



데이터 수집 - 크롤링 소개, Scrapy 및 BeautifulSoup 사용방법 (이동균 버즈니 리서치 엔지니어)
[컴퓨터월드]

| 1. 데이터 수집 – 크롤링 소개, Scrapy 및 BeautifulSoup 사용방법 2. 데이터 저장 - EFK 스택 사용방법 3. 데이터 가공 및 분석(1) 4. 데이터 가공 및 분석(2) 5. 데이터 가공 및 분석(3) |
연재를 시작하며
‘데이터마이닝(Data Mining)’이란 ‘대규모로 수집된 데이터를 이용해 통계적 규칙이나 패턴을 찾아내는 것’으로 정의할 수 있다. 데이터마이닝이란 단어가 수용하는 범위가 상당히 넓음에도 불구하고 몇 년 전까지 데이터마이닝은 소수 전문가만을 위한 분야였다. 분석대상인 ‘대규모로 저장된 데이터’를 생산하거나 다룰 수 있는 곳이 드물었기 때문이다.
2000년대 후반, 웹 2.0과 SNS에서 시작된 웹의 발전은 꾸준히 이러한 판을 바꿨다. 페이스북, 트위터, 핀터레스트, 인스타그램 등을 통해 수천만 명의 사용자가 하루에 수십 개의 데이터를 생산하는 일이 일상이 됐으며, 해당 서비스들은 오픈API 등을 통해 자신들의 데이터를 (거의) 무료로 제공함으로써 데이터에 대한 접근성이 엄청나게 향상됐다.
데이터에 대한 접근성 향상은 연구자들과 기업의 관심을 끌기 시작했다. 이는 데이터의 수집·분석 기술의 발전에 더욱 힘을 실어줬고, 수많은 오픈소스 라이브러리들이 개발되고 발전할 수 있었다. 그 결과 현재는 조금의 기술만 습득하면 누구나 방대한 데이터를 수집하고 분석할 수 있는 기술적 환경이 조성됐다.
이러한 환경 위에서 모바일 홈쇼핑 포털 앱 ‘홈쇼핑모아’를 운영하는 버즈니는 월 수천만 건의 로그와 데이터를 수집·분석·검색할 수 있는 시스템을 구축해 운영하고 있다. 그 과정에서 수십 개의 오픈소스 라이브러리와 서비스들을 이용했고 결과는 현재 매우 만족스럽다.
이 로그 분석 시스템을 구축하고 운영하면서 얻은 노하우를 일부 공유하고자 한다. 모쪼록 본 글이 데이터마이닝이라는 짙은 안개에 첫발을 내딛는 사람들에게 손전등 정도의 역할은 할 수 있길 바란다.
크롤러 - 데이터를 어떻게 얻을 것인가?
시작하며 데이터마이닝이란 ‘대규모로 수집된 데이터’가 요구된다고 언급한 바 있다. 본 글에서는 ‘대규모’보다 ‘수집’에 초점을 맞춰 글을 풀어나가려고 한다. 방대한 웹의 바다에 흩어진 데이터를 수집하는 프로그램을 ‘크롤러’라고 부르며, 데이터를 직접 생산하는 경우가 아니면 대부분의 경우 크롤러를 작성해 데이터를 수집하게 될 것이다.
