


구글·네이버 등에 중요 개인정보 침해 최소화 지시
[아이티데일리] 개인정보보호위원회(위원장 고학수)는 지난 27일 제6회 전체회의를 열고, 거대언어모델(Large Language Model, LLM)을 개발‧배포하거나 이를 기반으로 인공지능(AI) 서비스를 제공하는 6개 사업자에 대해 개인정보 보호의 취약점을 보완하도록 개선 권고를 의결했다고 밝혔다.
개인정보위는 초거대‧생성형 AI 서비스의 급속 확산으로 프라이버시 침해 우려가 증대됨에 따라, 국민 불안의 조기 해소와 안전한 서비스 활성화를 위해 지난해 11월부터 한국인터넷진흥원(원장 이상중)과 함께 주요 AI 서비스를 대상으로 사전 실태점검을 진행했다.
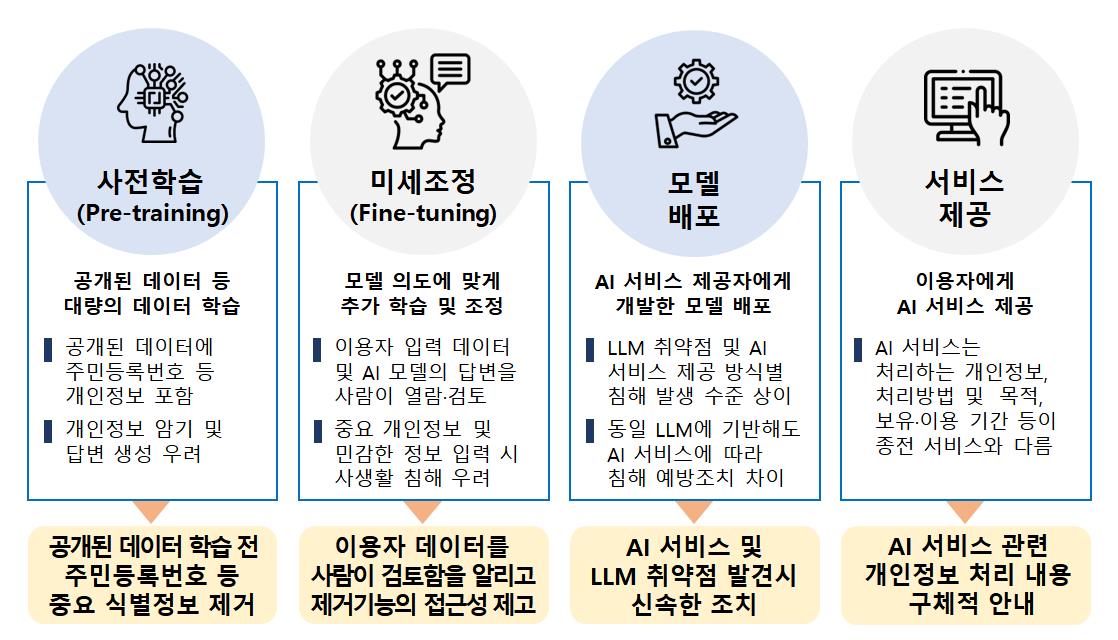
AI 단계별 개인정보 보호의 취약점 점검 결과, 전반적으로 개인정보 처리방침 공개, 데이터 전처리, 정보 주체의 통제권 보장 등 보호법상 기본적 요건을 대체로 충족했으나, 세부적으로 △공개된 데이터에 포함된 개인정보 처리 △이용자 입력 데이터 등의 처리 △개인정보 침해 예방‧대응 조치 및 투명성 등 관련해 일부 미흡한 사항이 발견됐다.
우선, AI 모델 학습데이터에 중요 개인정보가 포함될 수 있는 것으로 나타났다. 업체들은 인터넷에 공개된 데이터를 모델 학습에 활용하는데, 이 과정에서 주민등록번호, 신용카드번호 등이 유출될 우려가 있는 것이다.
오픈AI, 구글, 메타는 개인정보 집적 사이트를 AI 모델 학습에서 배제하고, 학습데이터 내 중복 및 유해 콘텐츠 제거와 AI 모델이 개인정보를 답변하지 않도록 하는 조치는 적용하고 있으나, 학습데이터에서 주민등록번호 등 주요 식별정보를 사전 제거하는 조치가 충분하지 않은 것으로 확인됐다.
이에 개인정보위는 AI 서비스 제공 단계별 보호조치 강화를 요구하는 한편, 최소한 사전 학습단계(pre-training)에서 주요 개인식별정보 등이 제거될 수 있도록 인터넷에 국민의 개인정보가 노출된 것을 탐지한 데이터(URL)를 기업에 제공할 계획이다.
또한 개인정보위는 이용자 질문 및 모델 답변 내용을 열람해 데이터셋을 구성하고 있으나, 개인정보 및 이메일 등 민감한 내용을 제거 조치 없이 DB화할 경우 사생활 침해로 이어질 위험이 있다고 지적했다.
아울러 AI 서비스와 관련된 내용을 종합해 개인정보 처리방침 등에 보다 구체적으로 안내하고 부적절한 답변에 대한 신고 기능을 반드시 포함하는 것은 물론, AI 서비스 및 LLM의 취약점 발견 시 신속히 조치할 수 있는 프로세스도 갖추도록 개선 권고했다.

한편, 이번 AI 점검은 ‘개인정보 보호법’ 개정으로 개인정보 보호의 취약점을 선제적으로 해소하기 위해 도입된 사전 실태점검 제도를 민간 부분에 처음으로 적용한 사례다.
개인정보위는 향후 AI 모델의 고도화, 오픈 소스 모델의 확산 등 새로운 기술‧ 산업 변화에 맞춰 정보주체의 개인정보를 안전하게 보호할 수 있도록 지속적인 모니터링과 함께 AI 관련 6대 가이드라인 등의 정책방향 마련, 개인정보 강화 기술(PET, Privacy Enhancing Technologies) 개발‧보급 등의 후속 조치를 추진할 계획이다.