



기초통계분석 실전 튜토리얼: 데이터 가공 및 분석(2)
[컴퓨터월드]

| 1. SAS EG 시작하기 - SAS 데이터셋으로 데이터 가져오기 <2016.8월호> 2. 데이터 분석 첫걸음 - 데이터 합하기, 파생변수 만들기 <2016.9월호> 3. 데이터 가공 및 분석(1) - 통계량 탐색, 그래프 탐색 <2016.10월호> 4. 데이터 가공 및 분석(2) - 리포트, 통계 분석, 상관 분석 <이번호> 5. 시각화 분석 통한 인사이트 찾기(1) - SAS 비주얼 애널리틱스 데이터 탐색 6. 시각화 분석 통한 인사이트 찾기(2) - SAS 비주얼 애널리틱스 리포트 디자인 |
지난 강좌에서 다룬 통계량 탐색, 그래프 탐색 등 다양한 방법으로 탐색한 결과는 ‘SAS 리포트’ 형태로 형성된다. 이 SAS 리포트로 생성된 내용은 엑셀에서도 열어볼 수 있고, 매번 새로운 분석 작업을 하지 않아도 엑셀에서 리포팅을 해볼 수 있다. 이번 학습에서는 그 방법을 알아보겠다.
1. 리포트
그림의 요약테이블을 보면 국가별, 달성등급별로 리포트를 작성한 것을 볼 수 있다. 이 리포트를 내보낸 후 엑셀에서 열어 분석해보자.