수집대상인 데이터의 형태는 크게 정형적 데이터와 비정형적 데이터로 구분할 수 있을 것이다. 웹2.0의 핵심가치 중 하나인 ‘데이터와 뷰의 분리(separate content from presentation)’로 인해 많은 서비스가 REST(Representational State Transfer) API를 제공하고 있다. 이렇게 API를 통해 XML, JSON, Binary 형태로 제공되는 데이터를 정형적 데이터라고 할 수 있다.
반면 웹페이지 형태(HTML)로 제공돼 직접 파싱해야 하는 데이터를 비정형적 데이터라고 할 수 있다. 웹페이지가 바뀜에 따라 데이터의 위치와 형태 및 가져오는 방법이 모두 바뀌기 때문이다. 웹상에 존재하는 모든 데이터가 정형적 데이터라면 좋겠지만, 우리가 익히 경험한 바, 가치 있는 데이터의 상당수는 비정형적 형태로 제공되고 있다. 따라서 본 글에서는 비정형적 데이터를 파싱해 수집하는 간단한 크롤러를 구현해본다.
버즈니 활용사례 - 구글 리뷰 크롤링
버즈니는 국내 모든 홈쇼핑 상품을 모아서 보여주는 ‘홈쇼핑모아’라는 모바일 앱을 주력 서비스로 하고 있다. 모바일 앱에서 리뷰 평점은 고객 신뢰도, 순위 및 다운로드에 영향을 주게 되며 지속 관리해야 할 대상이다.
그런데 일부 사용자는 1점짜리 앱 리뷰를 등록하면서 서비스 건의나 불만을 토로하기도 한다. 따라서 1점짜리 리뷰는 서비스의 필요악으로 지속 모니터링 할 필요가 있다. 하지만 구글에서는 리뷰 목록을 볼 수 있는 API를 따로 제공하지 않고 있다.
그래서 버즈니는 서비스 운영을 위해 리뷰 목록을 확인할 수 있는 페이지 주소를 알아내고, 해당 페이지의 HTML코드를 파싱해 1점짜리 리뷰만 얻어내는 파서를 만든 뒤, 주기적으로 리뷰들을 수집하는 크롤러를 작성해야 했다.
크롤러 작성하기
URI 알아내기
원하는 데이터가 있는 URI를 알아내는 것은 휴리스틱(경험에서 나오는 직관)에 의존해야 하는 경우가 많다. 이 경우도 예외는 아니다. 크롬 개발자도구의 Network탭을 켜고 구글 앱 페이지의 리뷰 섹션에서 다음 페이지로 계속 넘기다보면 계속 새로운 데이터가 로딩되고 있는 것을 확인할 수 있다. Network탭의 XHR 헤더 요청을 보면 페이지에서 AJAX로 요청하는 URI들을 확인할 수 있는데, 여기서 확인할 수 있는 주소는 아래와 같다.
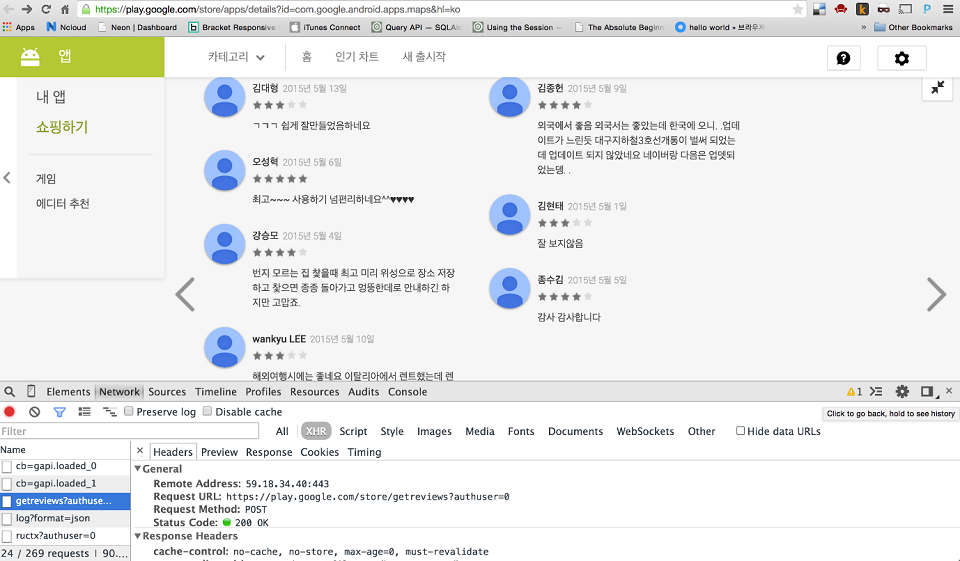
해당 요청에 대한 Headers탭을 보면 POST 요청이라는 사실과 요청 시 전달한 form-data 목록을 확인할 수 있다. 해당 내용을 반영해 파이썬 코드로 요청을 날려본다.

