



정윤진 피보탈 프린시플 테크놀로지스트
[컴퓨터월드]

클라우드 네이티브라는 단어가 최근 많이 사용되고 있다. 클라우드 네이티브는, 어떤 서비스가 클라우드가 제공하는 장점을 사용할 수 있도록 클라우드에 최적화 되어 있는가를 의미한다. 그렇다면 클라우드 네이티브가 아닌 것은 무엇일까? 바로 클라우드의 장점을 사용하기 힘든 형태로 구성된 애플리케이션 서비스를 말한다.
IT 시장에서는 언제나 매우 다양한 제품이 치열하게 경쟁하고 있다. 기존의 대형 클라우드 서비스 공급자들간의 서비스 경쟁은 사용자를 즐겁게 한다. 다양한 기능을 하는 클라우드 서비스들을 보다 저렴한 가격으로 이용할 수 있기 때문이다. 하지만 클라우드 서비스 공급자가 제공해 주는 서비스가 항상 최선인 것은 아니다. 애플리케이션에는 다양한 기능이 필요하고, 경우에 따라서는 별도의 라이브러리나 서드파티 서비스의 사용이 필요할 수도 있다.
애플리케이션이 클라우드에 적합하게 만들어져 있는가는 매우 중요하다. 종전에 이미 동작하는 애플리케이션을 컨테이너화 하거나, 아마존 웹 서비스의 EC2 서비스에 구동한다고 해서 클라우드의 장점을 누릴 수 없다는 것이다.
가장 대표적인 예가 웹 애플리케이션 서버(WAS)에 종속적인 기능을 애플리케이션에서 사용하도록 구성한 경우다. 만약 WAS에서 제공하는 세션 클러스터링과 같은 기능을 사용하고 있다면, WAS 서버의 숫자가 늘어나거나 줄어들 때 이 세션 클러스터링을 관리할 수 없는 상태라면 이것은 클라우드의 신축성이 제공하는 장점을 사용할 수 없는 상태라고 볼 수 있다.
이제 막 클라우드 기반으로 서비스를 개발하려고 하거나 기존 서비스를 이전하려고 한다면 ‘과연 우리 애플리케이션이 클라우드의 장점을 누릴 수 있도록 구성되었는가’의 질문을 해 보는 것이 좋다. 클라우드의 장점을 누릴 수 있도록 구성되었는지 아닌지의 지표로 다양한 클라우드 벤더에서 제공하는 복잡한 메트릭이 있지만 가장 단순한 질문을 해보면 쉽게 알 수 있다. 바로, “우리 서비스는 오토스케일링이 되는가”다.
오토스케일링이 제공하는 장점에 대해서는 다음의 아마존 웹 서비스의 링크에 매우 잘 설명돼있다.
https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/auto-scaling-benefits.html
여기서 간략하게 오토스케일링에 대해 생각해 보도록 하자.
오토스케일링이란
기본적으로 오토스케일링이란 서비스의 상태에 따라 동일한 역할을 하는 서버 또는 컨테이너와 같은 리소스의 숫자를 늘리거나 줄이는 것을 의미한다. 예를 들어 더 많은 트래픽이 유입되면, 이 처리를 위해 웹 서버를 자동으로 더 늘리는 것이다. 물리 서버를 관리하는 데이터센터에서 서버를 추가하고 빼는 동작은 매우 오래 걸리고 힘이 드는 일이지만, 클라우드 환경에서는 원본 이미지를 바탕으로 쉽게 새로운 서버를 복제해 낼 수 있다. 서버를 늘리고 줄이는 데는 다양한 메트릭을 사용할 수 있다. 트래픽이나 응답 지연시간, 프로세서의 사용률, 메모리 사용률 등 매우 다양한 지표를 사용할 수 있다.
사용하는 형태는 보통 사용할 서버 또는 컨테이너와 같은 리소스의 최소값과 최대값을 지정하고, 이 숫자를 변경할 이벤트를 만들어서 적용한다. 예를 들어 밸런서를 통해 응답되는 지연시간이 500ms 이상이 되면 몇 대의 서버를 더 늘려라 하는 것이다.
