



IBM, 다양한 데이터 전략 위한 폭넓은 서비스 지원
[아이티데일리] 오늘날 전 세계 모든 기업들은 데이터 중심적인(data driven) 비즈니스 프로세스를 구축하는 것을 중요한 목표로 삼고 있다. 업계를 가리지 않고 폭발적으로 증가하고 있는 데이터들을 효과적으로 수집하고 이를 비즈니스에 활용하고자 하는 것은 모든 기업들이 당면하고 있는 목표다.
유통업계의 경우 고객을 이해하고 더 다양한 서비스를 제공하기 위해 온라인·오프라인을 가리지 않고 민첩하게 고객 데이터를 확보해 분석하고 있으며, 금융업계에서는 사기 행위 등을 탐지하고 막아내기 위해 실시간으로 수많은 데이터들을 확인해야만 한다.
이러한 문제는 비단 새롭게 생성되는 데이터에 대해서만 일어나는 것은 아니다. 오랜 역사를 가지고 있는 기업들은 그동안 축적된 데이터에서 새로운 인사이트를 찾을 수는 없는지 끊임없이 탐구하고 있으며, 그동안 역량 부족으로 분석할 수 없었던 데이터들을 활용하기 위해 머신러닝이나 인공지능(AI)과 같은 최신 기술을 도입하고 있다.
이에 본지에서는 글로벌 DBMS 벤더들을 중심으로 효과적인 데이터 저장에 대한 취재를 진행해, 데이터 중심적인 비즈니스 프로세스 구축을 지원하기 위한 벤더들의 전략에 대해 들어봤다.
< IBM >
고객의 모든 데이터 전략을 지원하는 폭넓은 서비스 제공
오늘날 고객이 요구하는 데이터 관리 전략을 지원할 수 없는 벤더는 시장에서 경쟁력을 가질 수 없다. 과거에는 기업마다 데이터 관리 전략에 큰 차이가 나지 않았고 한정된 제품 중 최적의 제품을 선택해 사용하는 것이 자연스러웠다. 하지만 지금은 100개의 기업이 100개의 데이터 관리 전략을 가지고 있다.
만약 고객이 머신러닝과 AI와 같은 최신 기술의 도입을 준비해야 하는데 이를 지원할 수 없다고 한다거나, 적절한 데이터 거버넌스 체계를 필요로 하는데 서드파티 제품을 사용하라고 한다면 그 벤더는 신뢰를 얻을 수 없을 것이다. 따라서 벤더는 고객의 모든 데이터 관리 전략에 대응할 수 있는 폭넓은 역량을 가져야 한다.
IBM은 고객이 가지고 있는 모든 데이터 관리 전략에 자사의 솔루션과 기술을 매칭할 수 있다고 설명했다. 최근 IBM이 포커싱하고 있는 AI의 경우, 고객이 원하는 AI를 단계별로 구축하기 위한 사다리(The Ladder to AI)를 제공한다. 고객의 궁극적인 목표인 AI를 달성하기 위해서는 사다리의 각 단계를 해결해야 하며, 각각의 단계에도 당연히 많은 데이터들이 요구된다. 따라서 고객과 IBM은 어떤 데이터 거버넌스를 수립하고 어디서 데이터를 수집하며, 머신러닝을 포함한 다양한 기술·서비스에 어떻게 데이터를 연결할 것인지를 함께 고민해야 한다.
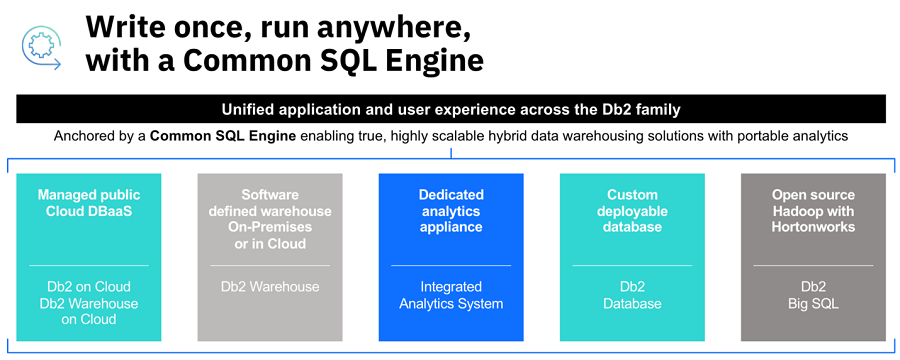
이를 위해서는 다양한 데이터들을 저장할 수 있는 다양한 데이터 스토어가 필요하며, 서로 다른 장소에 저장된 데이터들을 손쉽게 확인하고 접근할 수 있도록 돕는 단일한 접점이 마련돼야 한다. 이러한 측면에서 IBM은 오랫동안 다양한 종류의 DBMS를 서비스해온 경험을 갖추고 있으며, 복수의 클라우드 상에 존재하는 다양한 DBMS들을 손쉽게 접근하고 사용할 수 있는 ‘커먼 SQL(Common SQL)’을 개발해 사용하고 있다. 고객은 IBM의 컨설팅을 통해 최선의 데이터 저장소를 도입하고, 자사의 서비스·애플리케이션이 멀티 클라우드 상의 데이터에 문제없이 접근할 수 있도록 ‘커먼 SQL’을 사용할 수 있다.
