


강병억 AWS코리아 솔루션즈 아키텍트

[아이티데일리] 지난해 많은 사람들이 사용하는 메신저 서비스에 장애가 발생하면서 온라인, 모바일 기반의 서비스에 대한 재해 복구(DR) 환경 구성에 관심이 커졌다. 데이터센터의 장애가 곧 서비스 문제로 이어지면서 시스템에 대한 재해 복구의 중요성이 다시 한번 주목받게 된 것이다.
지난해 메신저 장애로 가장 분주하게 움직인 분야가 바로 금융산업이었다. 고객들의 주요한 자산 정보를 유실하거나 오류가 발생할 경우 해당 금융 기관은 치명적일 수밖에 없다. 금융 거래 특성상 금융 업무는 대부분 365일, 24시간 실시간으로 처리해야 된다. 금융업에서 재해 복구 시스템이 중요할 수밖에 없는 이유다.
재해복구 시스템이 중요하다는 것을 알고 있음에도 일부 금융기관은 비용문제 때문에 주요한 서비스에 대해서만 DR을 구성하고 비교적 덜 중요한 서비스 영역에 대해서는 DR을 구성하지 않는 경우도 있다. 하지만 요즘과 같이 모든 서비스가 복잡하게 얽혀 있는 상황에서 업무 연속성을 확보하기 위해서는 중요도와 무관하게 DR을 구성해야 하는 필요성이 대두되고 있다.
금융사들이 DR에 관심을 갖게 된 결정적인 계기는 2001년 9월 11일에 발생한 911사태였다. 실제 911테러 발생 당시에 세계무역센터 건물에는 수많은 금융사가 입주해 있었다. 대형 금융사들은 다행히 다른 위치에 백업센터들이 있어서 사고 이후에도 비즈니스를 재개하는 데 큰 어려움이 없었다. 하지만 절반에 가까운 중소형 금융사들은 해당 건물 안에 전산장비를 갖추고 있었기 때문에 복구 불가능한 수준의 피해를 입어 정상적으로 비즈니스를 재개하지 못했다.
911사태 직후에 미국 연방준비이사회는 금융사들에 DR와 업무 연속성 계획 수립을 권고하였고, DR 계획에 대해서 테스트를 주기적으로 실시하도록 요구했다.
금융사가 지켜야 할 DR 관련 규제
우리나라 금융 당국은 국내 금융사들에 대해 DR 구성을 강제하는 규정을 만들어 금융 서비스를 사용하는 국민들의 불편이 최소화될 수 있도록 신경쓰고 있다.
국내 금융사의 DR과 관련한 규정은 ‘전자금융감독규정’에 구체적으로 명시되어 있다. 이 규정에 따르면, 금융사들은 재해에 대비해 재해복구센터를 주전산센터와 일정 거리 이상 떨어진 안전한 장소에 구축·운용하여야 한다. 또한 금융사들의 핵심업무의 복구목표시간은 3시간 이내로 하되, 「보험업법」에 의한 보험회사의 핵심업무의 경우에는 24시간 이내에 복구할 수 있는 체계를 갖춰야 한다. 그리고 매년 1회 이상 재해복구센터로 실제 전환하는 재해복구전환훈련을 실시할 것을 요구하고 있다.
글로벌 결제 데이터 보안 인증인 PCI DSS (Payment Card Industry Data Security Standard), 미국 의료정보보호법인 HIPAA (Health Insurance Portability and Accountability Act), 국제표준 정보보호경영시스템인 ISO27001 등의 글로벌 규제 표준도 재해 시 복구할 수 있는 시스템을 갖추고, 비즈니스 연속성 계획을 수립할 것을 명시하고 있다.
DR은 어떻게 준비할 수 있나
1. DR 준비의 딜레마
DR 구성은 품질과 비례해 비용이 증가한다. 대문에 조직이 지켜야 하는 목표와 사용할 수 있는 예산 사이에서 적절한 수준을 설정해야 한다. 아래와 같은 요소들이 비용 증가를 수반하는 DR 구성 품질과 관련된 내용이다.
ㆍ복구 시간: 재난 발생 후 데이터를 더 빨리 사용할 수 있기를 원할수록 더 큰 비용이 발생한다.
ㆍ이격 거리: 복구해야 하는 데이터를 더 멀리 저장할수록 더 많은 비용이 발생한다. 주로 이 비용은 두 개 이상의 데이터 센터 사이의 고속 전용 네트워크와 관련돼 있다.
ㆍ복구하려는 데이터양: 재해 직후 데이터가 많으면 많을수록 더 많은 비용이 발생한다. 이 비용은 필요한 데이터 저장소의 중복성을 달성하기 위해 구입해야 하는 저장소와 관련이 있다.
