



연세대학교 윤현수 산업공학과 교수

윤현수 교수는 인공지능(AI)과 도메인 지식 융합 기술을 활용해 의료와 제조업 분야의 실질적인 문제 해결에 주력하고 있다. 윤 교수는 반도체 공정 진단, 비전 검사, 이상 탐지와 같은 제조업 문제부터 MRI, CT, 심초음파를 활용한 의료 영상 진단 및 치매 분석 등을 연구하고 있다. SK하이닉스, 삼성디스플레이, LG에너지솔루션 등 국내 대기업과의 산학협력을 통해 도메인 적응, 비전 및 센서 이상 탐지모델 개발, 혐의 설비 탐지 프레임워크 설계에 기여하고 있으며, 메이요 클리닉(Mayo Clinic), 컬럼비아 대학교(Columbia University) 의과대학, 서울대분당병원, 세브란스병원 등과 협력해 초정밀 진단 모형 개발에도 앞장서고 있다. 윤현수 교수는 AI 기술이 산업과 의료 현장에서 실질적인 문제 해결 도구로 자리 잡는 데 기여하고 있다.
[아이티데일리]
겉보기에 멀쩡한 제품, 보이지 않는 이상을 찾으려면?
산업 현장에서 이상탐지(Anomaly Detection, AD)는 제품 품질 관리와 고장 예방을 위한 핵심 기술이다. 특히 ‘논리적 이상(logical anomaly)’은 육안으로는 정상처럼 보여도 구성 요소의 존재 유무, 수량, 배치 등과 같은 논리적 규칙을 어기는 경우를 의미한다. 예를 들어, 조립된 기계 부품에서 볼트 하나가 누락된 상태는 눈에 띄지 않을 수 있지만 명백한 이상이다. 이는 표면 긁힘이나 오염처럼 즉각적으로 드러나는 구조적 이상(structural anomaly)과는 성격이 다르다.
이러한 논리적 이상은 감지 이후 “왜 이상인지”에 대한 설명이 반드시 필요하다. 단순히 점수 맵이나 이상 여부만 제공하는 기존 이상탐지 시스템으로는 대응이 어렵고, 때로는 오탐지나 오해로 이어질 수 있기 때문이다. 최근의 이상탐지 연구는 이처럼 설명 가능성(Explainability)이 강조되는 방향으로 진화하고 있으며, 그 중심에는 비전-언어 모델(Vision-Language Model, VLM)이 있다.

전통 기법의 한계 – 논리적 이상은 설명이 어렵다
기존 이상탐지 방식은 대부분 구조적 결함에 초점을 맞춰왔다. 예를 들어 오토인코더(autoencoder)는 정상 이미지 다수를 학습하고 재구성 오차를 기준으로 이상을 탐지한다. 하지만 이는 대량의 정상 샘플이 필요하며, 새로운 유형의 이상에는 적응이 어렵다. PatchCore와 같은 메모리 기반 기법은 사전 학습된 비전 모델을 활용해 소량의 정상 데이터로도 이상탐지가 가능하지만, 결과로 제공되는 건 여전히 픽셀 히트맵일 뿐, “왜 이 이미지가 이상한가?”에 대한 설명은 부재하다.
게다가 논리적 이상은 규칙 위반이 본질이기 때문에 단순 이미지 비교로는 놓치기 쉽다. 이를 코드로 일일이 규칙화하는 것도 비현실적이다. 따라서 소량의 정상 이미지만으로, 추가 학습없이, 자연어로 설명 가능한 탐지 방식이 요구된다.
질문하고, 답하면서 이상을 찾는다 – LogicQA의 네 단계
이러한 배경에서 필자의 연구팀이 개발한 로직QA(LogicQA)가 제안됐다. 이번 기고에서는 LogicQA의 작동 원리를 소개하며, VLM이 이미지를 보고 스스로 질문을 만들고 답하는 방식으로 논리적 이상을 판별하는 과정을 다룬다. LogicQA는 다음과 같은 네 단계로 구성돼 있다.