먼저 리포트를 프로젝트 단계로 내보내고, SAS 리포트 파일을 C: 밑에 저장한다. 엑셀을 열면 SAS라는 탭이 생기며, 여기서 리포트를 선택해 연다.

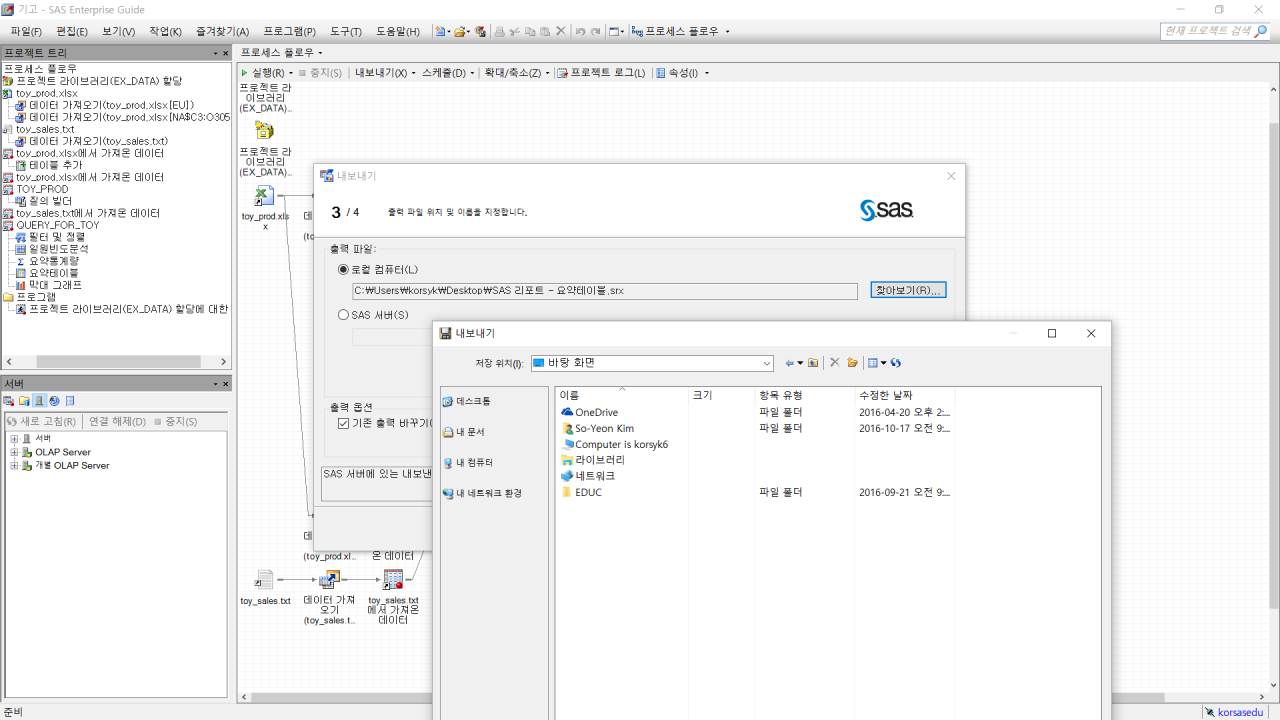
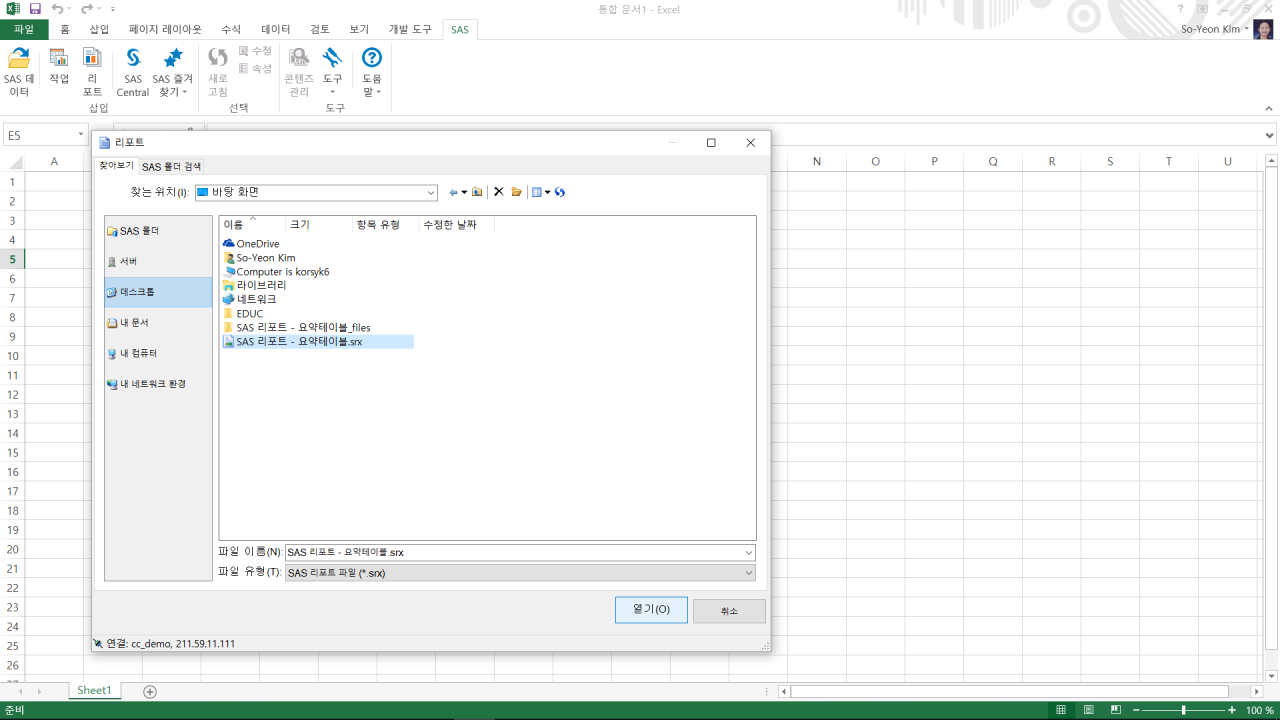

한편, 분석을 하다보면 또 다른 조건으로 리포트를 만들어야 할 때도 있다. 이번에는 분석변수를 매출액, 매출영업비용으로 바꿔주고, 평균값으로 모두 바꿔준 후 다시 실행을 해보겠다.



실행을 하면 전과 다르게 매출액, 매출영업비용이 나온 것을 볼 수 있다. 그리고 다시 엑셀로 돌아가서 새로고침을 하면 최종적으로 분석을 수행했던 요약테이블로 업데이트된 분석결과를 받아볼 수 있다.
2. 통계 분석
분포 분석
최종적으로 만든 데이터인 ‘QUERY FOR_TOY’를 이용해 분포분석을 해보자. 분포분석은 요약통계량과 마찬가지로 통계량을 계산해주고 분석 데이터에 대한 정규성 검증, 줄기잎그림, 상자그림 등 좀 더 깊이 있는 통계 그림을 제공한다.