이것이 오토스케일링의 기본이지만, 숨겨진 속성이 하나 있다. 오토스케일링이 적용된 경우, 매 순간 ‘유지해야 하는 리소스 숫자’가 있다. 예를 들어 최소 10개에서 최대 100개까지 컨테이너 숫자를 트래픽 지연시간에 따라 조정하도록 되어 있으며, 어떤 순간에 50개의 컨테이너가 적정 수량이라고 지정되었다면 이 50개를 반드시 유지해야 하는 것이 오토스케일링의 의무인 것이다. 따라서 어떤 문제로 인해 40개로 숫자가 줄었다면, 없어진 10개를 가장 빨리 다시 채워야 하는 것이 중요하다.
이것은 바로 서버나 컨테이너의 장애에 대응해서 자동으로 치유하는 내결함성을 오토스케일링이 제공한다고 할 수 있다. 뿐만 아니라 오토스케일링은 대부분 다양한 데이터센터에 동일한 숫자의 서버나 컨테이너 배포를 조절한다. 두개의 데이터센터를 사용한다면 각각 25대의 컨테이너를 유지할 수 있도록 한다. 이때 하나의 데이터센터 전체에 문제가 발생하면 50개의 수량은 온전한 데이터 센터에서 동작할 수 있도록 해 주는 것이다.
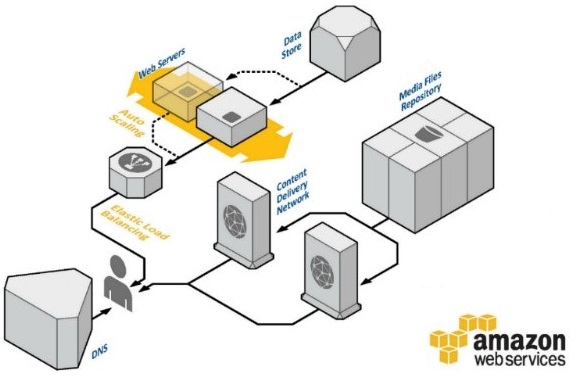
우리 서비스가 오토스케일링이 되는가의 대단히 쉬운 질문에 대해 “가능하다”로 답변하기 위해서는 분산 시스템에 대한 이해를 바탕으로 애플리케이션을 설계해야 한다. 아래의 링크에서 설명하는 Embarrassingly Parallel(https://en.wikipedia.org/wiki/Embarrassingly_parallel)의 경우, 즉 애플리케이션에 대해 한두 개의 변경 처리 또는 변경이 없어도 즉시 수평 확장 구조를 사용할 수 있는 형태가 아니라면 일단 오토스케일링을 적용할 수 없으며, 따라서 클라우드 서비스가 제공하는 장점을 그대로 사용하는 것은 불가하다는 결론을 내려 볼 수 있다.
그럼에도 불구하고 모든 게 다 되는 것처럼 말하는 엔지니어나 벤더는 주의해야 할 필요가 있겠다. 오라클의 관계형 데이터베이스를 컨테이너에 넣으면 오토스케일링 된다는 말과 동일하기 때문이다.
넷플릭스가 적용한 마이크로 서비스
그렇다면 클라우드의 장점을 최대한 누리는 형태는 무엇인가. 바로 넷플릭스를 통해 세상에 널리 알려진 마이크로 서비스라고 볼 수 있다. 마이크로 서비스의 핵심은 서비스를 그저 작게 나누는 데만 있지 않다. 자주 받는 질문 중의 하나는 ‘도대체 마이크로 서비스를 어떻게 나누어야 하느냐’는 것이다.
왜 이런 질문을 하는가 생각해 보면, 바로 기존의 애플리케이션을 몇 개로 나눌 수 있다는 기준이 있어야 그 작업에 필요한 인력과 시간을 산정할 수 있기 때문이다. 지극히 SI적인 접근이며, 이런 접근 방식으로 성공하는 마이크로 서비스란 없다.
이보다 중요한 것은 마이크로 서비스가 만들어지고 사라지는 각 애플리케이션의 생명주기동안 이를 지원하기 위한 생태계라고 볼 수 있다. 이 생태계에는 트래픽을 나누어 낼 수 있고, 마이크로 서비스로 구성된 각 애플리케이션이 클라우드가 제공하는 장점을 최대한 사용할 수 있는 형태로 만들어져 동작할 수 있도록 지원해야 한다.

