



아마존웹서비스(AWS) 전현상 솔루션즈 아키텍트

[아이티데일리] 대규모 언어 모델(Large Language Models; LLM)에 대한 관심이 급증하면서, 많은 개발자와 조직이 이를 활용해 다양한 애플리케이션을 개발하는 데 집중하고 있다. 하지만 사전 훈련된 LLM이 항상 예상대로 또는 기대한 대로 작동하지 않는 문제점들이 발생한다. 특히 작은 파라미터를 가진 소규모 LLM(sLLM)이나 특정 도메인에 대한 사전 학습이 부족한 일반 LLM에서 모델의 환각 발생이 더 자주 나타난다. 이러한 문제를 해결하기 위해 본 글에서는 LLM의 오류들과 환각 발생을 어떻게 완화할 수 있는지, 그리고 사실 기반 데이터를 활용해 응답하는 최근 방법들에 대해 소개한다. 특히 프롬프트 엔지니어링, 검색 증강 생성(RAG) 기법, 그리고 고급 RAG까지 LLM의 성능을 어떻게 향상시킬 수 있는지에 대한 다양한 접근 방법을 소개한다.
1. 소개
LLM의 발전은 인공지능 분야에서 중대한 도약을 이뤘다. 이러한 파운데이션 모델들은 텍스트 생성, 번역, 요약 등 다양한 언어 처리 작업에서 뛰어난 성능을 발휘하며, 점차 우리 일상생활 속으로 깊숙이 침투하고 있다. 하지만 이러한 모델들이 가끔 예기치 않은 오류를 내거나, 모델의 환각(Hallucination)을 일으키는 경우가 있다. 모델의 환각은 LLM이 실제 데이터나 사실과 일치하지 않는 정보를 생성하는 현상을 말한다.
예를 들어 모델이 특정 역사적 사건에 대해 완전히 틀린 날짜를 제시하거나, 존재하지 않는 인물에 대한 이야기를 만들어 내는 경우다. 어텐션 트랜스포머 기반의 LLM이 훈련 과정에서 다양한 데이터를 학습하면서 입출력부분에 단어 간 패턴을 인식하고, 다음 새로운 텍스트를 생성하는 근본적인 원인 때문에 발생한다. 또는 모델이 때로는 잘못된 문장 패턴을 학습하거나, 사용자의 질의가 모호할 때 잘못된 정보를 추론하게 된다. 이러한 환각은 특히 모델이 충분한 모델 파라미터(계수)를 갖고 있지 않거나, 특정 도메인에 대한 충분한 사전 학습이 부족할 때 더 빈번하게 발생한다1).
예를 들어 의학적 또는 금융 지식을 요구하는 질문에 대해 일반적인 LLM이 응답할 경우, 정확하지 않거나 오해의 소지가 있는 정보를 제공할 위험이 있다. 최근 이러한 모델의 환각을 해결하기 위해 LLM을 특정 도메인에 맞게 추가적으로 학습시키거나, 입력 데이터를 보다 정교하게 조정하는 등의 방법이 사용되고 있다. LLM 모델의 한계를 극복하는 부분은 LLM을 실제 상용 환경에서 LLM 애플리케이션을 좀 더 유용하고 신뢰할 수 있게 만드는 데 중요한 과제이다.
본문에서는 프롬프트 엔지니어링, RAG 기법 등 LLM의 성능을 높이기 위한 다양한 기법들을 자세히 다룰 예정이다. 프롬프트 엔지니어링은 모델 입력을 조정해 원하는 출력을 유도하는 기술로, 모델이 더 정확하고 관련성 높은 응답을 생성하도록 돕는다. RAG는 모델이 질의에 대한 응답을 생성하기 전에 관련 정보를 외부에서 검색해 다시 요약하는 응답의 정확도를 높이는 방법이다. 또한 모델의 환각을 줄이기 위해 파인튜닝을 진행하기도 한다. 파인튜닝은 모델을 특정 도메인에 맞춰 추가 학습시키는 과정으로, 정리된 사전 학습 데이터가 충분히 있다면 모델이 특정 주제에 대해 더욱 정확하게 응답할 수 있게 할 수 있다.
이 방법들은 LLM의 성능을 향상시키고, 다양한 환경에서 LLM 애플리케이션의 유용성을 제공하기 때문에 LLM을 실제 상용 환경에서 더욱 신뢰할 수 있도록 만드는 데 중요한 요소이다. 지금도 파인튜닝이나 RAG 중 어떤 상황에서 선택이 적합한지에 대해 많은 논쟁이 있다. 이 기고에서는 지면상 RAG에 초점을 맞추려고 한다.
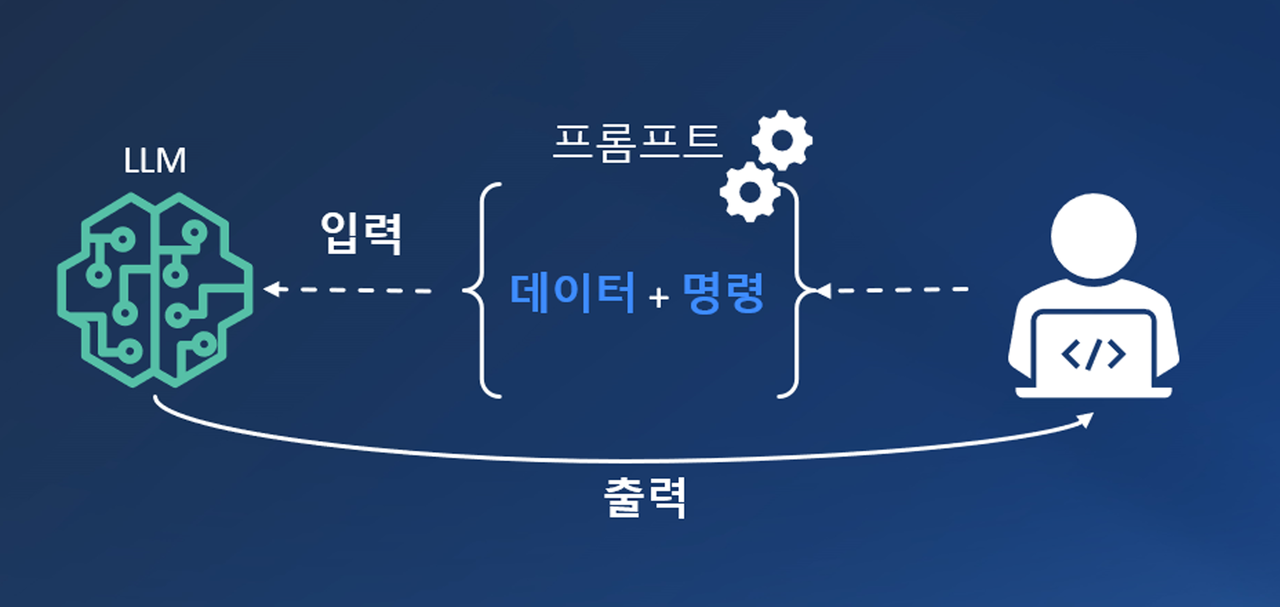
2. 본론
2.1 프롬프트 엔지니어링
프롬프트 엔지니어링은 LLM의 출력을 최적화하기 위해 입력 텍스트를 전략적으로 조정하는 기술이다. 이 방법은 모델이 특정 컨텍스트나 지시에 따라 더욱 정확하고 적절한 응답을 생성하도록 처리할 수 있다. 또한 프롬프트 엔지니어링은 사용자의 질의가 모호할 때 발생할 수 있는 모델의 환각을 줄이는 데에도 중요한 역할을 한다. 모호한 질의로 인해 모델이 잘못된 정보를 추론하거나 환각을 일으킬 가능성이 높아지는 데, 정교하게 설계된 프롬프트는 이러한 오류를 최소화해 모델이 더 정확한 답변을 제공하도록 유도한다.
