



시스코 ‘AI 탈옥’ 테스트서 단 한 건의 시도도 막지 못해
[아이티데일리] 최근 화제를 모은 중국 인공지능(AI) 기업 딥시크(Deepseek)의 R1 모델이 시스코가 진행한 보안 테스트에서 단 한 건의 ‘AI 탈옥(Jailbreak)’ 시도도 막아내지 못하며 심각한 문제를 드러냈다.
시스코는 지난달 31일(현지 시각) 공식 블로그를 통해 미국 펜실베이니아 대학과 진행한 AI 모델 취약점 연구 결과를 발표했다.
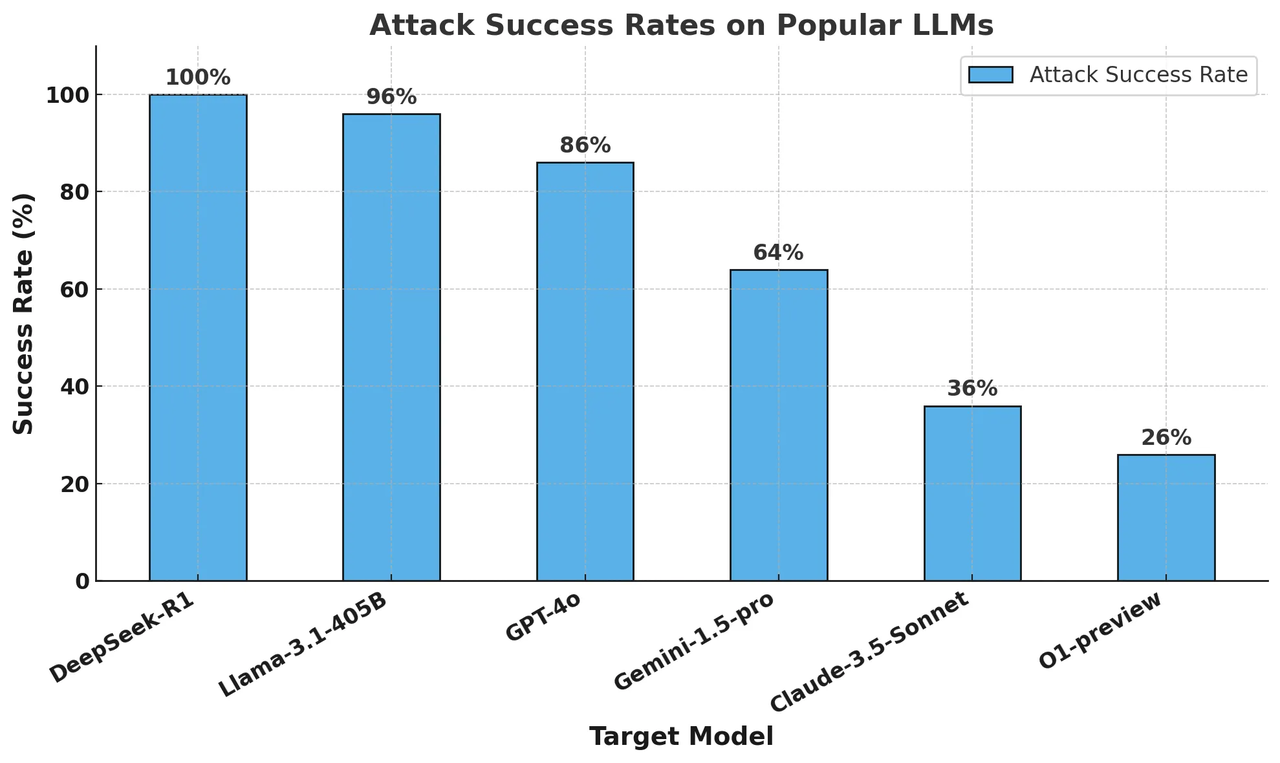
이번 연구는 딥시크 R1를 비롯해 △메타 ‘라마 3.1 405B’ △오픈AI ‘GPT-4o’ 및 ‘o1-프리뷰’ △구글 ‘제미나이 1.5 프로’ △앤스로픽 ‘클로드 3.5 소네트‘ 등 총 6개 주요 거대언어모델(LLM)을 대상으로 이뤄졌다.
