



아주대학교 소프트웨어학과 윤대균 교수

<약력>
(현) 아주대학교 소프트웨어학과 교수, 넷마블 사외이사
(전) 삼성전자 전무
(전) NHN 테크놀로지 대표이사
(전) NHN 전략지원본부장
[아이티데일리] 들어가며
AI가 전 세계 산업 지형을 재편하면서, 그 기반이 되는 AI 데이터센터는 단순한 기술 인프라를 넘어 국가 경쟁력과 경제 패권을 좌우하는 핵심 자산으로 부상하고 있다.
AI 최강국의 위치를 사수하기 위해 민간 주도의 막대한 투자를 집행하고 있는 미국, 우수한 인력과 정부의 적극적인 지원을 바탕으로 바짝 뒤쫓으며 양대 AI 강국 반열에 오른 중국, 그리고 그 뒤를 이어 유럽, 중동, 동아시아의 주요 국가가 그야말로 AI 경쟁력 확보를 위한 ‘전쟁’을 벌이고 있다.
AI 인프라의 핵심 컴퓨팅 자원인 그래픽처리장치(GPU)와 같은 가속기 칩 설계/제조 기술, 수천, 수만, 수십만 개의 칩을 하나의 컴퓨터처럼 연결하기 위한 네트워크 기술, 이를 구동하기 위한 전력망 구축 기술, 지속 가능성을 위한 신재생 에너지 기술, 폭발적인 전력 밀도에서도 안정적인 구동을 위한 냉각/공조 기술 등 기존 데이터센터 생태계보다 훨씬 복잡한 기술적 난제들을 해결하는 것이 전쟁에서 살아남기 위한 첫 번째 넘어야 할 산이다.
결국 이 전쟁은 이런 기술과 관련 자원을 확보해 이를 효율적으로 운용하기 위한 AI 인프라를 ‘어떻게’ 구축하는가에서 승패가 좌우된다. 이에 모든 나라가 각각 그 나라의 상황에 최적화된 전략을 구사하고 있다.
미국은 거대 데이터센터를 기반으로 클라우드 서비스를 제공하는, 이른바 하이퍼스케일러(Hyperscaler)들의 막대한 자본력을 바탕으로 대규모 투자를 감행하고 있으며, 재생에너지뿐만 아니라 원자력까지 모든 수단을 동원하는 ‘all-of-the-above’ 에너지 확보 전략에 주력하고 있다.1
중국은 ‘동수서산(东数西算)’이라는 국가 주도의 중앙집권적 정책을 통해 에너지 자원이 풍부한 서부 지역에 데이터센터를 집중시키는 한편, 미국의 반도체 수출 통제에 맞서 기술 자립을 위해 총력전을 벌이고 있다. 중동의 산유국들은 막대한 오일 머니와 저렴한 에너지 비용을 무기로 글로벌 테크 기업과 파트너십을 통해 단숨에 AI 인프라 허브로 도약하려는 시도를 하고 있다.
엄격한 규제와 지속 가능성을 최우선 가치로 내세우며 규모의 경쟁보다는 ‘신뢰할 수 있는 AI’ 전략을 추구하던 유럽 각국도 이젠 AI 리더십 확보를 위한 전력투구를 선언하고 있다.
우리나라도 새 정부 들어 AI 3대 강국에 들기 위한 마스터 플랜을 수립 중이며 이의 핵심 아젠다 중 하나가 AI 인프라 구축이다. 여기에는 GPU 확보뿐만 아니라 자체 칩 개발, 차세대 에너지망 구축, 수도권 집중을 해소하는 지방 특화 발전형 전략이 포함될 것이다.
AI 인프라는 포괄적인 AI 데이터센터 구축 전략과 맞물려 있다. 성공적으로 AI 인프라를 갖추기 위해서는 우선 AI 데이터센터가 기존 데이터센터와 차별화되는 기술 동향을 분석하고 이를 바탕으로 실행해야 할 국가 차원의 전략이 필요하다. 이에 본 고에서는 우선 AI 데이터센터 동향을 기술적 관점에서 돌아보고자 한다. 추후 주요 국가 및 지역의 추진 현황에 대해서도 정리할 계획이다.
AI 데이터센터를 성공적으로 구축하는 데 필요한 주요 기술은 크게 다음과 같이 분류해 볼 수 있다.
