



KAIST 전기및전자공학부 황의종 교수팀…AI의 특정 데이터 의존 편향 해결
[아이티데일리] KAIST 연구진이 데이터 편향성 문제를 해결해 AI의 정확성을 향상하는 새로운 멀티모달 AI 학습 기술을 공개했다.
이번에 공개된 기술은 기존의 멀티모달 AI가 다양한 데이터 형태를 동시에 처리하는 과정에서 특정 형태에 의존해 판단하는 문제를 해결하기 위해 개발됐다.
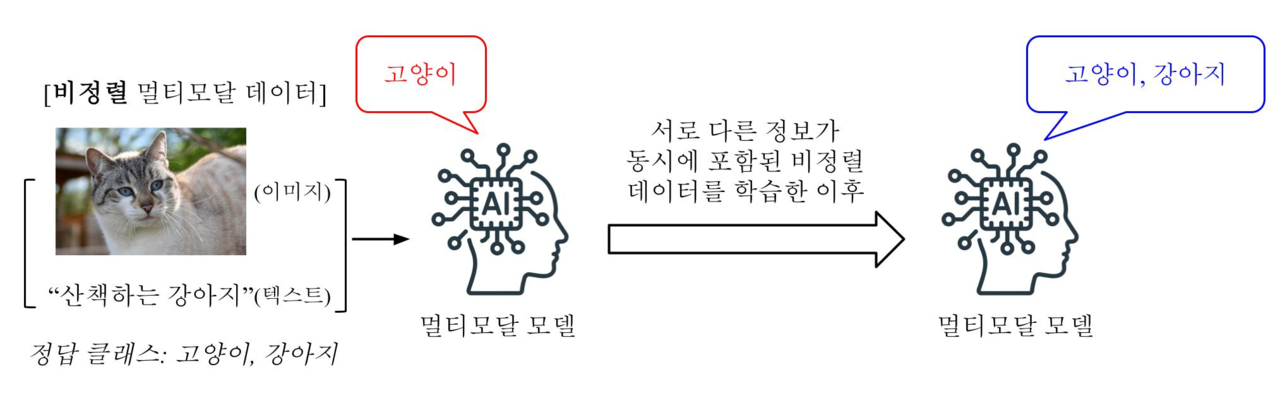
KAIST 연구진은 비정렬 샘플을 활용해 문제를 해결했다. 비정렬 샘플은 의미적으로 불일치 하는 데이터를 조합해 만든 멀티모달 데이터다. 예를 들어 ‘고양이’라는 텍스트와 ‘강아지’ 이미지를 붙이는 방식이다.
이러한 데이터를 AI 모델에게 학습하게 되면 기존에 특정 형태에 의존하던 AI의 경향을 해결할 수 있다. 이전에 자주 활용된 멀티모달 데이터는 같은 의미의 데이터를 동시에 학습시키는 경우가 많아 AI 모델이 특정 형태에 대한 의존성을 지니게 됐다.
연구진은 비정렬 샘플의 성공적인 활용을 위해 두 가지 가중치 기법을 제시했다. 먼저 약한 모달리티 가중치다. AI 모델이 판단 과정에서 비교적 덜 활용하는 데이터 유형에 의도적으로 높은 가중치를 부여하는 방식이다.
다음은 어려운 샘플 가중치다. 비정렬 샘플의 경우 의미적으로 유사한 데이터가 조합될수록 AI가 판단하기 어려운 ‘경계선상의 샘플’이 생성된다. 이를 AI 학습 과정에 집중적으로 활용하는 방식으로, 모델의 의미 구별 능력을 향상시킨다.
연구진은 연구 성과를 확인하기 위해 다양한 멀티모달 분류 벤치마크를 활용했다. 가장 주목할 만한 결과는 CREMA-D 데이터셋 분석에서 나타났다. 테스트에 활용한 기존 모델은 음성 정보에 편향성을 지니고 있어 비디오 정보 활용도가 19.2%에 불과했으나, 이번 학습 기술을 적용한 후 49.9%로 2.5배 이상 증가했다. 전체 정확도 역시 69.6%에서 73.7%로 상승했다.
한편 이번 연구진에는 전기및전자공학부 황성현 박사과정, 최소영 석사과정이 공동 제1 저자로 참여했으며, 황의종 교수가 교신저자로 참여했다. 연구 결과는 오는 12월 미국 샌디에이고와 멕시코 멕시코시티에서 열리는 국제학술대회 NeurIPS에서 발표될 예정이다.
연구진은 이번 기술이 사용자의 복잡하고 미묘한 의도나 상황을 정확하게 파악해야 하는 자율주행, 휴머노이드 로봇, 정교한 감정 분석 시스템 등에 적용될 수 있을 것으로 기대하고 있다.
KAIST 전기및전자공학부 황의종 교수는 “AI 성능을 높이려면 모델 구조(알고리즘)만 바꾸는 것보다, 어떤 데이터를 어떻게 학습에 쓰느냐가 훨씬 중요하다”며 “이번 연구는 멀티모달 인공지능이 특정 데이터에 치우치지 않고 균형 있게 정보를 활용할 수 있도록 데이터 자체를 설계하고 가공하는 접근법이 효과적일 수 있음을 보여줬다”고 말했다.