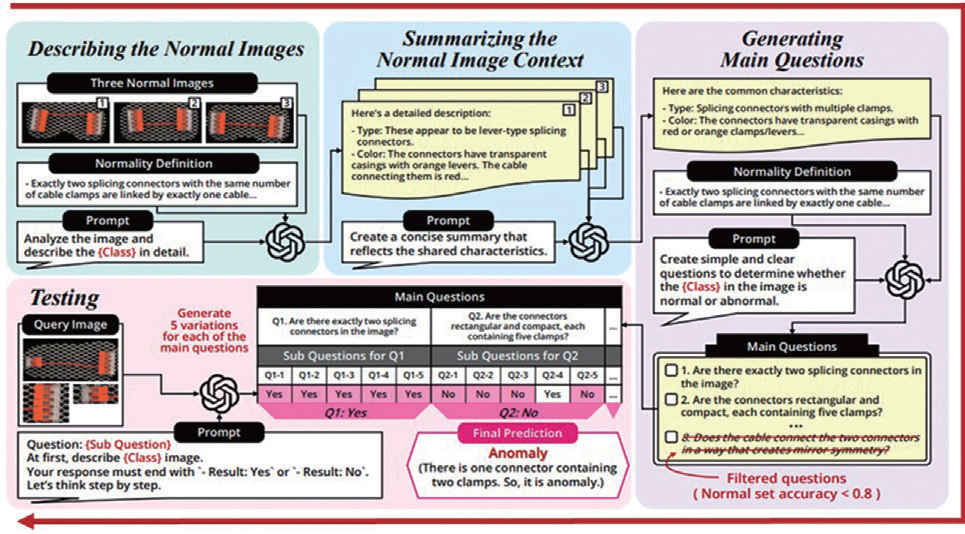
1. 정상 상태 서술(Describing)
사전학습된 VLM에 소량의 정상 이미지를 입력하면, 각 이미지를 자연어로 상세히 설명한다. 사람이 검사하듯 “이 이미지에는 커넥터가 두 개 있으며, 케이블로 연결돼 있다”와 같은 기술을 생성한다. 이로써 VLM은 시각 정보를 언어적 구조로 정리하며, 핵심 속성에 집중한다.
2. 정상 맥락 요약(Summarizing)
여러 정상 이미지에서 생성된 설명을 종합해, 공통된 정상 규칙을 요약한다. 이를 통해 특이한 예외 요소를 제거하고, 모든 정상 사례에 공통된 핵심 조건만 남긴다. 예컨대 ‘커넥터는 항상 두 개, 동일한 방향’ 등의 규칙이 자동 추출된다.
3. 질문 생성(Generating)
요약된 규칙과 정상 상태 정의를 바탕으로, 모델이 스스로 논리적 체크리스트 형태의 질문을 생성한다. “케이블은 하나인가?”, “커넥터는 두 개인가?”처럼 실제 검사자가 물을 법한 질문들이다. 생성된 질문은 정답률 기준으로 필터링된다. 정상 이미지에 적용했을 때도 오답이 잦은 질문은 제외돼, 정제된 핵심 질문 리스트만 남는다.
4. 질문-응답을 통한 판정(Testing)
테스트 이미지가 들어오면, 앞서 정제된 핵심 질문들을 VLM에 제시해 답변을 유도한다. 각 질문은 표현을 달리한 여러 하위 질문으로 프레이징되며, 다수결 투표 방식으로 응답을 종합한다. 모든 질문에 Yes가 나오면 정상, 하나라도 No가 있으면이상으로 분류된다. 예를 들어 “클램프 수가 동일한가?”라는 질문에 ‘아니오’가 나오면, 바로 ‘구성품 수량 불일치’라는 논리적 이상 사유로 연결된다.
실제 사례 – MVTec LOCO와 SEM 이미지에서의 효과
LogicQA는 공개 벤치마크와 산업 데이터에서 모두 효과를 입증했다. MVTec LOCO AD 데이터셋의 ‘Breakfast Box’ 사례에서는 시리얼 상자 구성품 중 누락이 있을 경우, LogicQA가 “쿠키가 존재하지 않는다”는 질문-응답 기반 설명을 생성하며 이상을 판정했다.
SEM 이미지 기반 반도체 결함 탐지에서도 LogicQA는 “이물 입자가 특정 위치에 존재하는가?”와 같은 질문을 통해, 미세결함을 높은 정확도로 포착했다. 이 과정에서 연구팀은 VLM의 한계를 극복하기 위해 배경 제거(BPM)와 세그먼트 분리(Lang-SAM) 등 전처리 기법도 함께 도입했다. 특히 VLM은 이상 이미지에 대해 불확실한 응답을 내놓는 경향이 있으며, 이는 질문별 응답 확률의 로그 확률(log-probability) 분포로도 확인된다.