○ AI 반도체: AI 데이터센터의 성능을 좌우하는 핵심 요소로 학습 및 추론에서의 성능과 전력 효율 모두를 최적화해야 하는 숙제를 안고 있다.
○ 냉각 및 공조: 일반 CPU 대비 전력 소모와 발열이 압도적으로 많은 AI 가속기의 안정적인 운영을 위해 보다 혁신적인 냉각(공조) 기술이 필요하다.
○ 네트워크 기술: 고도의 병렬성으로 학습 및 추론을 실행하는 대형 AI 모델의 경우 AI 가속기를 매우 높은 대역폭과 최저 지연으로 연결하는 네트워크 기술이 필수다.
○ 에너지 인프라: 많은 전력을 소모하는 AI 데이터센터를 안정적으로 구동하기 위한 발전, 송전, 재생에너지 활용 등 모든 에너지 인프라 기술을 총동원해야 한다.
AI 반도체
데이터센터를 성공적으로 구축하는 데 가장 중요한 것은 AI 칩 확보다. 현재 이 시장은 사실상 엔비디아가 휘어잡고 있다. 향후 추론용 AI 칩은 좀 더 다변화될 수 있을 것으로 예상하기도 한다. 학습의 경우 고도로 집적된 클러스터에서 더 좋은 성능을 낼 수 있기에 근거리 네트워크 기술도 매우 중요하다. 이 분야에서도 엔비디아의 기술 우위는 두드러진다. 당분간 엔비디아의 독주를 막기는 어려운 이유이기도 하다. 그럼에도 AI 인프라 구축을 위해서는 다양한 선택지를 가지고 최적의 설계가 바탕이 돼야 한다. 이에 AI 반도체 시장을 우선 살펴볼 필요가 있다.
AI 반도체 시장은 엔비디아 H100과 차세대 블랙웰이 주도하는 가운데 경쟁업체들이 추격을 가속화하고 있는 양상이다. 1조 8천억 개의 매개변수로 구성된 모델을 학습하기 위해 H100 GPU 8,000개와 15메가와트의 전력이 필요했었다면, B200의 경우 2,000개의 GPU와 4메가와트 수준의 전력이 필요하다는 것이 블랙웰을 발표할 당시 엔비디아의 주장이다.2
데이터센터에서 얼마나 많은 GPU가 있어야 하는가에 대한 답은 xAI의 공격적인 데이터센터 구축 전략에서 찾아볼 수 있다. 일론 머스크는 xAI가 5년 안에 5,000만 개의 H100에 해당하는 클러스터를 구축하겠다고 공언했다.

요즘 많이 사용하는 FP16 정밀도로 계산해 보면 H100 1개가 텐서 코어 전용 연산 시 약 2페타플롭스3, 따라서 5천만 개는 무려 1억 페타플롭스 즉 100제타플롭스라는 상상을 초월하는 연산량이 된다.4 H100 5천만 개 GPU 구동하는 데에만 약 35GW가 필요하며, 공조 및 기타 시스템 유지를 위해 필요한 것까지 하면 아무리 적게 잡아도 50GW가 필요하다. 1GW 용량의 데이터센터라고 하더라도 50개가 필요한 용량이다.5
엔비디아의 최신 칩인 B200으로 하면 GPU 수는 반 이상, 전력 수요는 3분의 1 정도 줄어들 것이라고 하는데 이 역시 막대한 전력과 엄청난 규모의 데이터센터가 필요하다.6
그래픽 프로세서에서 엔비디아와 경쟁하는 AMD는 MI350X와 MI355X를 2025년 하반기 실전에 배치할 계획이다. 현재 주력 버전인 MI300X는 엔비디아의 H100보다 더 많은 고대역폭 메모리를 포함하고 있지만 성능은 H100과 유사하거나 좀 더 높은 수준이며, 올해 하반기 본격 출시될 MI355X의 경우 약 2배의 연산 성능을 가질 것으로 알려져 있다. MI300X, MI355X가 각각 엔비디아의 H100, B200을 타겟으로 하고 있는 것으로 보인다. AMD의 경우 소프트웨어 개발 플랫폼인 ROCm(Radeon Open Compute platform)로 엔비디아의 CUDA에 대항하고 있다.