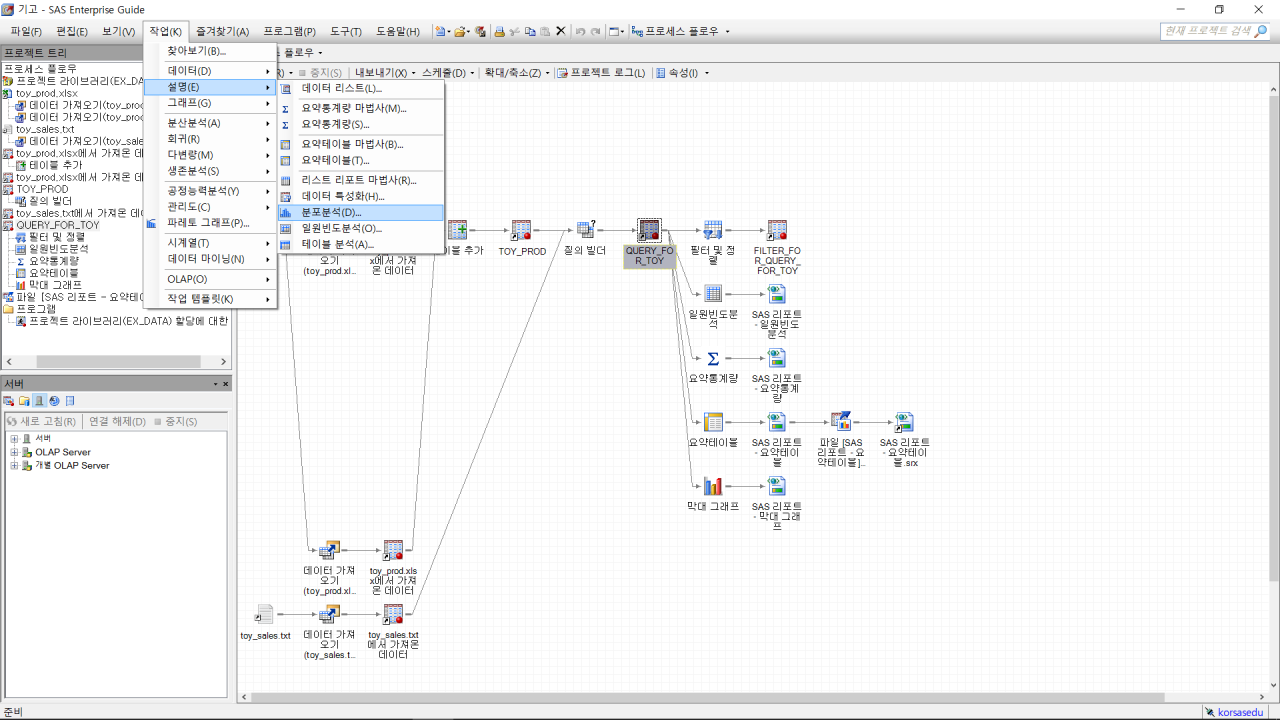
분석변수로 ‘매출영업비용’을 선택하고, 분포도는 ‘정규’, 도표 모양은 ‘히스토그램’과 ‘QQ도표’를 선택해서 보도록 하자.
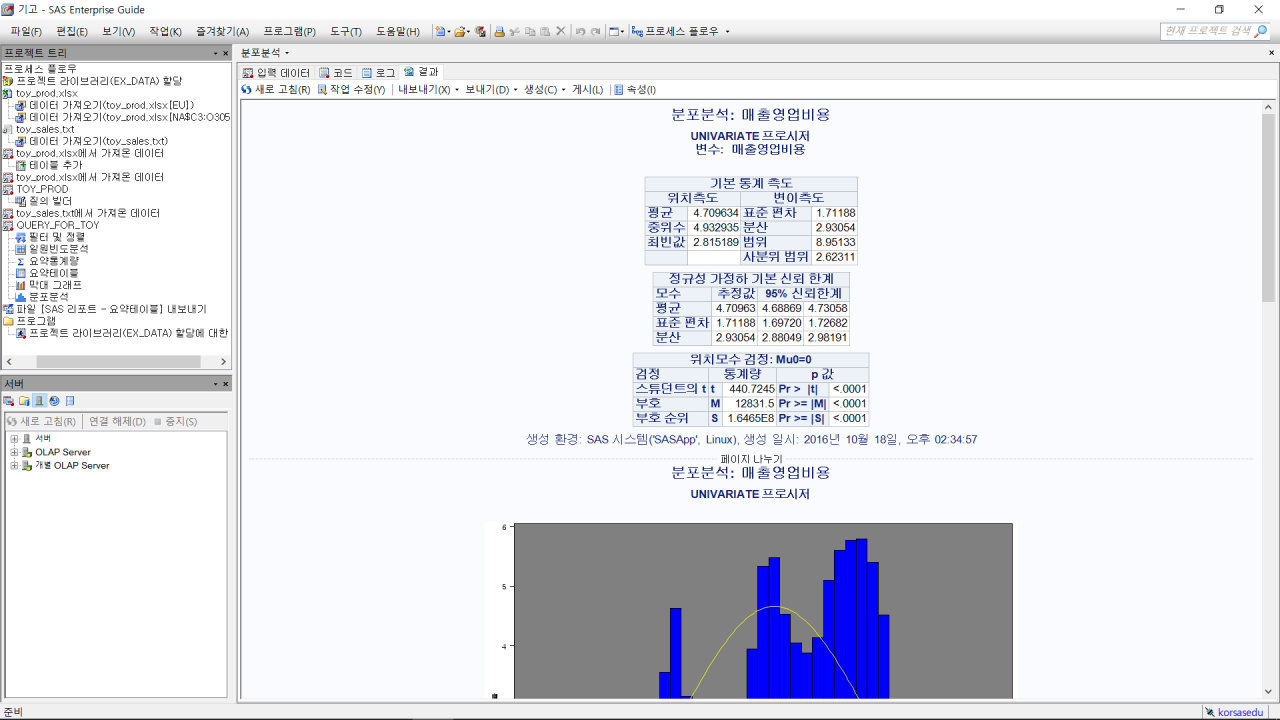

기본적인 통계량만 보는 것으로 선택하고 ‘실행’하면, 매출영업비용에 대한 기본적인 통계량과 함께 매출영업비용이 정규분포에 어느 정도 유사한지 판단할 수 있는 그래프를 볼 수 있다. 매출영업비용은 분석변수에 대한 정규성 검정을 위해서 여러 가지 통계량을 제시한다. 보통 정규성 검정에서는 귀무가설을 설정하는데, 여기서 귀무가설은 ‘매출영업비용의 분포는 정규분포를 따른다’이다.


한편, 이와 비교하기 위해 또 다른 변수인 ‘매출액’을 하나 더 넣어보면, 매출액의 분포는 다소 다른 형태로 분포되는 것을 볼 수 있다. 히스토그램 또한 매출영업비용 변수에 비해 정규분포를 덜 따름을 알 수 있다.
t-검정
통계분석이 아닌 데이터 탐색을 통해 요약통계량이나 분포도를 보는 과정에서 우리는 조건에 따라 다른 속성이 나타나는 것을 볼 수 있었다. 예를 들어 대륙에 따라, 브랜드에 따라 매출액이 달라지는 걸 봤다. 