최근 LLM 애플리케이션 개발에서 질문 답변 및 산술 추론과 같은 일반적이고 복잡한 작업에 대한 LLM의 역량을 향상시키고 프롬프트 엔지니어링을 사용해 LLM 및 기타 도구와 인터페이스하는 강력하고 효과적인 프롬프트 기술을 설계하는 부분이 중요해지고 있다. 프롬프트 엔지니어링은 RAG와 같은 기술과 결합될 때, LLM의 성능을 더욱 향상시키는 근간이 된다. 따라서 프롬프트 엔지니어링을 통한 LLM의 기능을 인터페이스하고 구축하고 이해하는 것은 중요한 부분이다.
본 글에서는 아마존 세이지메이커(Amazon SageMaker) 엔드포인트를 이용해 점프스타트(Jumpstart)와 허깅페이스(Huggingface)의 다양한 LLM 들과 아마존 베드록(Amazon Bedrock)의 다양한 완전관리형 LLM들을 사용했다. 프롬프트 엔지니어링과 RAG에서는 모델의 환각을 발생시키기 위해 소규모 LLM(sLLM)을 이용해 환각을 유도했다.
프롬프트 엔지니어링의 몇 가지 다양한 접근 방식을 소개한다.
2.1.1 제로샷 프롬프트(Zeroshot Prompting)
제로샷 프롬프트(Zeroshot Prompting)는 프롬프트 엔지니어링의 주요 기법 중 하나로, 모델에게 사전에 구체적인 예시를 제공하지 않고도 특정 작업을 수행하도록 요구하는 방법이다. 이 접근법은 LLM이 높은 성능의 일반화된 학습 능력을 기반으로, 다양한 작업에 유연하게 대응할 수 있게 한다. 제로샷 프롬프트는 특히 새로운 도메인이나 작업에 빠르게 적용할 수 있어야 할 때 유용하다.
제로샷 프롬프트의 핵심은 모델에게 직관적이고 자연스러운 언어 지시를 제공함으로써, 사전에 별도의 특정 예시 없이도 모델이 작업을 이해하고 적절한 응답을 생성할 수 있도록 하는 것이다.
다음은 제로샷 프롬프트가 적용된 텍스트 분류의 예시이다.
#프롬프트
이 문장의 감정을 평가해주세요. 텍스트를 중립, 부정, 긍정으로 분류합니다.
텍스트: 모델은 괜찮은 것 같아요.
감정:
#출력
감정: 중립
제로샷 프롬프트에 명령어 조정(Instruction tuning)을 추가하는 방법도 연구되고 있다2). 명령어 조정은 모델에게 보다 구체적이고 정확한 작업 수행을 유도하기 위해 특정 작업에 대한 명령어를 세밀하게 조정하는 접근법이다. 모델이 기존의 데이터나 훈련 없이도 새로운 작업에 대해 더욱 정확하게 반응하도록 돕는다.
예를 들어 “이 문장의 감정을 분석해 주세요”라는 일반적인 제로샷 프롬프트에 “감정을 중립, 긍정, 부정 중 하나로 분류하되, 문맥상의 뉘앙스를 고려해야 합니다”라는 명령어 조정을 추가함으로써, 모델은 보다 섬세한 감정 분석을 수행할 수 있게 된다. 만약 제로샷 프롬프트가 효과적이지 않은 복잡한 지시의 경우에는 프롬프트에 구체적인 예시나 데모를 포함시켜 퓨샷 프롬프트로 전환하는 것이 좋다.
2.1.2 퓨샷 프롬프트(Few-Shot Prompt)
퓨샷 프롬프트(Few-Shot Prompting)는 LLM에 몇 가지 예제를 제공함으로써, 모델이 특정 작업을 수행하는 방법을 참조하게 하는 프롬프트 엔지니어링의 한 방식이다. 이 접근법은 모델이 제한된 수의 예시에서 효과적으로 문맥 패턴을 인식하고, 사용자 질의 요구 상황에 적용하는 능력을 향상시키기 위해 사용된다.
퓨샷 프롬프트는 특히 데이터가 부족하거나 특정 도메인에서 매우 세분화된 작업을 처리해야 할 때 유용하다. 예를 들어 모델이 특정 유형의 고객 서비스 질문에 대한 응답 방식을 참조하도록 지시하는 경우, 실제 대화에서 몇 가지 예시 응답을 보여줌으로써 모델이 이러한 유형의 질문에 더 적절하고 효과적으로 반응하도록 할 수 있다3).
다음은 퓨샷 프롬프트가 적용된 새로운 단어를 사용한 문장 생성의 예시이다.
#프롬프트
SYSTEM : 당신은 예제만을 제공해 새로운 작업을 수행하는 인공지능입니다. 예제로는 상품에 대한 리뷰가 주어지며, 당신은 이 리뷰를 기반으로 그 식당의 음식 점수를 예측해야 합니다.
제공되는 예제:
리뷰 텍스트: “이 식당에서 제공하는 스테이크는 정말 맛있습니다. 고기는 완벽하게 요리되어 있고, 소스는 풍미가 풍부합니다.”
점수: 9/10
...
리뷰 텍스트: “식당 요리는 괜찮지만 서비스가 좋지 않습니다.”
점수:
#출력
점수: 3/10
퓨샷 프롬프트는 특히 새로운 작업에 모델을 신속하게 적용하고자 할 때, 또는 특정 도메인의 데이터가 제한적인 상황에서 매우 효과적이다. 모델은 새로운 도메인의 작업을 이해하고 적응하는 데 필요한 최소한의 정보만을 활용해 높은 성능을 발휘할 수 있다. 이 기법의 핵심은 적절한 예시를 선정하는 것이다. 예시는 명확하고. 타깃 작업을 정확하게 반영해야 하며, 모델이 작업의 요구사항을 이해하고 내면화하는 데 도움을 줄 수 있어야 한다. 또한 예시는 다양성을 갖춰야 하며, 가능한 한 작업에 대한 다양한 측면을 포괄적으로 다뤄야 한다. 더 어려운 작업의 경우 10 샷(shot), 20 샷 등으로 예시를 늘려 사용해 볼 수 있다. 모델은 제공된 소수의 예제를 바탕으로 더 넓은 범위의 상황에서도 유효한 출력을 생성할 수 있다.
최근 퓨샷 프롬프트를 수행할 때, 모델에게 예제를 제공하는 것에 대한 몇 가지 팁에 대한 사례가 있다4).
● 데모에서 사용하는 입력 텍스트의 레이블 공간과 분포는 핵심적인 역할을 한다. 이는 레이블이 각 입력에 대해 정확하게 매칭되지 않더라도 전체적인 레이블 구조와 분포가 모델 학습에 크게 영향을 미치기 때문이다.
● 예제에서 사용하는 형식도 모델 성능에 결정적인 요소가 된다. 실제로 임의의 레이블을 사용하는 것만으로도 레이블을 전혀 사용하지 않는 것보다 모델의 학습 효과가 훨씬 향상된다.
● 균일한 분포보다는 실제 레이블 분포를 반영해 무작위 레이블을 선택하는 것이 모델의 일반화 능력을 향상시키는 데 도움이 된다.
이런 시도는 아래와 같다.
#프롬프트
정말 대단해요! // 부정적인
이건 나쁘잖아! // 긍정적인
이 게임 정말 재밌었어요! // 긍정적인
정말 끔찍한 쇼입니다! //
#출력
부정적인
위 형식은 예시가 일관성이 없지만 모델은 여전히 올바른 라벨을 예측했다. 어느 정도의 노이즈가 추가된 무작위 레이블 할당은 모델이 단순히 레이블에 의존하지 않고, 입력 텍스트의 실제 내용을 더 깊이 분석해 이해하는 능력과 모델이 노이즈에 대한 내성에 도움을 줄 수 있다. 이와 같은 접근 방식은 특히 실제 환경에서 데이터의 불완전성과 노이즈가 예상되는 경우에 유용할 수 있다.