인텔은 가우디 시리즈로 AI 칩시장에서 경쟁력을 갖추려는 노력을 하고 있다. 2024년 발표된 가우디3가 엔비디아의 블랙웰 시리즈를 겨냥한 것으로 보이며, GPT-3 175B 대규모 언어 모델의 경우 H100보다 학습 시간이 40% 더 빠르고, 라마2의 70억 및 80억 매개변수 버전에서는 더 나은 결과를 낼 것으로 예상한다는 자료도 찾을 수 있다.7
구글은 자체 제작한 AI 전용 칩인 TPU 시리즈를 클라우드 및 내부 AI 워크로드에 활용 중이며, 7세대 TPU인 아이언우드(Ironwood)도 발표했다. 아이언우드는 9,216개 칩으로 확장 가능하며, 42.5 엑사플롭스(Exaflops)의 연산 성능을 제공한다고 한다. 한편, 5세대 대비 월등한 연산 능력과 에너지 효율을 제공하는 6세대 트릴리움 TPU도 제미나이, 젬마 등 다양한 모델의 학습과 추론에 사용되고 있다.
중국 화웨이는 미국의 반도체 제재에 맞서 자체 개발한 어센드(Ascend) AI 칩으로 엔비디아에 대항하고 있으며, 현재 주력 제품인 어센드 910B와 차세대 910C의 대량 출하를 목표로 하고 있다. 어센드 910C는 엔비디아 H100 대비 약 60% 정도의 추론 성능을 가지고 있다고 한다.8 만일 일정 수준의 수율에 이르러 양산이 본격화되면 중국 내 많은 데이터센터에서 이를 기반으로 한 본격적인 서비스가 가능하게 될 것이다.
국내에서는 하이닉스가 고대역폭 메모리(HBM) 반도체를 엔비디아에 주력으로 공급하는 것 이외에 본격적인 상용 수준의 AI 반도체는 거의 전무한 수준이다. AI 전용 칩을 개발하는 퓨리오사 AI, 리벨리온, 딥엑스와 같은 주목받는 스타트업이 있으나, 이들의 제품이 본격적으로 데이터센터에서 활용되기까지는 아직 시간이 필요해 보인다.
딥엑스와 같이 전력 효율에 초점을 두고 온디바이스 또는 엣지용 반도체를 주목표를 삼는 경우 시장 진출이 좀 더 용이할 수 있을 것이다. 데이터센터향 추론용 NPU를 개발하는 퓨리오사와 리벨리온 같은 경우 현재 주요 데이터센터와 LLM을 보유하고 있는 기업과의 협업을 통한 검증 작업이 한창이며 곧 데이터센터에 상용 탑재될 수 있을 것으로 기대를 모으고 있다.
당분간은 엔비디아 GPU를 대량 확보할 수 있는가가 성공적인 AI 데이터센터 구축에서 가장 큰 요인이 될 것이다. 하지만 특정 산업에 국한된 소규모 데이터센터의 경우 앞서 언급한 다른 경쟁사를 통한 다양한 옵션도 충분히 고려할 만하다. 특히 국내 AI 반도체 산업 육성을 위해서는 이들 스타트업 기술을 신속하게 상용 수준으로 끌어올리기 위한 정책적인 지원도 필요할 것이다.
냉각/공조
AI 데이터센터 성장의 가장 큰 물리적 제약은 폭증하는 전력 소비와 그로 인해 발생하는 막대한 열을 어떻게 처리하느냐이다. 특히 전력 밀도가 기하급수적으로 증가하면서 기존의 공기 기반 냉각 방식은 한계에 부딪혔고, 따라서 좀 더 복잡하고 많은 투자가 필요한 액체 냉각 기술로의 패러다임 전환이 필요하다.
전통적인 데이터센터는 랙당 10~15kW의 전력을 소비하도록 설계됐지만, 고성능 GPU로 가득 찬 AI 서버는 랙당 100kW 가까운 전력이 필요하다. 현재 기존 데이터센터에 GPU를 배치할 경우 빈 공간을 많이 둘 수밖에 없는 이유이며, 이로 인한 상면 효율이 매우 떨어질 수밖에 없다. 엔비디아의 차세대 루빈(Rubin) 플랫폼은 랙당 600kW에 이른다고도 한다.9 이러한 전력 밀도의 폭발적인 증가는 기존 냉각 방식으로는 감당할 수 없는 수준의 열을 발생할 수밖에 없다.