국내 대부분의 서비스 애플리케이션들, 특히 자바로 만들어진 대부분의 서비스들은 웹 애플리케이션 서버에 매우 종속적이다. JBoss나 제우스, 웹 스피어, 웹 로직과 같은 웹 애플리케이션 서버들은 이전의 데이터 센터에서 고정된 숫자의 서버로 운용하는 환경에는 아마 적합한 선택이었을지도 모른다.
하지만 오토스케일링을 기반으로 클라우드 환경에서 동적으로 서버가 만들어지고 사라지는 환경에서는 이 고대의 웹 애플리케이션 서버들이 제공하는 기능이, 아니 존재 자체가 오토스케일링에 방해가 되는 경우가 많다. 뿐만 아니라 이미 인프라와 코드에 종속된 코드를 바탕으로 더 나은 환경을 제공하기 보다는 자사의 도구에 고객이 종속되었다는 점을 바탕으로 다른 제품들을 함께 판매한다. 운영체제에 종속되고, 가상화에 종속되고, 웹 애플리케이션 서버에 종속된 코드를 사용하므로, 그 환경을 그대로 다시 컨테이너로 묶어서 운영하면 좋은 것처럼 포장해서 다시 동일한 회사의 제품을 구매한다.
컨테이너의 시대에 쿠버네티스가 각광받는 이유는 간단하다. 예전에 구동하던 애플리케이션을 그대로 컨테이너에 넣어서 구동할 수 있다고 믿기 때문이다. 애플리케이션에 대한 변경은 어렵다고 생각하며, 코드가 동작하는 환경만 변경하는 것으로 효과를 볼 수 있는 것처럼 생각한다.
결론부터 말하면, 애플리케이션에 대한 변경 없이 기존 서비스를 그대로 클라우드로 옮기는 것은 클라우드 서비스가 제공하는 장점을 사용할 수 있는 환경이 아니다. 따라서 클라우드 서비스에 최적화된 형태로 애플리케이션과 서비스를 만들어 가다 보면, 자연스럽게 마이크로 서비스 구조를 힌트로 사용하게 될 것이다.
마이크로 서비스 구조에서는 각 개별 애플리케이션이 독자적으로 확장하고 축소한다. 다른 서비스 변경 및 다운, 업데이트 등으로 인해 발생하는 영향을 줄이기 위해 자신만의 데이터 저장소를 가지며, 서킷 브레이커와 같은 패턴을 사용해서 서비스를 보호한다. 또한 다른 서비스에서 발생하는 영향뿐만 아니라, 내가 개발하는 마이크로 서비스가 장애에 어떻게 반응하는지 테스트한다. 테스트뿐만 아니라 장애를 스스로 극복할 수 있는 방법을 사용해서 애플리케이션을 디자인한다. 그리고 이렇게 만들어진 마이크로 서비스는 이 애플리케이션을 만든 사람들에 의해서 직접 운영된다.
개발자가 운영을 수행하는 것, 즉 만든 사람이 운영하고 문제가 발생하면 직접 고치는 것이다. 아마도 개발자에게 이런 방식은 매우 두려운 공포의 대상일지도 모르겠다. 하지만 각 개발팀의 ‘셀프서비스’에 대한 적용 없이 마이크로 서비스를 구현하는 것은 아마 힘든 일일 것이다.
넷플릭스는 여기에 '풀 사이클 개발자'라는 개념을 도입한다. 다음의 링크에서 설명을 찾아볼 수 있다.
https://medium.com/netflix-techblog/full-cycle-developers-at-netflix-a08c31f83249
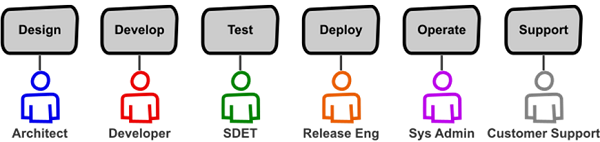
풀사이클 개발자로 데브옵스 실천
하여 넷플릭스는 풀 사이클 개발자라는 개념을 통해 자사만의 데브옵스 실천 방법을 만들어 낸다. 하나의 애플리케이션 생명 주기를 그것을 만드는 팀이 모두 처리하도록 하는 것이다. 즉 하나의 마이크로 서비스팀 개발자는 디자인부터 배포, 운영, 지원까지 처리할 수 있어야 한다.
