



vLLM 운용 최적화, 고성능 GPU 인프라 지원
[아이티데일리] 클라우드 서비스 전문기업 스마일서브(대표 김병철)가 고속 대규모언어모델(LLM) 프레임워크인 vLLM의 운용에 최적화된 그래픽처리장치(GPU) 가상 서버를 22일 출시했다고 발표했다. 대용량 메모리를 탑재한 최신 GPU 인프라를 기반으로 설계된 것이 특징이다. ‘하이퍼클로바X시드(HyperCLOVA X SEED)’ 등 다양한 언어모델과 GPT-OSS 120B 규모의 대형 모델까지 안정적으로 운용할 수 있다.

vLLM은 페이지드 어텐션(paged Attention) 기술을 통해 GPU 메모리 내 KV캐시(Key-Value cache)를 효율적으로 관리하고, 응답 속도를 높이는 오픈소스 LLM 추론 엔진이다. 한정된 GPU 자원에서도 원활한 AI 서비스를 구동할 수 있도록 지원한다.
이번에 공개된 GPU 서버는 엔비디아(NVIDIA)의 차세대 GPU 아키텍처인 ‘블랙웰(Blackwell)’ 기반 ‘PRO6000’ 서버다. GDDR7-ECC와 DDR5 메모리(Memory)를 기반으로 한다. 최대 864기가바이트(GB)까지 용량을 확보할 수 있도록 구성됐다.
특히 스마일서브는 가상 서버 환경에서도 vLLM의 핵심 장점인 빠른 토큰(Token) 응답 속도를 최대한 끌어낼 수 있도록 최적화했다. 자체 테스트 결과 GPT-OSS 120B 모델 기준, 초당 181.42 토큰으로 성능이 확인됐다. PRO6000 GPU 1개 테스트를 기준으로 했다.
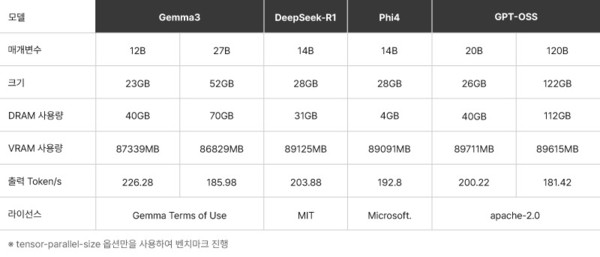
스마일서브는 GPU 서버 라인업 개편에 맞춰 PRO5000 및 PRO4000 기반 가상 GPU 서버 출시도 앞두고 있다. 이를 통해 높은 성능을 요구하는 LLM 학습·서빙 환경은 물론, 중·소규모 AI 개발, 테스트 워크로드까지 대응할 수 있는 인프라를 업그레이드 할 계획이다.
스마일서브는 이번 GPU 가상 서버 출시를 기념해 반값 프로모션도 진행 중이다. 아이윈브이(iwinv)의 GPU 서버를 1년 이상 이용한 고객은 추가로 1년 서비스 약정 시 50% 할인된 금액으로 서비스를 이용할 수 있다.