


데이터스트림즈 김현철 제품사업본부장

[아이티데일리] 데이터를 관리하고 분석하는 ‘데이터 리더’가 비즈니스 지원기능을 수행하는 기능직에서 자체 손익 목표를 갖는 조직 내부의 컨설턴트로 발전하고 있다.
과거 데이터를 일단 모으거나(Collect: Lake, Mart, ODS, Warehouse) 혹은 연결(Connect: Virtualization, Event Store, Replication, Sync)하면 어떻게든 데이터의 역할은 다한 것으로 여기던 시절이 있었다. 그러나 이제는 ‘데이터 리더’가 별도의 독립적인 비즈니스 조직에서 핵심 통찰력을 제공하는 가치 중심·활용 중심의 데이터 전략을 수립하는 것이 대세가 되었다.
이처럼 데이터 시장의 흐름이 바뀌고 있는 가운데 미국 IT 시장조사 전문 기업 가트너그룹(Gartner Group)은 매년 미국 올랜도를 시작으로 호주 시드니, 영국 런던, 인도 뭄바이, 일본 도쿄 등에서 ‘Gartner Data & Analytics Summit’을 개최하며 글로벌 데이터 시장의 트렌드를 제시하고 있다.
올해도 지난 3월 미국 올랜도에서 ‘Gartner Data & Analytics Summit 2023’이 열렸다. 4,600여 명의 데이터 관리 & 분석가들과 130여 개의 데이터 관련 기업들이 참석한 이번 행사에서 150여 전문가 세션과 1:1미팅, 워크샵을 통해 Data & Analytics 2023 트렌드를 5가지 핵심 주제로 제시했다.
첫째, 데이터는 이제부터 디지털 비즈니스 성공 창출을 위해 역할을 해야 한다. 이를 위해서 기술을 조직의 전략적 미션과 연결시키고 비즈니스 언어로 우리가 가진 내적 동기와 가치를 연결하는 이야기를 만들어 내야 한다. 이와 관련, 가트너는 키노트 주제로‘Lead for Purpose, Connect with Trust, Make an Impact’를 선정하고 세미나를 진행했다.
둘째, 다양한 역량을 가진 인재들을 유치하고 필요한 역량과 기술을 연마시켜야 한다. 이는 기존의 데이터 관련 기술을 넘어 즉시 사용 가능한 다양한 잠재역량을 확보해야 하며 전문가들이 자유롭게 일할 수 있는 유연한 문화를 조성하는 것을 포함해야 한다. 데이터는 기술도 기술이지만 그 데이터를 해석해 낼 수 있는 역량이 더 중요하다.
셋째, AI 기술의 과도한 오해를 불식시키고 바른 사용 환경을 구축해야 한다. 이를 위해 AI로 해결해야 할 과제를 정리하고 관련 기술을 교육하며 전파하고 전문가를 양성해야 한다. 데이터 분석과제에 AI전문가들을 참여시키고 가능한 기술을 아웃소싱하도록 해야 한다.
넷째, 데이터 생태계(Data Eco-system)를 이해하고 실제적인 데이터 패브릭을 구축해야 한다. 데이터 발생부터 수집, 접속 및 사용 전체 종단 간 최고의 전략을 사용하고 있는지 기존의 데이터 아키텍처를 재평가해야 한다. 데이터 환경이 내부 데이터의 적재, 가공, 재사용을 넘어서 외부 데이터와 공유를 포함한 새로운 영역으로의 확대를 고려하는 데이터 패브릭 구조를 기업에 구축해야 한다.
다섯째, 데이터 기반의 의사결정이 원활하게 이루어지기 위해서는 차별화 된 경쟁 요소가 반영된 최적의 환경이 구축되어야 한다. 데이터 기반 혁신을 통한 데이터 기반 의사결정 시스템을 만들고 자동화 혹은 증강된 의사결정 네트워크를 이해관계자들과 함께 구축해야 한다. 기존의 데이터 기반 의사결정 트리 외에 인공지능(AI), 머신러닝(ML) 및 다양한 실시간 데이터 분석 기법들을 사용해 최적의 의사결정 자동화 환경을 구축해야 한다.
가트너그룹은 이와 같은 다섯 가지 핵심 주제를 토대로 요약되는 10가지의 데이터 분야 핵심 트렌드를 함께 발표했다.(2023년 3월 28일 발표)
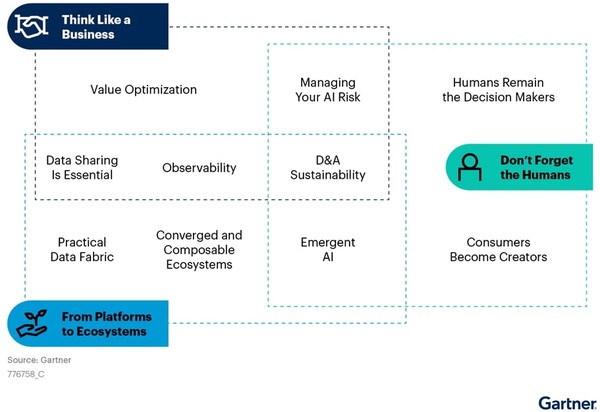
비즈니스 가치를 중심으로 문화와 데이터 기반 혁신을 위한 소프트 스킬에 집중하고 있는 반면 데이터 아키텍처와 관련한 키워드들은 모두 데이터 패브릭(Data Fabric)으로 통합되어 가고 있음을 볼 수 있다. 기존에 데이터 패브릭이 자동화나 가상화 같은 한두 가지의 기술요소의 접목으로 설명되었다면 지금은 검색성(Observability)이나 컴포넌트 가능성(Composability), 혹은 데이터 공유(Data Sharing) 등과 같이 보다 근본적인 아키텍처 속성으로 데이터 생태계(Data Ecosystem)를 보아야 한다는 것이다. 데이터 패브릭은 한두 가지의 기술이 아니라 차세대 데이터 아키텍처이다.