퓨샷 프롬프트는 많은 작업에 적합하지만 더 복잡한 추론 작업을 처리할 때 여전히 완벽한 기술은 아니다.
퓨샷 프롬프트의 한계를 보여주는 예로, 숫자 그룹에서 홀수들의 합이 짝수인지를 판별하는 작업을 들 수 있다.
#프롬프트
입력: 홀수들의 합이 짝수인가? 4, 8, 9, 15, 12, 2, 1.
응답: 답은 False
입력: 홀수들의 합이 짝수인가? 17, 10, 19, 4, 8, 12, 24.
응답: 답은 True
입력: 홀수들의 합이 짝수인가? 17, 9, 10, 12, 13, 4, 2.
응답:
#출력
응답: True
“주어진 홀수들의 합이 짝수인가? 4, 8, 9, 15, 12, 2, 1”와 같은 예시에 대한 퓨샷은 수학적 판단이 필요한 작업으로, 대규모 언어 모델이 퓨샷 설정을 수행할 때 정확도가 떨어질 수 있다. 이는 퓨샷 프롬프트가 복잡한 계산이나 고도의 논리적 추론을 요구하는 작업에는 적합하지 않을 수 있음을 보여준다.
2.1.3 사고의 체인 프롬프트(Chain-of-Thought Prompt; COT)
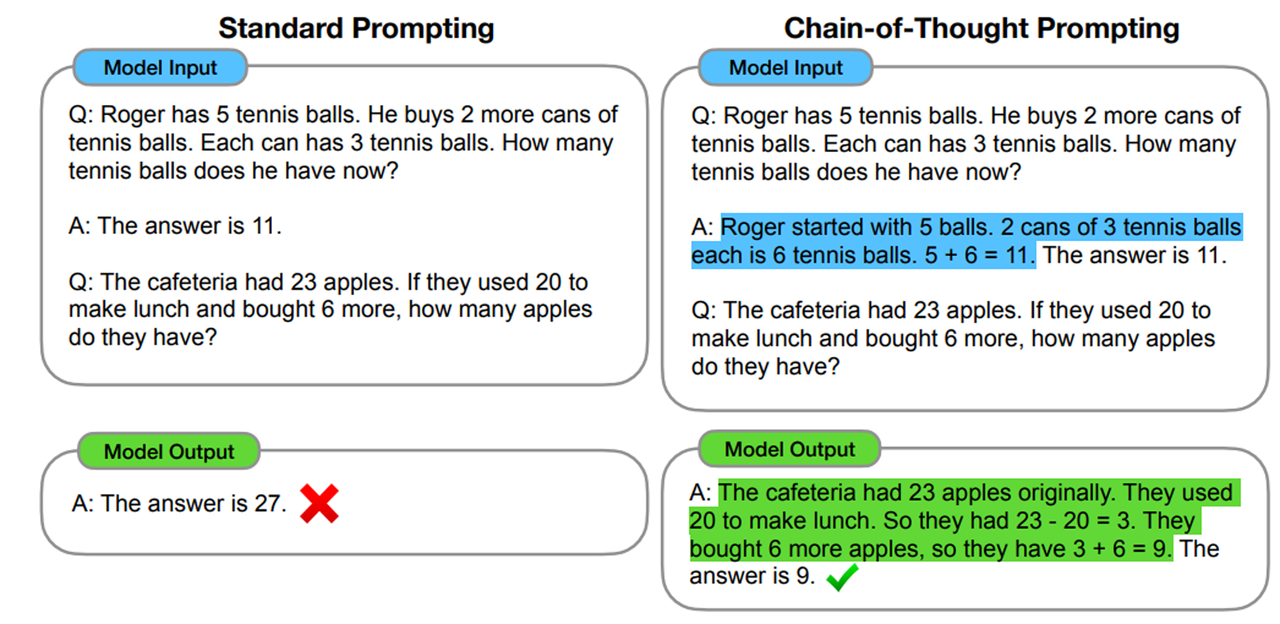
사고의 체인 프롬프트(Chain-of-Thought Prompting; COT)는 복잡한 추론 문제를 해결하기 위해 LLM을 훈련시키는 프롬프트 엔지니어링의 고급 기법 중 하나이다. 이 방법은 모델에게 문제 해결 과정에서 발생할 수 있는 사고의 단계를 연속적으로 기술하도록 요구함으로써, 모델이 더 깊이 있는 추론을 수행하고 정확한 답변을 도출할 수 있도록 한다4). 마치 방정식의 해를 찾기 위한 과정에서 대수학적 풀이 과정을 모델에게 프롬프트 예제로 제시하는 것과 유사하다.
#프롬프트
입력: 홀수들의 합이 짝수인가? 4, 8, 9, 15, 12, 2, 1.
응답: (9, 15, 1의 합은 25, 홀수), 답은 False
입력: 홀수들의 합이 짝수인가? 17, 10, 19, 4, 8, 12, 24.
응답: (17, 19의 합은 36, 짝수), 답은 True
입력: 홀수들의 합이 짝수인가? 17, 9, 10, 12, 13, 4, 2.
응답:
#출력
응답 : (17, 9, 13의 합은 39, 홀수), 답은 False
질의응답 프로세스에서 모델은 각 단계를 명확하게 설명하면서 최종 답변에 도달하게 된다. 사고의 체인 프롬프트는 모델이 보다 정교하고 사려 깊은 방식으로 문제를 접근하게 만들며, 모델의 해석 가능성과 사용자의 신뢰도를 높일 수 있는 방법이다.
최근 재미있는 방법으로 제로샷 사고의 체인 프롬프트라는 아이디어가 있다5). 기존의 LLM들의 문제 해결 능력을 높이기 위해 대수학적 원리를 적용한 도메인 문장 학습이 진행되면서 원래의 프롬프트에 “단계적으로 생각해 봅니다” 또는, “순서대로 생각해서 대답해 주세요”와 같은 문장을 마지막에 추가하는 것이다.

아래는 LLM에 제로샷 사고의 체인 프롬프트 질의 테스트에 대한 예시이다. 최근 모델들은 상향 평준화돼 있기 때문에 이런 환각을 확인하려면 sLLM에서 테스트해보는 것을 추천한다.
#프롬프트
나는 마트에 가서 음료수 12개를 샀습니다. 음료수 2개는 부모님에게, 4개는 친구에게 주었습니다. 그리고 다시 마트에 가서 음료수 5개를 더 사서 1개를 먹었습니다. 음료수는 몇 개나 남았나요?
#출력
응답: 12개 음료수
이제 “단계적으로 생각해 봅니다”를 추가해 보면 아래와 같은 답변을 하는 것을 확인할 수 있다.
#프롬프트
나는 마트에 가서 음료수 12개를 샀습니다. 음료수 2개는 부모님에게, 4개는 친구에게 주었습니다. 그리고 다시 마트에 가서 음료수 5개를 더 사서 1개를 먹었습니다. 음료수는 몇 개나 남았나요?
단계적으로 생각해봅니다.
#출력
처음 구매: 마트에서 음료수 12개를 구매했습니다.
분배: 부모님에게 2개, 친구에게 4개를 습니다. 따라서 12 - 2 - 4 = 6개가 남습니다.
추가 구매 및 소비: 다시 마트에 가서 음료수 5개를 추가로 구매하면 총 음료수는 6 + 5 = 11개가 됩니다. 그 중 1개를 마셨으므로, 11 - 1 = 10개가 남습니다.
결과적으로, 음료수는 10개가 남았습니다.
이 간단한 마지막 문장을 붙여 주는 것으로 최근 LLM들의 응답 출력이 보다 정확해진다는 점이 흥미로웠다. 아마도 논리적인 문장의 흐름에 대한 사전 학습 문장을 구성해 학습이 진행됐기 때문으로 추정된다.