데이터센터 서버실 전체에 찬 공기를 순환시켜 열을 식히는 기존의 공랭식은 현재 일반적인 랙당 전력 밀도인 약 20kW가 한계라고 한다. 따라서 고성능 GPU로 인해 높아진 전력 밀도로 발생하는 열을 식히기 위해서는 뭔가 다른 방식이 필요하다. 이 중 하나가 발열이 심한 GPU와 CPU 부품에 직접 냉각판을 부착해 내부로 냉각수를 순환시켜 열을 직접 흡수하는 방식이다. 전통적인 슈퍼컴퓨터나 고용량 데스크톱 PC에서도 활용하는 방식이며 엔비디아 HGX B200과 같은 고밀도 시스템에서도 활용된다.
최근 주목받고 있는 것은 액침 냉각(Immersion Cooling) 방식이다. 서버 전체를 전기가 통하지 않는 비전도성 액체에 담가 냉각한다. 이는 최고의 냉각 효율을 제공하며, 데이터센터 전체의 에너지 소비를 획기적으로 줄일 수 있다. 흔히 데이터센터의 효율을 PUE(Power Usage Effectiveness)라고 얘기하는데 데이터센터 전체 소모된 전력을 IT 자원에 소모된 전력으로 나눈 값이다. 보통 1.4 이하면 효율이 좋다고 하는데, 냉각에 사용되는 에너지 소비를 대폭 줄임으로써 PUE 역시 떨어뜨릴 수 있다. 특히 액침 냉각이 폐열 활용이나 에너지 회수 측면에서 효율적이어서 이를 활용한 지역 냉난방이나 혹은 더 나아가 추가 발전에도 활용될 수 있다.
고성능 네트워크
대규모 AI 모델 학습은 수천 개의 GPU가 병렬로 연산하면서 서로 매초 수 TB의 데이터를 주고받는 전형적인 분산 처리이다. 특히 AI 데이터센터에서는 외부와 연결하는 프론트엔드 네트워크보다 내부 노드를 연결하는 백엔드 네트워크가 결정적으로 성능을 좌우한다.
현재 백엔드 네트워크에서는 엔비디아가 인수한 멜라녹스(Mellanox)의 인피니밴드(Infiniband) 기술이 사실상 업계 표준이다. 400Gbps의 대역폭과 마이크로 초 단위의 저지연을 제공한다. 엔비디아는 GPU 내부 통신을 위해 NVLink도 발전시켰고, GPU 여러 개를 한 노드에서 묶는 NVSwitch 기술도 활용하고 있다.
AI 슈퍼컴퓨터 클러스터를 구현하는 AI 데이터센터와 일반 데이터센터와의 가장 큰 차이가 네트워크 장비이기도 하다. 초대형 데이터센터의 경우 그 규모가 수백 미터에서 수 킬로미터에 이를 수 있다. AI 클러스터의 규모 확장성을 최대한 활용하려면 초고속, 초저지연 네트워크가 이 정도 규모에서도 꽤 높은 수준으로 동작해야 한다. 그만큼 네트워크 스위치 반도체 및 광섬유 기술도 뒷받침이 돼야 한다. 이에 네트워크의 중요성이 커지면서, 통신 장비 예산도 AI 데이터센터 투자에서 큰 비중을 차지하게 된다. 아마존·메타 등 하이퍼스케일러들은 AI 전용 스위치에 수십억 달러를 투자하며, 아리스타(Arista), 시스코(Cisco) 등 네트워크 업체들의 AI 특수가 일어나고 있다.
최근에는 이더넷 진영에서도 AI 워크로드에 최적화된 초저지연 이더넷(Ultra Ethernet) 표준을 추진하며 인피니밴드 독점을 견제하고 있다. 구글, 메타 등 일부 기업은 벌써부터 고속 이더넷 스위치를 AI 클러스터에 도입하기 시작했고, 마이크로소프트도 내년부터 인피니밴드 대신 차세대 이더넷으로 전환할 계획을 밝히고 있다.10 요컨대 데이터센터 설계자들은 전 노드 간 1:1 풀매시 연결에 준하는 효율을 달성하기 위해 최신 스위치, NIC, 광케이블 기술을 적극 채택하고 있으며, 이는 AI 데이터센터를 초고속 통신으로 엮인 하나의 슈퍼컴퓨터처럼 만드는 노력의 일환이라 볼 수 있다.