그런데 여기서 중요한 것이 있다. 개발자의 경우 디자인부터 테스트까지는 익숙하겠지만, 배포와 운영 그리고 고장시 지원은 매우 어려울 수 있다. 풀 사이클 개발자를 지원하기 위해, 넷플릭스는 플랫폼 팀을 만들었다. 플랫폼 팀의 고객은 바로 각 마이크로 서비스를 개발하는 개발자들이다. 이들의 역할은 소프트웨어 생명 주기 전체를 개발자가 직접 처리할 수 있도록 필요한 도구를 만들어 제공하는 것이다.

이렇게 작성된 코드는 스피내커(Spinnaker)와 같이 플랫폼 엔지니어링에서 만들어진 도구를 통해 빌드되고 테스트 되어, 클라우드 환경에 배포된다. 넷플릭스의 개발자들은 큰 고민이 없이도 자신의 애플리케이션을 가상 머신 환경에 배포할지, 컨테이너 환경에 배포할지 선택하기만 하면 나머지는 시스템이 알아서 처리해 주는, 즉 플랫폼 엔지니어링의 도움을 받는다. 넷플릭스의 또 다른 엔지니어링 블로그 포스팅인 ‘How We Build Code at Netflix( https://medium.com/netflix-techblog/how-we-build-code-at-netflix-c5d9bd727f15)’를 살펴보면 이들이 작업하는 방식을 참고해 볼 수 있다.
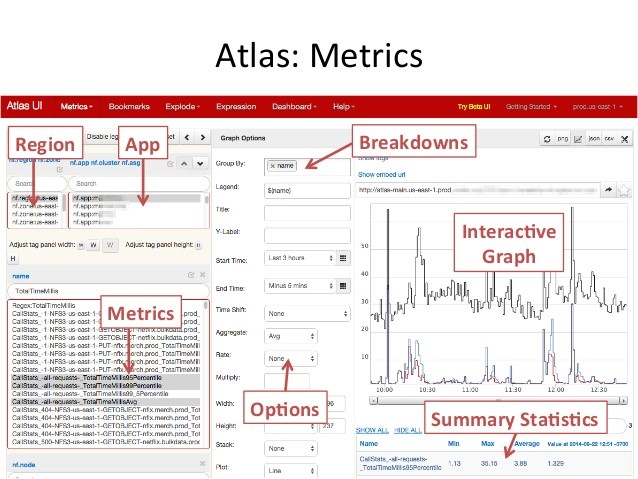
하나의 시나리오를 예로 들어보자. 애플리케이션의 운영을 위해서는 상태 정보를 일레스틱 서치와 같은 원격 시스템으로 보내고, 필요에 따라 내 애플리케이션의 동작 상태에 대해 자세한 정보를 얻을 필요가 있다. ‘오퍼레이션 인텔리전스’라고 불리는 이 처리를 위해 넷플릭스는 플랫폼 엔지니어링에 의해 Spectator/Servo와 Atlas 시스템을 각 마이크로 서비스 팀에 제공한다.
Spectator나 Servo의 역할은 애플리케이션과 함께 빌드되어 애플리케이션이 동작하는 환경의 다양한 상태 정보를 일정 주기로 아틀라스와 같은 시스템에 보낸다. 개발자는 아틀라스 시스템이 어떻게 생겼는지 알 필요도 없고, 심지어 Spectator가 어떻게 동작하는지에 대해서도 구체적으로 알아야 할 필요는 없다. 다만 네불라를 통해 플러그인으로 Spectator를 추가하고 빌드하면 나머지는 플랫폼 엔지니어링 팀이 이미 만들어 둔 클라우드 상의 어딘가에 존재하는 아틀라스를 통해 정보를 얻을 수 있게 된다는 것만 알면 된다.
마이크로 서비스 구현은 ‘생태계’가 중요
이와 같이 마이크로 서비스는 어떤 기준으로 무엇을 나누느냐에 대한 문제가 아니다. 필요한 마이크로 서비스를 언제고 만들었다가, 다시 필요 없는 경우 정리를 하거나 업데이트를 할 수 있도록 하는 ‘생태계’가 더 중요한 것이다. 이 생태계는 단순히 컨테이너 오케스트레이션으로 만들어지지 않는다.