2.1.4 프롬프트 체인(Prompt Chain)
프롬프트 체인(Prompt Chain)은 프롬프트 엔지니어링에서 복잡한 작업을 효과적으로 수행하기 위해 사용되는 방법이다. 여러 연속된 프롬프트를 활용해 LLM이 각 단계에서 생성한 출력을 그다음 단계의 여러 다른 입력으로 사용하게 함으로써, 전체적인 문제 해결 과정을 다양하게 개선하는 데 초점을 맞춘다6).
프롬프트 체인은 특히 복잡하거나 여러 단계를 요구하는 작업에 적합하다. 각 단계는 작업을 분할해 처리 가능한 부분으로 나누고, 이러한 각각의 부분이 최종 결과에 기여하는 방식으로 구성된다. 이 방식은 프롬프트의 명확한 질의로 쪼개서 작업을 더 관리하기 쉽게 만들며, 각 단계에서의 결과를 검토하고 조정함으로써 최종 출력의 정확성을 높일 수 있는 장점이 있다.
예를 들어 복잡한 데이터 분석 요구사항을 해결하기 위해 첫 번째 프롬프트에서는 데이터를 수집하고 정리하는 작업을 수행하고, 두 번째 프롬프트에서는 정리된 데이터를 분석해 통찰력을 도출하며, 세 번째 프롬프트에서는 이러한 통찰력을 바탕으로 보고서를 작성하는 방식이다.
프롬프트 체인의 주요 이점은 다음과 같다6).
● 상세한 작업 분할: 복잡한 작업을 단순화하고, 각 단계를 명확하게 정의해 실행
● 결과 검증 및 개선: 각 단계의 출력을 검토하고 필요에 따라 개선함으로써 최종 결과의 정확성을 보장
● 효율성 향상: 각 프롬프트가 특정 작업에 집중함으로써 전체 프로세스의 효율성을 높임
아래는 아마존 배드록의 클로드 모델(Amazon Bedrock Claude Sonet)을 이용한 예시이다6).
프롬프트의 목표는 클로드(Claude)가 먼저 개요를 만든 다음 전체 설명으로 확장해 세 가지 다른 수준(1학년, 8학년, 대학 신입생)의 독자에게 개념을 설명하도록 하는 것이다.
#프롬프트 1: 각 읽기 수준마다 하나씩, 세 가지 다른 버전의 개요 만들기
USER :
다음은 컨셉입니다. {{CONCEPT}}
이 수준의 독자에게 적합한 이 컨셉에 대한 에세이의 세 문장 개요를 작성해 주시기 바랍니다. {{LEVEL}}
한 줄에 한 문장씩 개요로만 응답해 주세요. , <outline></outline> XML 태그에 있습니다. 다른 말은 하지 마세요.
#프롬프트 2: {{OUTLINE}}프롬프트 1의 출력 사용, 읽기 당 하나씩 개요를 사용해 전체 문단 만들기
USER:
개요는 다음과 같습니다.
<outline>{{OUTLINE}}</outline>
개요의 각 문장을 한 단락으로 확장해 주세요. 각 문장을 단어별로 사용해 해당 단락의 첫 번째 문장으로 사용하세요.
이 유형의 독자에게 적합한 수준({{LEVEL}})으로 작성하세요.
프롬프트 체인은 특히 프로젝트 관리, 과학 연구, 복잡한 내용의 글쓰기 등 다양한 분야에서 유용하게 사용할 수 있다6). 또한 외부 데이터의 검색 증강 생성을 위한 LLM 질의의 응답 세분화로 사용할 수 있다. 프롬프트 체인을 사용함으로써, LLM은 각 단계를 거치면서 점진적으로 문제에 대한 해결책을 구체화하고, 최종적으로는 보다 정교하고 완성도 높은 결과물을 생산할 수 있다.
2.2 검색 증강 생성 (Retrieval-Augmented Generation; RAG)
최근 기업들이 보유하고 있는 독점적인 데이터로 LLM을 강화할 수 있다는 사실을 깨달은 이후 LLM의 일반 지식과 독점 데이터 사이의 격차를 가장 효과적으로 메우는 방법에 대한 논의가 이뤄지고 있다. 전통적으로 신경망 모델은 학습 데이터들을 파인튜닝해 도메인별 또는 독점 정보에 맞게 튜닝했다. 파인튜닝은 효과적이지만 계산 집약적이며 비용이 많이 들고 기술 전문 지식이 필요하므로 변화하는 정보에 적응하는 민첩성이 떨어지는 편이다.
이에 대한 대안으로 2020년 루이스(Lewis)7) 등에 의해 제안된 RAG는 생성 모델과 검색 모듈을 결합해 외부 지식원에서 추가 정보를 쉽게 업데이트하고 제공할 수 있는 방법을 소개했다.
● 파라미터 지식: 파인튜닝 같은 모델 학습 중 업데이트되며 신경망 가중치에 암시적으로 저장됨.
● 비 파라미터 지식: RAG에서 사용하며 벡터 데이터 베이스와 같은 외부 지식 저장소에 저장됨.
RAG는 최근 LLM의 정확도와 맥락을 개선하기 위한 혁신적인 기법이다. 기존의 LLM은 방대한 데이터에 기반해 일반적인 지식을 학습하지만, 항상 최신이거나 특정 도메인에 특화된 정보를 포함하고 있는 것은 아니다. 특히 훈련 데이터에 포함되지 않은 최신 또는 도메인 특화되거나 독점적 정보를 요구하는 질문에 대해 오류가 발생하기 쉽다. 예컨대 “2022년 미국 인플레이션율은 몇 퍼센트였나요?”와 같은 질의에 대해 LLM의 문제는 모델이 실시간 정보나 도메인 특화 지식 없이는 정확한 답변을 생성하기 어렵다는 점에서 비롯된다8).
검색 증강 생성의 워크플로우는 다음과 같다.
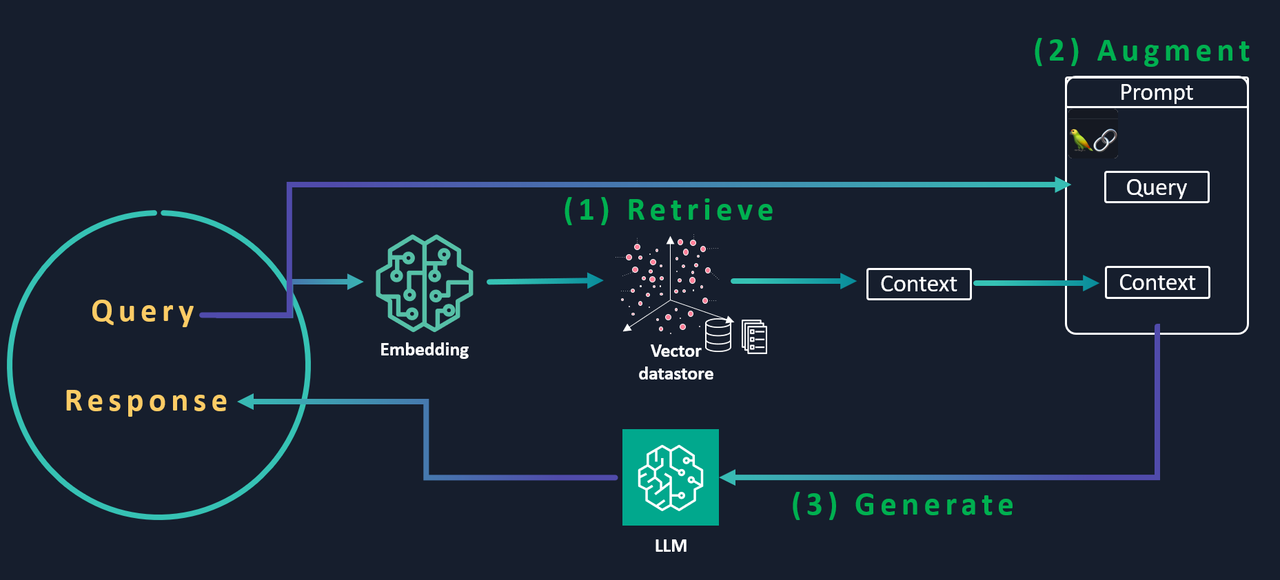
● 검색(Retrieve): 사용자의 질의를 기반으로 외부 데이터 소스에서 관련 컨텍스트를 검색하며 질의는 벡터 데이터베이스의 추가 컨텍스트와 동일한 벡터 공간으로 임베딩돼 유사성 검색을 수행하고 가장 관련성 높은 데이터를 반환한다.