일반적으로 어떤 속성의 조건이 다른 경우 이들 간의 차이를 통계적으로 검증해야 한다. 이때 사용할 수 있는 분석 툴이 ‘t-검정’이다.
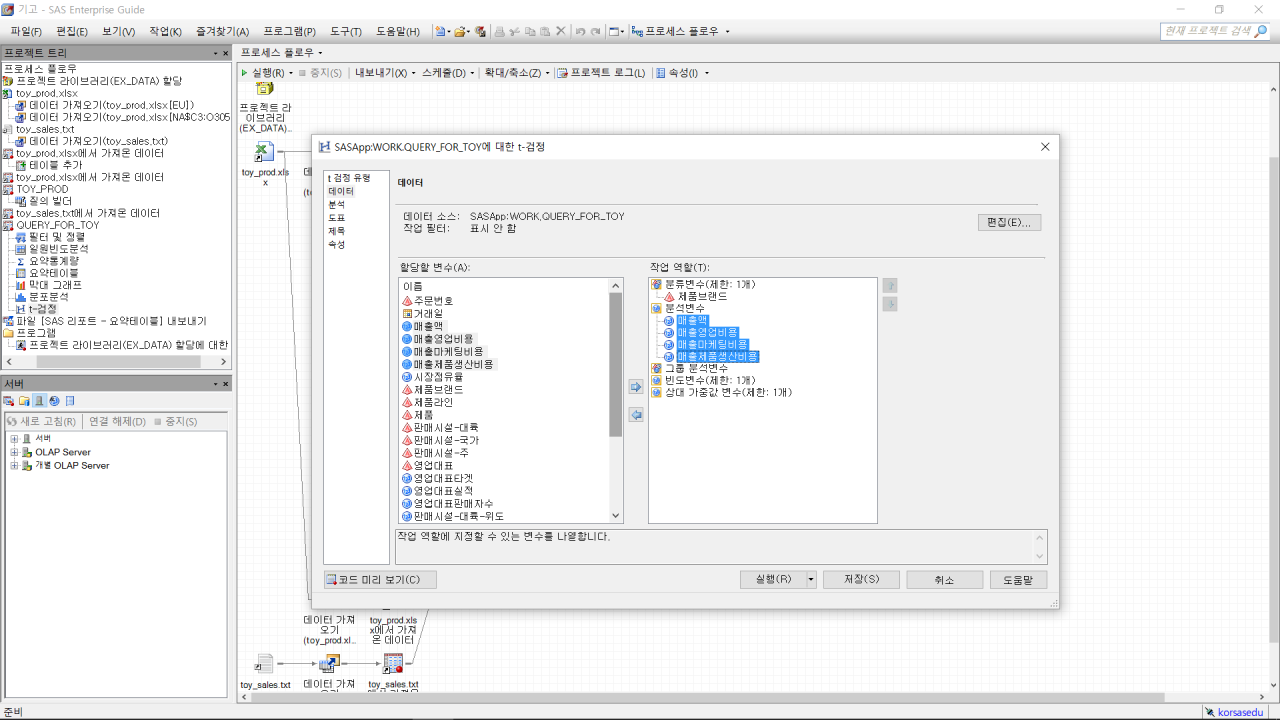
지금부터는 과연 제품 브랜드별로 매출액, 매출영업비용, 마케팅비용 등에 어떤 차이가 나는지 통계적으로 검증해보자. 두 개의 브랜드이므로 검정 유형에서 ‘이표본’을 선택하고, 데이터에서는 분류변수로 ‘제품브랜드’, 분석변수로 ‘매출액’, ‘매출영업비용’, ‘매출마케팅비용’, ‘매출제품생산비용’, 도표는 ‘요약도표’, ‘신뢰구간도표’, ‘QQ그림’을 선택한다.
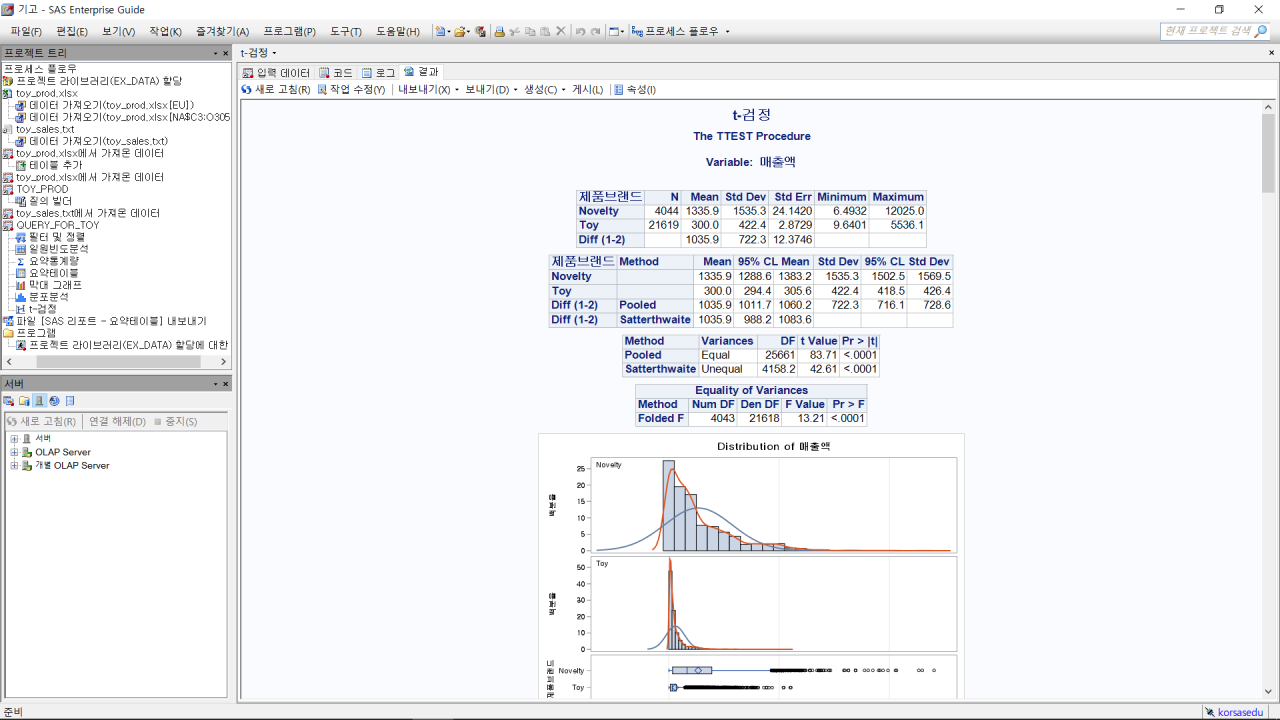
결과 화면이다. Novelty와 Toy 브랜드 간 매출액에는 상당한 차이(약 833)가 있다는 것을 알 수 있다. 이 차이가 통계적으로 유의미한지에 대한 검증은 아랫부분 ‘Equality of Variances’에서 확인할 수 있다. 등분산에 대한 가정을 하기 위해 F검정의 유의확률 값을 보면 0.0001보다 작은 것으로 나왔다. 따라서 등분산성이 만족한다는 귀무가설은 기각하게 된다. 제품브랜드별로 매출액에 차이가 없다는 귀무가설은 기각, 결국에는 제품브랜드 간 매출액 평균에 유의미한 차이가 있다고 판단을 내릴 수 있다.