차세대 데이터 패브릭 아키텍처란, 기존의 데이터 저장소를 데이터 도메인별로 최적의 데이터 파이프라인을 구축하고 모든 영역에서 데이터를 수집(Collect) 혹은 연결(Connect)해서 다양한 데이터 기반 분석 과제를 대비할 수 있어야 한다. 또한 기존의 데이터 소비자에서 데이터를 만들고 다시 판매할 수 있는 생산자로 확대할 수 있는 환경도 갖추어야 한다. 아울러 외부의 데이터를 공유할 수 있는 자동화된 환경이 구현되어 있어야 하며, 이 모든 환경을 연결할 수 있는 공유 데이터 거버넌스 환경을 구현해 놓아야 한다. 특히 AI/ML의 장점을 잘 이용할 수 있는 머신러닝운영(MLOps) 환경도 구축되어야 한다.
고객들은 동일한 데이터를 시스템별, 업무별로 생성하는 것에 대해 비효율적이라고 생각하는 경향이 강하다. 비효율적인 데이터 생성을 최소화하는 상황에서 하나의 데이터 관점으로 데이터의 연결 문제를 해결하기 위해서는 기존의 운영계 아키텍처, 데이터웨어하우스 아키텍처, 데이터 레이크 아키텍처 등 다양한 시스템과 DBMS를 가상화라고 하는 기술을 통하여 모으고 조립할 수 있는 아키텍처로 구축되어야 한다.
고객이 시스템, DBMS의 관점에서 데이터를 구현할 경우 인프라 중심의 벤더사 아키텍처로 구현될 수밖에 없을 것이다. 과거와 달리 데이터 생성 속도가 몇십 배 이상 빠르게 증가하는 상황에서 구축 후 얼마의 시간이 지나지 않아 시스템 및 DBMS를 늘려야 하는 상황이 발생하게 된다.
따라서 데이터 패브릭은 위에서 언급한 고객사의 문제점을 해결할 수 있는 아키텍처다. 데이터 패브릭을 구현하기 위해서 가장 중요한 것은 데이터 거버넌스(Data Governance)를 기반으로 구축해야 한다는 점이다. 여러 곳에 펼쳐져 있는 데이터의 정보가 불일치 할 경우 아무리 좋은 개념 및 사상으로 데이터 패브릭을 구현하여도 양질의 원하는 데이터를 생성할 수는 없을 것이다.
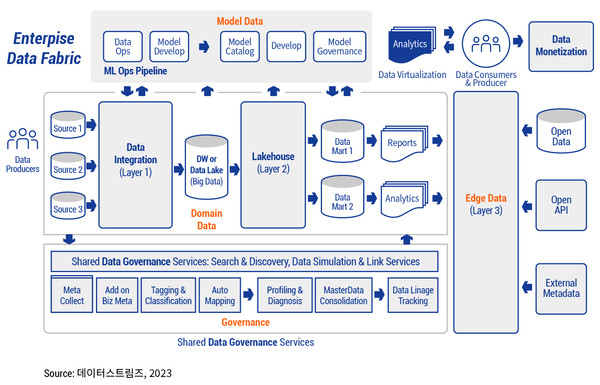
위의 아키텍처와 같이 데이터 패브릭은 데이터 거버넌스(Data Governance) 기반 위에 데이터 수집부터 시스템 간의 연결 등 여러 가지 기술을 복합적으로 사용해 구축해야 한다. 단순히 데이터 패브릭 중에 하나의 솔루션 또는 툴을 가진 업체가 접근할 수 있는 상황이 아니며 여러 업체가 모여서 구현할 경우 서로 간의 인터페이스 문제 및 데이터 처리에 다양한 문제가 발생할 뿐 아니라 만약 구축되었다 하더라도 운영 중에 문제가 발생될 경우 해결을 못하거나 해결에 상당한 시간이 필요할 수밖에 없을 것이다.
데이터 거버넌스 기반 위에 데이터 패브릭을 구축할 수 있는 데이터스트림즈는 국내에서 유일하게 데이터 패브릭 기반 데이터 통합 도구로 가트너의 벤더 목록에 등록된 업체이다.
22년 전 회사 창립 시점부터 ETL 기반의 데이터 통합 및 데이터 거버넌스(Data Governance)를 중심으로 사업영역을 확대했고 데이터 저장소 외에 가상화를 통한 실시간 데이터 연계, 인공지능(AI)/머신러닝(ML) 데이터 머신러닝운영(MLOps) 환경 등 모든 영역의 데이터 패브릭 기술을 갖추고 있다.