● 증강(Agument): 검색된 추가 컨텍스트와 사용자 질의를 프롬프트 템플릿에 저장한다.
● 생성(Generate): 검색 증강 프롬프트를 LLM에 제공해 최종적인 응답을 생성한다.
아래 그림은 아마존 세이지메이커와 아마존 켄드라(Amazon Kendra)를 활용한 일반적 RAG의 예시이다8).
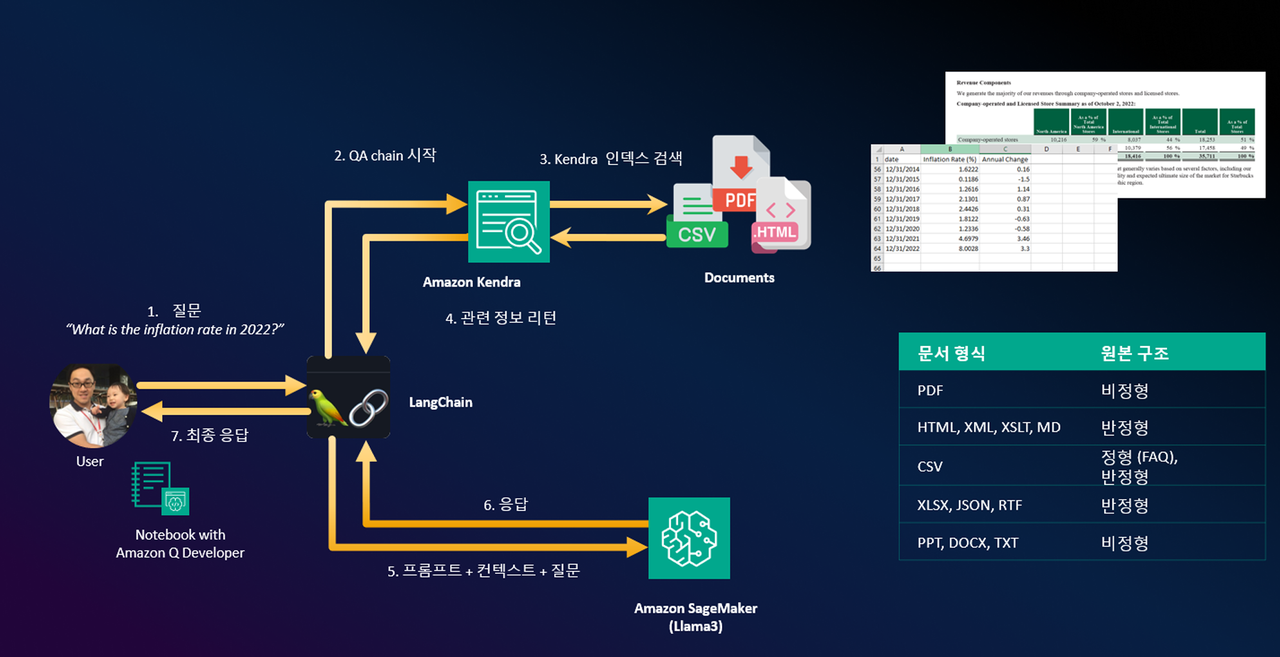
아마존 세이지메이커에서 엔드포인트 API로 배포한 Llama3-8B-Instruct sLLM 모델만을 이용해 “2022년 미국 인플레이션율은 얼마인가요?”라고 질의하면 6.5%라고 언급하지만 실제 미국 2022년 인플레이션율9)은 8.00%였다. 아마존 켄드라에 1960~2024년 미국 인플레이션율에 대한 웹사이트 데이터를 크롤링하고, 전 처리한 CSV 파일을 S3에 저장한 다음 켄드라가 벡터 데이터로 사용하도록 구성했다. 그다음 동일한 질문을 하면 아마존 켄드라에서 검색된 인플레이션율 정보가 컨텍스트로 프롬프트 구성되고 관련 정보가 Llama3-8B-Instruct 모델로 전달되도록 구성했다.
최종 응답은 “문서에 따르면 2022년 미국의 인플레이션율은 8.00%였고, 이건 2021년보다 3.3% 증가한 수치입니다”라는 정확한 답변을 했다. 벡터 검색 저장소의 경우 다양한 이기종 비정형 데이터의 타입을 저장할 수 있어야 하며 질의에 따라 각각의 저장소를 검색하도록 테이블을 분리해야 한다. 아마존 켄드라는 50여 가지 데이터 커넥트 인터페이스를 가지고 있고, 하나의 인덱스에서 서로 다른 타입의 카테고리 비정형 데이터 파일을 생성형 AI 기술을 활용해 자동 인덱스 검색 처리하기 때문에 검색 적용하기 쉬운 편이다.
2.2.1 RAG에서 프롬프트 엔지니어링의 중요성
RAG를 효과적으로 활용하기 위해서는 검색과 증강 과정에서 프롬프트 엔지니어링 기법의 적절한 적용이 필수적이다. RAG에서 벡터 데이터 저장소에서 검색된 컨텍스트를 모델 입력에 효과적으로 통합해 최종 출력의 정확도와 관련성을 크게 향상시키는 기술이 필요하기 때문이다. RAG에서 증강 부분의 프롬프트 엔지니어링은 검색된 정보를 LLM이 처리할 수 있는 형태로 변환하고, 이 정보를 활용해 보다 정확한 답변을 생성할 수 있도록 돕는다.
아래는 LLM이 CS센터 직원처럼 친절하게 대답하도록 페르소나를 지시하고 아마존 오픈서치(Amazon Opensearch)에서 검색된 정보를 재구성한 뒤 요약 응답하도록 처리한 설계 예시이다.
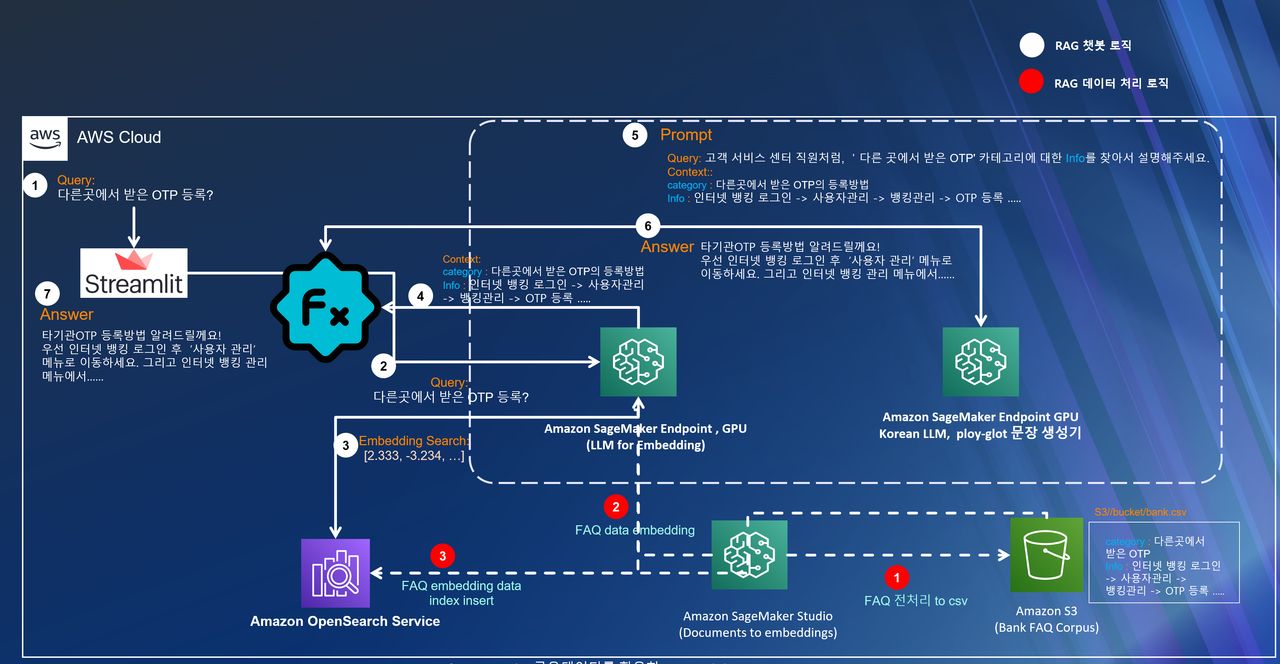
증강 부분에서 검색된 컨텍스트를 모델의 프롬프트에 어떻게 증강할지 결정하는 것은 RAG 시스템의 성공에 결정적인 요소다. 잘 설계된 프롬프트는 LLM이 제공된 정보를 최대한 활용해 정확한 결과를 도출할 수 있게 만들며, 잘못된 정보 추론이나 데이터의 오해를 말하지 않도록 미연에 방지할 수도 있다. 따라서 효과적인 프롬프트 설계는 RAG의 핵심 구성 요소로서, 모델의 성능을 최적화하고 실제 적용 시의 유용성을 보장한다.