두 가지 조건에 따라서 두 가지 표본에 따른 평균차 검증은 굉장히 어렵게 느껴질 수 있다. 그러나 ‘t-검정’ 메뉴를 통해 클릭만으로 등분산성가정, 통계적으로 유의미한 차이 여부 등을 쉽게 확인할 수 있다.
3. 상관 분석
앞서 매출액 관련해서는 세 가지 정도의 비용들이 연관돼 분포된 것으로 파악됐다. 그렇다면 다른 비용들이 매출액과 밀접한 선형관계가 있는지를 판단하는 분석을 해보자. 이 같은 분석에는 ‘상관분석’을 이용한다.

다변량에서 ‘상관분석’을 선택, 분석변수로 ‘매출액’, ‘매출영업비용’, ‘매출마케팅비용’, ‘매출제품생산비용’을 선택하고 ‘실행’을 하면 분석변수들 간의 상관관계를 알아볼 수 있다.

네 가지 변수를 이용한 상관분석 결과 화면이다. 각 변수의 평균, 표준편차, 최솟값, 최댓값 등 단순 통계량은 물론, 다른 변수들 간의 상관관계를 볼 수 있다. 두 번째 표에서 대각선에 있는 부분은 동일한 변수에 대한 관계이므로 ‘1’로 상관관계가 높은 것으로 판단된다. 대각선 외 부분은 유의 있게 봐야 하는데, 매출액, 매출마케팅비용, 매출제품생산비용 간에 강한 상관관계가 있다고 판단할 수 있다.