개발자가 쉽게 각종 도구를 애플리케이션에 포함할 수 있고, 이렇게 포함된 도구들이 플랫폼과 연동되어 동작하는 것이 중요하다. 여기에는 비단 위의 예에서 설명한 메트릭뿐만 아니라 API 상태 정보, 서킷의 동작 정보, HTTP 상태 코드, 애플리케이션 설정에 필요한 정보를 부트스트랩으로서 제공 하는 등 다양한 기능성이 플랫폼에 필요하다. 즉, 12팩터(http://12factor.net)를 이룩하기 위해서는 애플리케이션 측면뿐만 아니라 이 애플리케이션 지원을 위한 플랫폼이 존재해야 한다는 것이다. 그리고 이 플랫폼은 플랫폼 엔지니어링팀에 의해 운용 되고, 그로서 개발팀을 지원하게 되는 구조를 가지게 된다.
이들 중 Actuator는 넷플릭스의 스펙테이터나 서보가 하는 일과 비슷한 일을 한다. 애플리케이션의 다양한 상태 정보를 개발자에게 제공하는 중요한 역할이다. 이렇게 빌드된 애플리케이션은 클라우드 파운드리에 cf push와 같이 간단한 커맨드로 즉시 개발자가 배포할 수 있다. 매번 운영팀이나 릴리즈 엔지니어링팀에 부탁하거나 메일을 보내거나 티켓을 끊지 않더라도 데이터베이스를 생성하고 새로운 애플리케이션을 배포해서 바인딩할 수 있다.

플랫폼을 통해 생성된 데이터베이스의 접속 정보와 계정 정보는 사람이 기억할 필요가 없다. 만들면 그저 어딘가에 생성되며, 이 생성 정보는 플랫폼이 보관한다. 그리고 애플리케이션에 바인딩 하라고 명령할 때, 이 정보들은 애플리케이션이 동작하는 컨테이너에 환경변수로 제공된다.
애플리케이션이 데이터베이스 접속 정보를 환경 변수를 참조할 수 있도록 개발되고 빌드 되었다면, 개별 환경마다 다시 정보를 변경하고 빌드해야 하는 필요가 사라진다.
정리하며
많은 엔터프라이즈에서 스프링을 사용하고 있다. 이미 개발된 스프링 애플리케이션들은 다양한 환경에서 동작한다. 스프링 팀은 그리고 이 다양한 환경을 지속적으로 지원하고 있다.
클라우드 환경에 적합한, 즉 클라우드 네이티브 애플리케이션은 종전과는 다른 방법의 개발이 필요하다. 기본적으로는 분산 시스템에 대한 이해이며, 최근에는 관련 서적이 매우 많이 존재한다. 이들 중, Release It! 그리고 '카프카, 데이터 플랫폼의 모든것' 그리고 ‘클라우드 네이티브 자바’가 현대에 필요한 애플리케이션 개발 기법들을 소개한다.
기존의 레거시 애플리케이션을 그대로 떠서 클라우드 환경에 옮기는 방법은 클라우드가 제공하는 장점을 누리기 힘든 방식이다. 따라서 초기에는 그러한 전략을 사용하더라도, 이후에는 어떻게든 코드에 손을 대야 한다. 이 경우, 스프링을 사용한다면 스프링 부트로의 전환이 가장 쉽고 빠른 접근이 될 것이다. 스프링 부트의 가장 큰 특징 중 하나는 바로 애플리케이션을 빌드할 때 웹 애플리케이션 서버가 함께 임베드된다는 것이다. 이것이 제공하는 장점은 도커가 제공하는 장점과 동일하다. JVM만 있다면 어디서든 동작 가능한 JAR를 빌드 해 낼 수 있기 때문이다.
넷플릭스의 사례에서처럼, 플랫폼 엔지니어링은 개발자와 개발팀을 고객으로 한다. 이들 사이의 계약은 종전처럼 티켓 시스템이 아니라, API와 라이브러리다. 아마존 웹 서비스에 서버를 만들 때 아마존에 메일을 보내거나 티켓을 끊는 사람은 아마 없을 것이다.
마지막으로 클라우드 파운드리 R&D 총괄을 맡고 있는 온시 파쿠리의 클라우드 개발자를 대변하는 세 문장을 인용하는 것으로 끝맺음을 하고자 한다.
“Here's my source code,
Run it on the cloud for me,
I don't care how.”