2.2.2 고급 검색 증강 생성(Advanced Retrieval-Augmented Generation)
검색 증강 생성은 LLM의 성능 이전에 외부 저장소에서 검색하는 질의 처리 결과에 따라 프롬프트로 구성할 수 있는 데이터의 질에 영향을 받는다. 최근 이런 일반적인 RAG의 한계를 해결하는 것을 목표로 하는 고급 검색 증강 생성(Advanced Retrieval-Augmented Generation; Advanced RAG) 방법론이 제시되고 있다.
고급 검색 증강 생성은 검색 증강 생성 기법의 진화된 형태로, 일반적인 RAG의 한계를 극복하고자 다양한 최적화 기법을 적용한 접근 방식이다. 고급 검색 증강 생성은 검색 부분을 ‘사전 검색’, ‘검색’, ‘사후 검색’ 단계에서 각각의 최적화를 실시해 정보의 정확성과 처리 효율을 크게 향상시키는 것을 목표로 한다.
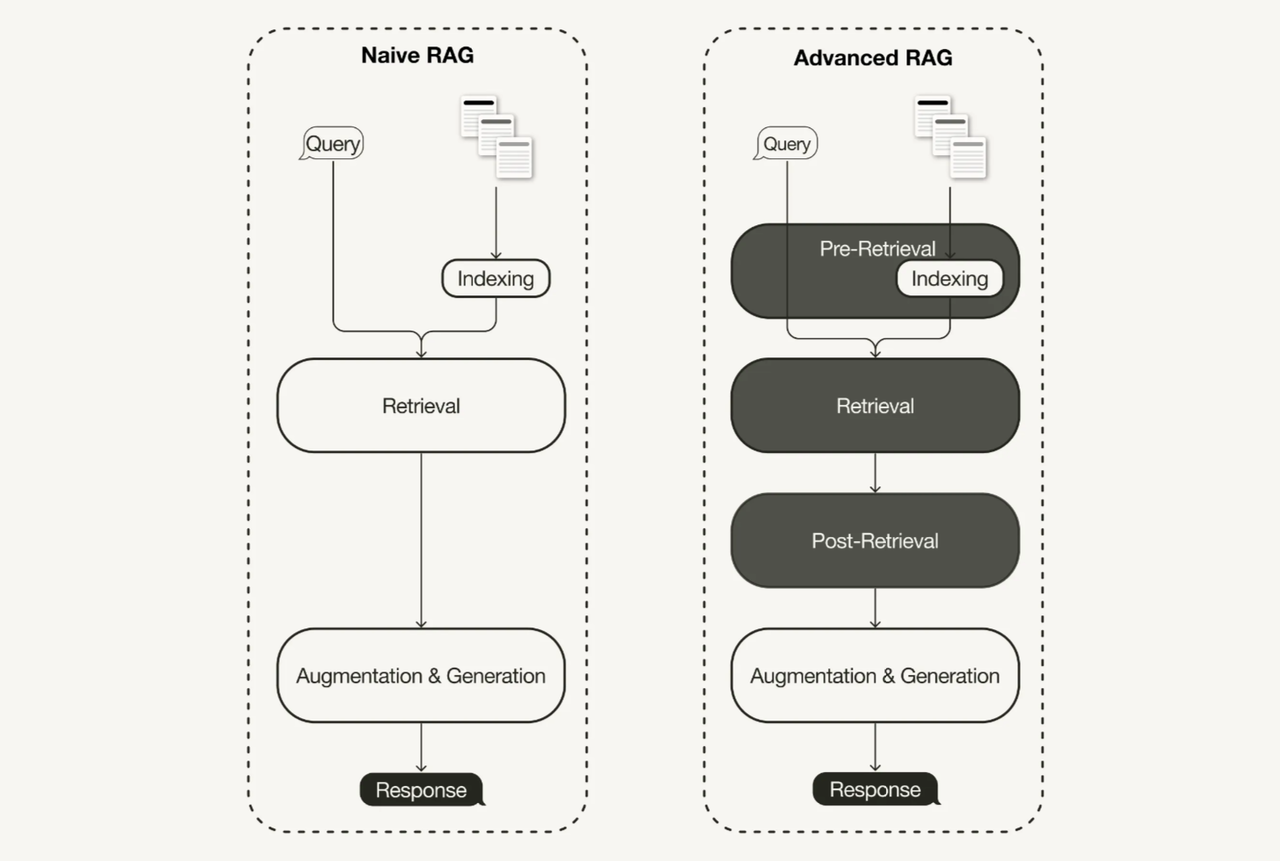
검색 전 최적화
사전 검색 최적화는 데이터 인덱싱과 쿼리 최적화에 중점을 둔다. 데이터 인덱싱 최적화는 데이터를 효율적으로 검색할 수 있도록 저장 구조를 개선하는 여러 기법을 포함한다.
예를 들어 벡터 데이터 베이스에 데이터를 토크나이징할 때, 입력 데이터의 청크 슬라이딩 윈도우 기법은 데이터 청크 사이에 중복을 허용해 검색 효율을 높이는 방법이다.
아래 그림과 같이, 문단이나 단일 문장으로 분리한 컨텍스트 창을 3으로 지정한다면 결과 창은 포함된 문장의 이전 문장에서 시작해 뒤의 문장에 걸쳐 세 문장 길이가 된다.