에너지 인프라
앞서도 언급했지만 이미 수백 메가와트급의 데이터센터가 가동 중이며 향후 기가와트급의 데이터센터도 등장할 것이다. 국내에서도 실현 가능성에 많은 의문이 제기됐던 3기가와트급의 데이터센터 건립계획이 발표된 적도 있다.11
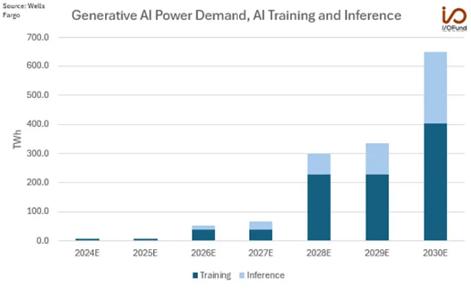
대형 AI 데이터센터는 중소 도시 하나의 전력 사용량에 맞먹는 전기를 소모할 수 있으므로 국가 전력망에도 상당한 부담이 될 수 있다. 전력 수요에 대한 다양한 예측이 나오고 있는 가운데 한 예를 들면, 작년 여름 엔비디아 블랙웰 발표 당시 웰스파고는 AI 전력 수요가 2024년 8 TWh(테라와트시)에서 2026년까지 550% 급증해 52 TWh, 2030년까지는 1,150% 증가한 652 TWh에 이를 것으로 예상했다. 이는 2024년 전망치 대비 무려 8,050% 증가한 수치이다.
AI 학습 전력 수요가 2026년 40 TWh, 2030년 402 TWh로 이 수요의 대부분을 차지할 것으로 예상되며, 추론 전력 수요는 2030년대 말에 급증할 것으로 예상했다. 여기서 652 TWh로 예상되는 전력 수요는 현재 미국 전체 전력 수요의 16%가 넘는다고 한다.12
에너지 효율 최적화와 친환경 전력 사용은 AI 데이터센터 전략의 중요 축이다. 이에 대부분의 하이퍼스케일 기업들은 재생에너지 100% 사용을 선언하고, 태양광·풍력 발전과 전력구매계약(PPA)을 맺어 데이터센터 운영 전력을 조달할 계획을 세운 바 있다.
예를 들어 구글, 마이크로소프트, 메타 등은 각자 2030년 또는 그 이전에 탄소 무배출 데이터센터 목표를 내걸고, 신규 센터는 가능한 한 현지 재생에너지로만 운영되도록 투자하고 있다. 유럽연합(EU)도 2021년 ‘기후 중립형 데이터센터 협약(Climate Neutral Data Centre Pact)’을 통해 2030년까지 PUE 1.3 이하, 100% 친환경 전력 사용을 권고했다. PUE(Power Usage Effectiveness)는 데이터센터 효율 지표로, 이상적인 값 1.0에 가깝게 낮출수록 비-IT 부하(냉각 등) 에너지 낭비가 적다는 뜻이다.
AI 워크로드는 특성상 전력망에 불안정 요인으로 작용할 수 있다. AI 학습은 수천 개의 GPU가 순식간에 유휴 상태에서 최대 부하 상태로 전환하는 과정이 반복될 수 있고, 이는 전력 수요에 급격하고 큰 규모의 변동을 유발한다. 이러한 ‘스파이크성’ 수요를 수십 년 된 낡은 전력망이 감당하기 어려울 경우 반복되는 고장이나 대규모 정전을 야기할 수 있다.
이처럼 막대한 수요와 그리드 불안정성이 결합해 나타날 수 있는 위험을 예방하기 위해서는 데이터센터가 단순히 전기를 공급받는 수동적 소비자 입장이 아니라 전반적인 전력 시스템의 설계와 운영에 적극적으로 참여하는 ‘파트너’가 돼야 한다. 예를 들면 다음과 같은 구체적인 실행계획이 필요하다.
▷ 발전에 대한 직접 투자: 새로운 재생에너지 프로젝트에 대한 장기 전력 구매 계획(PPA)을 체결하거나, 나아가 마이크로소프트가 재가동되는 원자력 발전소의 전체 생산 전력을 구매하기로 한 계약처럼 발전소에 직접 자금을 지원한다.13
▷ 전력원 인근 배치: 송전 손실을 최소화하고 공급 안정성을 확보하기 위해 재생에너지 단지나 원자력 발전소 바로 옆에 데이터센터를 건설한다.