결과가 JSON 문자열 형태로 잘 들어오는 것을 확인할 수 있다. 해당 결과를 파이썬에서 쓸 수 있는 객체로 변환해보자. 단, 5개의 쓰레기 문자열이 채워져 있으므로, 해당 부분을 슬라이싱 하는 것만 주의하면 된다.

HTML 파싱하기
데이터 내용을 살펴보면 각 리뷰에 대한 HTML코드들을 리스트 형태로 반환하고 있다. HTML코드를 파싱하는 파서가 필요한 순간이다. XML/HTML 파서는 다양한 라이브러리가 있지만, 본 글에서는 가장 유명한 라이브러리 중 하나인 BeautifulSoup4(BS4)를 사용해보겠다. 설치방법은 극히 간단하므로 본 글에서는 다루지 않겠다.
HTML문서를 파싱하는 방법은 DOM 트리를 구성하는 일반적인 방식과 정규표현식을 이용하는 방법이 있다. BeautifulSoup에서는 DOM 트리를 구성해서 처리하고 있으며, 그에 따라 노드를 탐색하는 방식도 정할 수 있게 된다.
노드를 탐색하는 방식은 크게 2개로, XPath를 이용하는 방식과 CSS 셀렉터(selector)를 이용하는 방식이다. XML 데이터가 넘쳐나던 예전에는 XPath를 이용해 노드를 탐색하는 것이 일반적이었지만, 최근 풀스택(full-stack)개발자가 늘어나면서 CSS 셀렉터를 이용해 탐색하는 일이 많아지고 있다. 대부분 라이브러리가 CSS 셀렉터 탐색을 지원하며, 본 글에서도 해당 방법을 이용한다.
soup.prettify() 명령을 통해 해당 html 코드를 출력하고 분석해보면,
1. ‘.single-review’ 라는 엘리먼트 아래에 개별 리뷰 내용이 다 들어있고
2. ‘.currennt-rating’에 리뷰 점수가, ‘.review-body’에 리뷰 내용이 들어있다
는 사실을 확인할 수 있다. 해당 내용을 바탕으로 BS4의 CSS 셀렉터로 엘리먼트를 탐색해 데이터를 가져오는 파서를 작성하면 다음과 같다.

파서를 크롤러로 동작시키기
크롤러란 자동화된 방법으로 데이터를 수집하는 프로그램이다. 즉, 우리가 만든 파서가 자동으로 실행되면서 데이터를 수집한다면 크롤러가 되는 것이다. 이제 작성한 파서가 주기적으로 실행되면서 1점짜리 리뷰를 찾아 로그를 남기도록 해보자.

지금까지 아주 간단한 형태의 파서와 크롤러를 만들어봤다. 크롤러의 전체 코드는 http://github.com/haandol/review_crawler 에서 확인할 수 있다. 위의 내용을 다 이해했다면 어떠한 형태의 비정형 데이터를 만나도 원하는 형태로 가공하고 수집할 수 있을 것이다.
마지막으로, 본 글에서 다루지는 않았지만, 크롤러의 핵심은 구현이 아니라 운영에 있다고 해도 과언이 아니다. 단순 헤더체크 문제 또는 데이터 정확성 검증 문제부터, 쿼리 횟수 제한 문제, 자바스크립트를 이용한 비동기 마크업 생성, 동일 페이지에 대한 다중 크롤러 운영 시 중복 수집 및 공유자원(Race Conditon) 문제까지 정말 다양한 문제들이 발생할 수 있다. 이러한 문제의 해결방법은 경험을 통해서만 얻을 수 있다.
원하는 데이터가 보인다면 지금부터 크롤러를 만들어보자. 자신이 만들고 운영한 크롤러 개수만큼 전문가에 가까워져 있을 것이다.