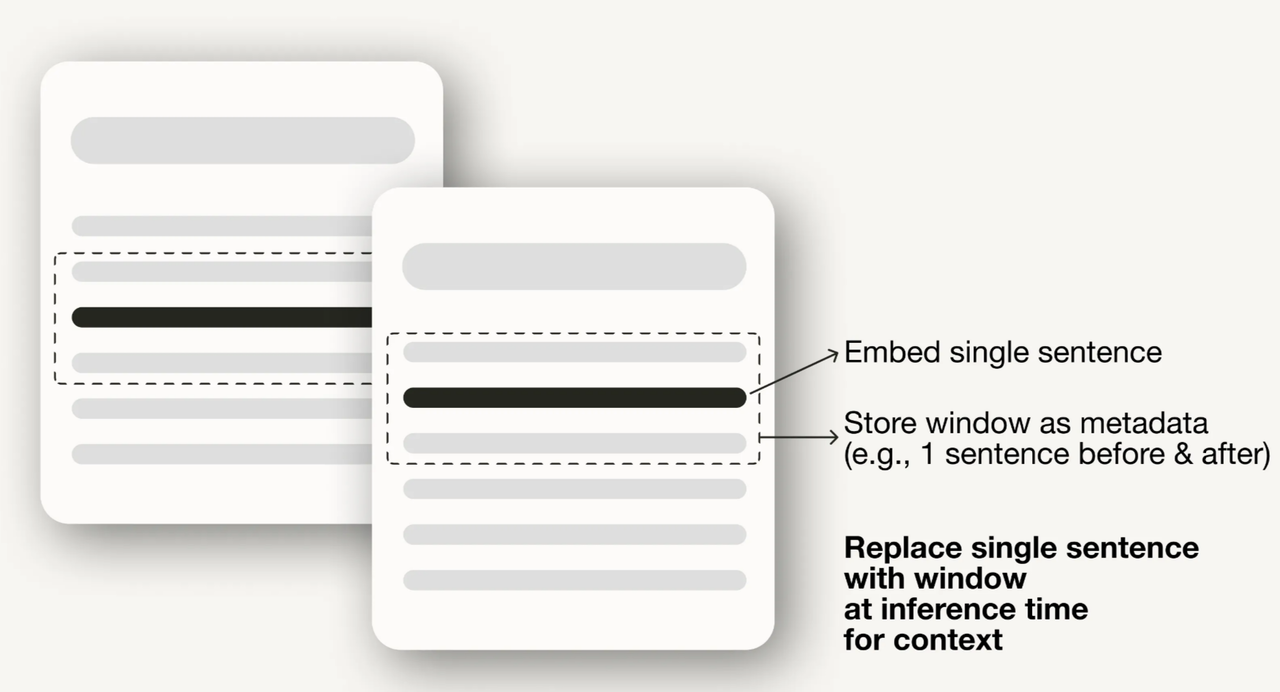
검색하는 동안의 질의와 일치하는 문장의 앞뒤를 확인하며 검색할 수 있다. 또한 데이터의 세분화를 통해 불필요한 정보를 제거하고 사실 정확성을 확인하는 등의 데이터 클리닝 기법이 적용된다. 또한 청크 데이터를 추가하면서 필터링 목적으로 날짜나, 팀 이름, 문서의 카테고리 등을 메타데이터로 추가하는 방법도 있다.
검색 최적화
검색 단계에서는 질의와 인덱싱된 데이터 간의 의미적 유사성을 계산해 가장 관련성 높은 컨텍스트를 식별하는 과정이다. 이 단계의 최적화 기법으로는 임베딩 모델의 파인튜닝이 될 수 있으며, 특히 도메인 특화적 컨텍스트에 맞게 튜닝돼 더욱 정확한 검색 결과를 제공한다. 예를 들어 기업의 고유명사나 도메인 특화 희귀한 영어가 있는 경우 도메인별 컨텍스트에 맞게 임베딩 모델을 사용자 정의 후 파인튜닝하는 과정도 검색 최적화에 포함된다.
하이브리드 검색은 벡터 검색과 키워드 기반 검색을 결합해 특정 키워드가 정확히 일치해야 하는 검색 요구에 효과적이다. 아래 그림은 하이브리드 검색처리에 대한 예시이다.
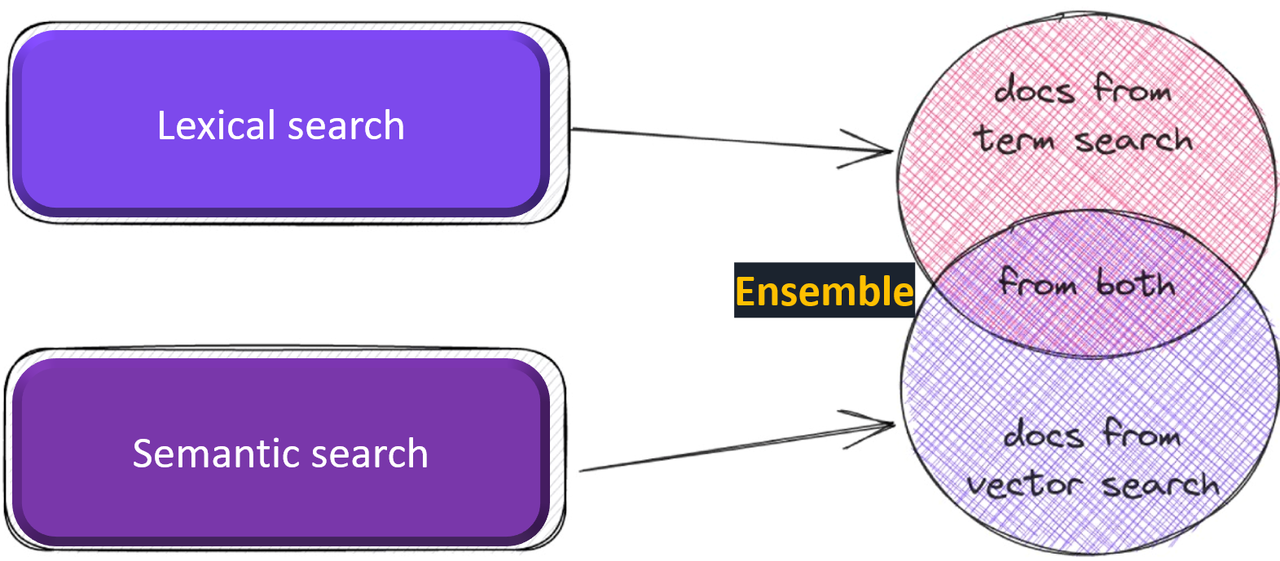
렉시컬 서치는 텍스트 기반 전통적 검색 방식으로, 의미 기반 검색의 단점을 채워줄 수 있다.하나의 쿼리에 대해 시멘틱과 렉시컬 검색을 동시에 수행하는 하이브리드 검색 방법은 보다 나은 RAG 검색 성능을 개선할 수 있다. 아마존 오픈서치를 활용해 두 가지 검색 방식을 모두 지원해 시너지 효과를 거둘 수 있다.
검색 후 최적화
사후 검색 최적화 기법으로는 프롬프트 압축과 재순위(re-ranking) 부여가 있다. 프롬프트 압축은 불필요한 컨텍스트를 제거하고 중요한 정보를 강조해 전체 프롬프트의 길이를 줄이는 방법이다. 반면, 재순위 부여는 검색된 컨텍스트의 관련성 점수를 재계산해 더욱 정확한 결과를 도출할 수 있도록 한다. 아래 그림은 재순위 부여에 대한 예시 그림이다.
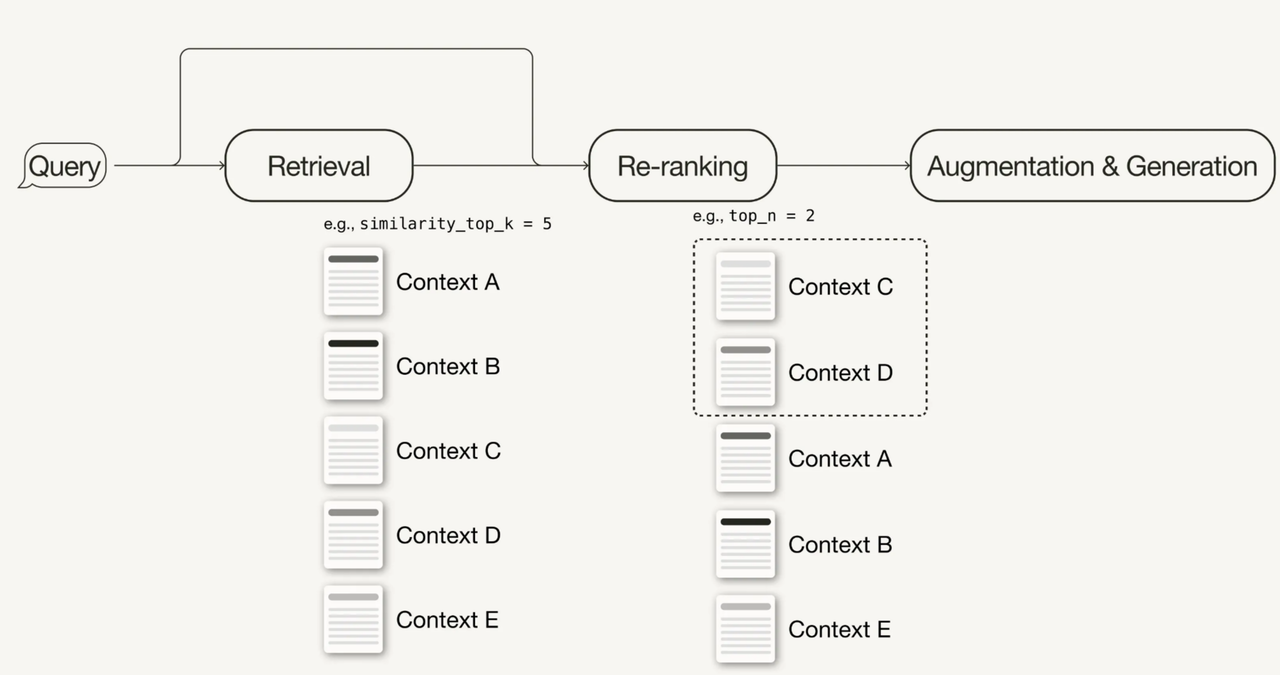
재순위 부여의 기본 원리와 접근 방법은 아래와 같다.
