하나가 스케일 인 돼 없어진 경우에는 어떻게 처리할 수 있지?"와 같은 식의 접근이 필요할 것이다.
그리고 이런 방식으로 클라우드 서비스 개발 방향에 접근하는 것은 궁극적으로 서비스를 변화와 장애에 더욱 더 강하게 만들고, 이를 바탕으로 업데이트가 더욱 빠른 주기를 가질 수 있게 돼 시장이 원하는 속도로 서비스를 개선할 수 있을 것이며, 이는 경쟁력 있는 서비스를 만들어 내는데 초석이 될 것이다.
다음회에는 서비스 디스커버리를 바탕으로 백엔드의 마이크로 서비스들에 트래픽을 전달하는 ‘Zuul’에 대해 살펴보도록 하자.