 <인터뷰> 모든 데이터를 통합하고 관리하는 것은 불가능하다. 오늘날 전 세계에 그런 기술을 갖추고 있는 기업은 없다. 한두 개의 벤더가 기술과 시장을 장악하고 표준화된 데이터 저장 방법론을 제시하지 않는 이상 앞으로도 불가능할 것이다. 오픈소스 진영에서만 해도 일 년에 몇 개씩 데이터 스토어를 내놓고 있다. IBM은 오픈소스 진영에 많은 기여를 하고 있고 관련 기술을 확보하고 있지만, 그렇다고 하더라도 모든 것을 해낼 수는 없다. 하지만 달리 얘기하자면, 그럴 필요도 없다. 다양한 비즈니스 과정에서 생산되는 데이터들은 각각 적절한 저장소가 다르게 마련이다. 클라우드에 저장해야 하는 데이터가 있는가 하면 온프레미스 인프라가 가장 잘 맞는 데이터도 있다. OLTP냐 OLAP냐, 분석 용도냐 아카이빙용이냐, 정형이냐 비정형이냐. 이런 특징들을 무시하고 모두 단일한 DBMS에 몰아넣으면 제대로 된 퍼포먼스를 낼 수가 없다. 오늘날 산업별로 다양한 비즈니스 요건들을 모두 커버할 수 있는 단 하나의 DBMS가 있는가? 단언컨대 없다. IBM 또한 ‘DB2’를 포함해 많은 DBMS들을 가지고 있다. 관리나 사용성 측면에서 이들은 모두 다른 특색을 갖고 있으며, 사용자는 자신의 비즈니스 목적에 따라 최적의 DBMS를 선택해서 사용하게 될 것이다. 기업은 필연적으로 다양한 데이터 저장소를 가지게 된다. 과거에는 얼마나 많은 데이터와 종류를 단일한 DBMS로 지원할까가 중요한 고민거리였다. 지금은 멀티 클라우드, 멀티 플레이스 등이 당연해지면서 데이터를 어디에 어떻게 저장할 것인지가 중요해졌다. 오늘날 기업들의 고민은 데이터를 어디에 저장하고 어떻게 싱글뷰를 제공할 것인가, 이기종DB에 대한 관리는 어떻게 할 것인가 하는 것들이다. 이러한 고민에 대한 해답으로 IBM이 강조하는 것은 ‘Anywhere’다. 이것은 ‘커먼 SQL’이라는 이름으로 구체화됐다. 멀티 플레이스, 멀티 플레이스, 멀티 DBMS에서 발생하는 기술 요소들을 통합하기 위해 ‘커먼 SQL 엔진’을 만들고, 모든 DBMS에 접근하고 기술이나 표준을 ‘커먼 SQL’로 통합해서 다같이 볼 수 있도록 한다. 다양한 DBMS 제품들이 가지고 있는 특징을 추출해 모든 데이터 타입을 통합하고 관리할 수 있도록 구성한다. 이는 ‘커먼 SQL’에 쿼리를 날리면 각 DBMS에 맞게 파싱해서 전달하는 것이 아니라, 마이크로서비스 레벨에서 각 저장소에 들어가는 기술들을 통합하는 과정이다. ‘커먼 SQL’을 통해 멀티 플레이스에 있는 데이터들을 손쉽게 연계할 수 있게 연계할 수 있게 되면, 기존의 데이터 기반 솔루션들의 한계도 자연스럽게 사라지게 된다. 이에 따라 IBM은 우리가 가지고 있는 데이터 분석 솔루션들을 마이크로서비스화해서 쿠버네티스나 오픈시프트와 같은 가상화 플랫폼에 올릴 수 있도록 개발 중이다. 이러한 측면에서는 레드햇과의 시너지도 기대할 수 있을 것이다. |