● 초기 검색 단계: 사용자의 질의에 기반해 초기 검색이 수행, 이때 벡터 데이터베이스나 다른 검색 엔진을 사용해 문서나 데이터 조각들이 검색된다.
● 초기 순위화: 초기 검색 결과는 질의어와 벡터 데이터의 유사성 점수(similarity score)를 기준으로 일반적으로 순위가 매겨진다. 이 점수는 질의와 문서 사이의 거리 또는 유사성을 기반으로 계산된다.
● 재순위화를 위한 데이터 선택: 재순위 부여 과정에서는 초기 순위화된 목록에서 상위에 위치한 항목들을 선택해 더 세밀한 평가를 진행한다. 이 과정에서 LLM 모델이나 추가적인 규칙 기반의 로직을 적용할 수 있다.
● 재순위 부여 알고리즘 적용: 선택된 데이터는 다양한 기준에 따라 재평가한다. 이 기준에는 문맥적 적합성, 정보의 신선도, 사용자 행동 데이터, 문서의 권위성 등이 포함될 수 있다. 프롬프트 체인을 통해 다음 프롬프트는 LLM에 전달되며, 검색된 각 항목의 새로운 순위 점수를 계산하고, 이를 기반으로 최종적인 순위를 다시 매긴다.
● 최적화된 결과 제공: 재순위화된 결과는 최종 사용자에게 제공된다. 이 결과는 초기 검색보다 훨씬 더 정확하고 개인화된 응답을 제공할 수 있다.
재순위 부여의 장점은 정보의 정확성과 관련성을 크게 향상시킬 수 있다는 점이다(13). 특히 복잡한 질의에 대해 다양한 데이터 소스에서 검색된 결과를 통합할 때 유용하다. 또한 LLM이 검색된 정보를 더 잘 이해하고 활용하도록 재귀적으로 프롬프트 체인을 실행한다.
사후 최적화 작업은 고급 RAG에서 검색된 정보를 보다 효과적으로 LLM에 통합해 더 정확하고 관련성 높은 출력을 생성할 수 있도록 만든다.
고급 RAG는 특히 복잡하거나 최신 정보를 필요로 하는 질의에 대해 탁월한 성능을 보여줄 수 있다.
예를 들어 최신 금융 데이터나 특정 과학적 주제에 관한 최근 연구 결과를 포함해 질의응답 시스템을 구축할 때, 고급 RAG는 LLM이 기존에 학습한 일반적 지식 외에도 실시간으로 업데이트된 데이터를 활용해 응답을 구성할 수 있게 돕는다. 이는 특히 급변하는 시장 조건이나 과학적 발견이 중요한 분야에서 매우 유용할 수 있다.
따라서 고급 RAG의 구현은 LLM의 활용 범위를 확장하고, 모델의 적용성과 정확성을 향상시키는 중요한 전략이다.
3. 결론
생성형 AI 중 LLM은 AI 기술의 최전선에서 혁신을 이끌고 있으며, 지금도 그 가능성은 무궁무진하다. 이 글에서는 LLM의 한계를 극복하기 위해 제안되고 있는 다양한 기술들을 소개했다. 프롬프트 엔지니어링, RAG, 고급 검색 증강 생성과 같은 기술들은 AI 모델의 정확도를 향상시키고, 환각을 줄이며, 특정 도메인에 대한 적용성을 높이는 데 중요한 역할을 한다. 이 기술들은 LLM을 실제 세계의 문제 해결에 더욱 효과적으로 활용할 수 있게 만들어, 실용적인 애플리케이션에서의 그 가치를 크게 높일 것이다.
또한 고급 검색 증강 생성과 같은 최신 기술은 일반적인 RAG의 패러다임을 극복하고 LLM이 다양한 데이터 소스로부터 얻은 지식의 검색을 보다 잘 활용할 수 있게 함으로써, 모델의 적용 범위를 넓히고 사용자에게 더 정확하고 신뢰할 수 있는 정보를 제공할 수 있도록 돕는다. 이는 특히 빠르게 변화하는 금융 시장이나 최신 IT, 제조 과학 연구와 같은 엔터프라이즈 영역에서 매우 중요하다.
RAG에서 프롬프트 엔지니어링을 세밀하게 조율하고 결합하는 것은 특히 생성형 AI 애플리케이션의 품질을 높이는 데 효과적인 전략이며, LLM은 다양한 질의에 대해 더 정확한 답변을 제공하고, 사용자의 의도와 맥락을 더 잘 이해할 수 있을 것이다.
앞으로 생성형 AI의 기술의 발전은 지금보다 가속화될 것이며, LLM의 구조를 이해하고, 적절히 활용한다면 여러분의 LLM은 더욱 강력한 도구로 자리 잡을 수 있을 것이다.
참조
1) 전현상, “현업에서 어텐션 기반 트랜스포머의 적용과 Generative AI의 동향”, 2023 NRIC 메릭 웨비나, 과학기술정보통신부, 2023.
2) Wei et al, Google Research, “FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS”, in Proceedings of the International Conference on Learning Representations (ICLR), 2022.
3) Brown, et al. “Language Models are Few-Shot Learners” OpenAI
4) Min, et al. “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022).
5) Kojima, et al. “Large Language Models are Zero-Shot Reasoners” In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022).
6) Claude, Anthropic. “Chain prompts - PROMPT ENGINEERING”, https://docs.anthropic.com/en/docs/chain-prompts#when-to-use-prompt-chaining
7) Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” Facebook AI Research and University College London, New York University.
8) 전현상, 곽영화. “데이터 인사이트의 혁신: Amazon AI 서비스 활용법” : 생성형 AI 기반 기술 혁신 세션, AWS Summit Seoul, 2024.
9) “U.S. Inflation Rate 1960-2024” Macrotrends.,https://www.macrotrends.net/global-metrics/countries/USA/united-states/inflation-rate-cpi.
10) aws-samples. “금융 데이터를 활용한 RAG Workshop” GitHub repository, https://github.com/aws-samples/aws-ai-ml-workshop-kr/tree/master/genai/aws-gen-ai-kr/20_applications/04_rag_finance_opensearch_sllm_workshop.
11) Leonie. “Advanced Retrieval-Augmented Generation: From Theory to LlamaIndex Implementation” Towards Data Science.
12) 문곤수, “클라우드 기반의 생성형 AI Application 프러덕션 전략 및 AWS 생성형 AI 기술과 사례”, 2024 Gen Con: Super Human Powered by AI, 2024.
13) 전현상, “클라우드 환경에서 생성형 AI의 미래 전략과 AWS 생성형 AI 기술과 사례”, 2024 클라우드 컨퍼런스⑨, ITDAILY, 2024.