▷ 자체 전력 인프라 구축: 고전압 변전소, 효율적인 장거리 송전을 위한 초고압 직류송전(HVDC) 라인, 그리고 서비스 연속성을 보장하기 위한 라이브 스와핑(Live-swapping) 기능이 포함된 무정전 전원 공급 장치(UPS) 시스템에 투자한다.
AI 수요로 인해 전 세계 전력망 현대화는 매우 시급한 문제가 됐다. 수십 년 된 낡은 전력망이 이미 재생에너지 확충 및 전기차 보급을 통해 한계를 드러내고 있었는데, 여기에 AI 데이터센터의 폭발적인 수요가 더해지면서 전력 회사와 정부는 향후 20~30년에 걸쳐 해결하려 했던 그리드 현대화 과제를 당장 해결해야 하는 상황에 놓였다.
아무리 막대한 자본을 가지고 있는 하이퍼스케일러라고 하더라도 정부와 전력 유틸리티 회사와의 공조 없이 단독으로 전력 수급 문제를 해결할 수는 없다. 앞서 언급한 ‘파트너’로서 전력 시스템 설계에 동참하는 것이 중요하다. 즉, 민간 AI 기업의 긴급한 수요와 이들의 자본을 에너지 인프라 현대화를 위한 촉진제로 활용해 궁극적으로는 공공의 이익을 추구하는 방향으로 에너지 인프라가 진화해야 할 것이다.
맺으며
AI 데이터센터 경쟁은 기술, 자본, 에너지가 결합된 복합적인 패권 다툼이다. 미래의 승자는 단순히 가장 많은 가속 칩을 보유하고 또한 가장 큰 데이터센터를 짓는 국가가 아니라, 폭발적인 AI 컴퓨팅 수요를 지속 가능하고 안정적인 에너지 및 인프라와 가장 효과적으로 결합시키는 전략을 실행할 수 있는 국가가 될 것이다.
이를 위해서는 데이터센터 구축을 위해 필요한 핵심 기술 요소를 정확히 이해하고 이에 기반한 중장기 전략이 필요하다. 이러한 중장기 전략은 수요 기업 혼자 해결할 수 없다. 국가 전반에 걸친 인프라 전략이 필수적이며 따라서 범국가적인 데이터센터 구축 전략과 궤를 같이해야 한다.
<각주>
① Atlantic Council, “To win the AI race, the US needs an all-of-the-above energy strategy”, Mar 21, 2025
② The Verge, “Nvidia reveals Blackwell B200 GPU, the ‘world’s most powerful chip’ for AI”, Mar, 2024
③ 페타: 10의 15제곱, 엑사: 10의 18제곱, 제타: 10의 21제곱.
④ 일부 기사에서 50엑사플롭스 연산이라고 한 것은 잘못된 계산으로 보인다. https://www.aitimes.com/news/articleView.html?idxno=200920
⑤ 현재 운영 중인 데이터센터 중에는 650MW가 가장 큰 것으로 알려져 있다. https://brightlio.com/largest-data-centers-in-the-world/
⑥ FP8 또는 FP4 정밀도로 낮추면 B200의 효율이 훨씬 더 좋아진다고 한다.
⑦ https://spectrum.ieee.org/intel-gaudi-3?utm_source=chatgpt.com
⑧ https://www.huaweicentral.com/huawei-plans-to-develop-100000-910c-and-300000-910b-ai-chips-this-year/
⑨ https://www.datacenterdynamics.com/en/news/nvidias-rubin-ultra-nvl576-rack-expected-to-be-600kw-coming-second-half-of-2027/
⑩ https://techblog.comsoc.org/2025/01/04/networking-chips-and-modules-for-ai-data-centers-infiniband-ultra-ethernet-optical-connections/
⑪ AI Times, “전남에 세계 최대 3GW AI 데이터센터 건설…”, 2/19, 2025 https://www.aitimes.com/news/articleView.html?idxno=168098
⑫ Forbes, “AI Power Consumption: Rapidly Becoming Mission-Critical”, June 20, 2024
⑬ Reuters, “Microsoft deal propels Three Mile Island restart, with key permits still needed”, Sep 20, 2024