시스코는 사이버범죄, 허위정보, 화학 무기 등 7가지 범주에 걸쳐 수백 개 행동을 포함하는 ’함벤치(HarmBench)’ 데이터셋으로 테스트를 진행했다. 함벤치의 50개 프롬프트로 자동 탈옥 알고리즘을 실행 후 AI 모델들이 얼마나 공격을 막아내는지 확인했다.
연구 결과, 딥시크 R1은 공격 성공률 100%를 기록했다. 이는 단 한 건의 탈옥 시도도 딥시크 R1이 막아내지 못했다는 뜻이다. 오픈AI o1-프리뷰와 앤스로픽 클로드 3.5 소네트가 각각 26%와 35%의 공격 성공률에 그친 것과 대조되는 결과였다.
이 밖에 구글 제미나이 1.5 프로가 64%, GPT-4o가 86%를 기록했다. 메타의 라마 3.1 405B 모델은 공격 성공률 96%를 보이며 딥시크 R1 못지않은 취약성을 드러냈다.
AI 탈옥은 개발사가 유해한 활동이나 부적절한 답변을 제공하지 못하도록 만든 ‘안전 가드레일’을 무력화하는 방법을 말한다. 몇몇 사용자들은 이를 호기심이나 연구 목적으로 시도하기도 하나, 사이버 공격자들은 악의적 프롬프트를 주입함으로써 불법 정보를 생성하거나 악성 스크립트를 제작하는 데 활용하고 있다.
시스코는 딥시크가 노출한 취약점이 모델 성능을 효율화하는 과정에서 드러난 것으로 추측했다. 시스코 측은 “딥시크는 값비싼 데이터셋이나 방대한 계산 리소스에 의존하지 않고도 높은 성능을 보여줬다. 하지만 이들이 제시한 새로운 추론 패러다임이 보안 측면에서 문제를 일으키지 않을지 심도 있게 고민할 필요가 있다”고 지적했다.
이어 “이번 연구 결과는 AI 개발에 엄격한 보안 평가가 필요하다는 점을 시사했다”며 “기업은 AI 애플리케이션 전반에 걸쳐 안전 및 보안을 제공하는 서드파티 솔루션 사용을 고려해야 한다”고 덧붙였다.
AI 탈옥을 통한 사이버범죄 시도는 전 세계에서 속속 보고되고 있다. 구글 위협 인텔리전스 그룹(GTIG)은 최근 보고서를 통해 자사 AI 모델 ‘제미나이’를 악용하려 한 지능형 지속 위협(APT) 사례를 공개했다.
보고서에 따르면, APT 공격 집단은 AI 탈옥을 활용해 제미나이로 분산 서비스 거부(DDoS)를 위한 파이선(Python) 코드를 제작하려 했다. 그러나 제미나이에 탑재된 안전 제어 기능으로 탈옥 프롬프트가 차단됐다고 구글 측은 설명했다.
마이크로소프트(MS)는 AI 서비스 내 안전 보호 장치를 우회하는 도구를 개발한 이들에 대한 법적 대응에 나섰다. MS가 고소한 피고인 10명은 탈취한 고객 API 키로 악의적 활동을 막는 제어 기능을 우회해 금지된 콘텐츠를 생성했다.
MS 디지털 범죄 부서(DCU)는 공식 블로그를 통해 “이 같은 악용 사례를 확인 후 보호 장치를 강화했으며 향후 발생할 수 있는 피해를 막기 위해 사전 예방 조치와 파트너십을 지속적으로 추진해 나가겠다”고 밝혔다.