즉, 앞에서 다양한 통계량 탐색을 통해서도 매출액이 높아지면서 특정 비용이 높아짐에 따라 매출액이 많아지는지 판단할 수 있다. 실제 기업에서도 어떤 비용을 많이 늘림에 따라 매출액에 영향을 미치는지를 판단하기 위한 기본 데이터로 활용할 수 있다.
지금까지 우리는 엑셀과 텍스트 데이터를 가져와서 SAS 데이터셋을 이용해 데이터를 핸들링하고, 파생변수를 만들고, 하나하나의 변수별로 또는 두 개 이상의 변수들 간의 통계량에 대해서도 살펴봤다. 직관적인 이해를 위해 다양한 그래프를 이용해 분석을 해봤고, 실제 사용한 데이터에 좀 더 심도 있는 인사이트를 찾기 위해 몇 가지 기초통계분석도 실행해봤다.
이를 위해 사용한 분석도구는 ‘SAS 엔터프라이즈 가이드(SAS Enterprise Guide)’이다. 복잡한 코딩을 덜 하면서도 직관적으로, 그리고 단순한 드래그-앤-드롭과 클릭-앤-클릭만으로 분석에 대한 여러 인사이트를 찾아볼 수 있는 분석도구다. 다음에는 오늘 진행한 내용을 바탕으로 데이터 시각화 분석을 통해 숨겨진 인사이트를 찾는 방법을 알아보겠다.