사람처럼, 설명하고 납득시키는 AI
LogicQA의 가장 큰 장점은 결과에 대해 사람이 이해할 수 있는 설명을 제공한다는 점이다. 모델이 “이 부분이 이상하다”라고 표시하는 데 그치지 않고 “이 제품은 나사 하나가 부족해 이상”, “두 개의 케이블 연결 중 하나가 끊겨 있어 이상” 등의 이유를 논리적으로 설명한다.
또한 LogicQA는 별도의 학습 없이 작동하며(trainingfree), 수동 매뉴얼 작업 없이(annotation-free) 사용할 수 있다는 특징이 있다. 새로운 제품군이나 검사 대상이 바뀔 때 매번 모델을 처음부터 다시 학습시키거나, 정상 상태를 사람이 일일이 라벨링하지 않아도 된다. 극소량(예컨대 3장 내외)의 정상 예시와 그에 대한 기본적인 정상 상태 정의만 주어지면, VLM이 이를 토대로 알아서 해당 제품의 정상 규칙을 학습하고 이상 여부를 묻는 질문들을 만들어낸다. 이때 LogicQA는 사람이 별도로 작성한 프롬프트나 규칙 코드 없이도 작동하기 때문에 매우 범용적이다.
한마디로 이상탐지 분야에 사람의 논리적 사고방식을 이식한셈이며, ‘무엇이, 왜 이상한지’를 AI가 직접 설명해주는 새로운 패러다임이라 할 수 있다.환경 적응성과 향후 방향 LogicQA는 질문-응답 구조를 기반으로 높은 설명력을 제공하지만, VLM 특성상 조명, 배경, 노이즈 등 환경 변화에 따라 응답의 일관성이 낮아질 수 있는 한계도 존재한다. 이러한 문제를 해결하기 위해 최근에는 Test-Time Adaptation(TTA) 기술이 함께 주목받고 있다.
TTA는 모델이 학습된 이후, 재학습 없이 테스트 시점에서 입력 데이터의 통계에 맞춰 모델의 일부 파라미터를 동적으로 조정하는 방식이다. 전통적인 도메인 적응(domain adaptation)이 전체 모델을 재학습하는 방식인 반면, TTA는 경량의 조정만으로도 즉시 예측 방식을 조율할 수 있다. 쉽게 말해, AI 모델이 새롭게 변화한 환경에 ‘눈을 다시 맞추는’ 방식이라 할 수 있다.
최근 연구들은 이러한 TTA 기법을 LogicQA와 같은 설명 가능한 모델 구조에 결합함으로써, 실사용 환경에서의 일관성과 신뢰성을 높이려 한다.
설명 가능한 AI 진단 기술, 그 세 번째 이야기로서
LogicQA는 소량의 정상 이미지만으로도 동작하며, 별도의 학습 없이 적용 가능하고, 결과를 사람이 납득할 수 있는 자연어로 설명할 수 있다는 점에서 새로운 형태의 이상탐지를 가능하게 한다. 이처럼 사람의 논리적 사고 구조를 그대로 차용한 시스템은, 불확실성과 복잡성이 큰 제조나 의료 현장에 적합한 해석 가능한 AI의 대표적인 예로 주목받고 있다.
이번 7월호를 끝으로, 5월호의 BioNet, 6월호의 UniFormaly, 그리고 LogicQA까지 총 세 차례에 걸친 연재를 마무리한다. 세 기술은 제한된 학습 데이터량을 극복하기 위해 설계됐으며, 모두 소량의 데이터로도 높은 성능을 내며, 별도의 학습 비용 없이 도메인 지식을 효과적으로 활용하고, 결과를 자연어로 설명하는 방향으로 공통적으로 진화하고 있다. 설명 가능한 AI 진단의 흐름은 이제 시작일 뿐이며, 앞으로도 다양한 분야에서 인간처럼 ‘이해하고 설명하는’ AI의 등장이 기대된다.
* 본 기고는 2025 ACL Industry Track에 출판된 논문을 기반으로 했다.