ㆍ데이터 특성에 따른 세밀한 복구 계획: 여러 솔루션을 포함해 다양한 방식을 혼합한 보호 및 복구 계획은 단순한 계획보다 비용이 많이 든다. 예를 들어, 일부에 대한 미러링, 의 다른 부분에 대한 레플리케이션, 나머지 에 대한 테이프 백업 복구 등의 형태로 세분화된 복구 계획이 있을 경우가 비용이 더 발생한다. 단순한 복구 계획은 세밀하고 복잡한 계획보다 효율적이다.
2. DR 구성시 주요 의사결정 항목
적절한 품질 범위내에서 DR 효과를 최대화하기 위해서는 비즈니스 측면에서 의사결정을 내리기 위한 수치들이 필요하다. DR 프로젝트를 수행할 때 아래 언급되는 수치들을 어떻게 설정하느냐에 따라서 향후 DR 구성의 품질과 비용이 결정된다.
- 최대 허용 다운타임(Maximum Tolerable Downtime(MTD))
재해가 발생했을 경우 회사의 주요한 프로세스에 대해서 회사 비즈니스의 생존 자체를 위협하기 전에 복구해야 하는 시간 중에 가장 긴 시간을 최대 허용 다운타임(MTD)이라고 한다. 최대 허용 다운타임은 몇 시간이 될 수도 있고, 며칠이 될 수도 있다. RTO와 같은 연관된 목표 시간을 설정하는 데 이 수치를 활용할 수 있다.
- 목표 복구 시간(Recovery Time Objective(RTO))
재해가 발생했을 경우에 비즈니스 프로세스가 다시 시작될 수 있도록 복구를 수행해야 하는데, 복구 수행 시 복구를 완료해야 하는 목표 시간을 RTO로 지정한다. RTO를 결정할 때는 비즈니스 측면에서 정의한 최대 허용 다운타임인 MTD보다 더 짧게 결정해야 한다. RTO를 MTD보다 더 작게 설정해야만, 최대 허용 다운타임 시간 내에 복구가 완료되어서 비즈니스를 다시 시작하는 데 문제가 없게 된다.
- 목표 복구 지점(Recovery Point Objective(RPO))
재해가 발생하여 비즈니스가 중단되었을 때, 회사가 허용할 수 있는 최대 데이터 손실량을 나타낸다. 만약에, RPO를 2시간으로 지정한다면, 최대 손실되는 데이터양은 2시간의 거래 정보의 양으로 나타낼 수 있다.
3. DR 아키텍처의 종류
DR 구성을 필요로 하는 조직들은 DR 구성 계획에서 정의한 MTD, RTO, RPO에 따라서 수용할 수 있는 수준의 아키텍처를 정의해 구성해야 한다. 일반적으로 많은 회사들이 구성하는 DR 아키텍처는 아래와 같이 4가지 형태로 구분된다.
ㆍBackup & Restore: 이 방식은 DR site에서 최신 백업을 지속적으로 보존토록 구성하고 재해 발생 시에 준비된 백업 이미지로부터 복구하도록 해준다.
ㆍPilot Light: 중요한 데이터에 대해서는 실시간 복제를 구성하고, 서버와 소프트웨어들은 가동할 준비만 해 놓는 방식이다. DR 사이트에서 필요 서버를 가동하고 있지 않기 때문에 비용이 상대적으로 저렴하다.
ㆍWarm Standby: 복구되어야 하는 데이터는 실시간 복제를 하고, 재해 발생 시 빠른 시간 내에 서비스를 테이크오버 받을 수 있도록 서버들을 모두 기동해 놓는 방식이다. DR 사이트에서 서버를 사용하지 않은 채 기동해 놓아야 하기 때문에 비용이 발생하지만 재해 시 손쉽고 빠르게 대응이 가능하기 때문에 많이 사용하는 방식이다.
ㆍMulti-site active/active (Resiliency Architecture): 주센터와 DR센터에 기동되어 있는 서버들을 모두 활용해 서비스를 수행하는 가장 이상적인 방식이다. 특정 센터에 재해가 발생할 경우 바로 다른 센터에서 서비스를 수행하도록 해 서비스가 중단될 염려가 없다. 요소 기술별로 멀티 센터에 걸쳐서 클러스터링을 구성해야 하기 때문에 멀티 센터 클러스터링 관련 기술이 지원되지 않는다면 기술 난이도와 구현 난이도가 높은 방식이다.
4. 탄력성 아키텍처(Resiliency Architecture)
위에서 언급한 Multi-site active/active 방식은 재해나 장애가 발생하거나 시스템 운영자가 별도의 복구 작업을 수행하지 않더라도 자동으로 탄력적으로 복구할 수 있는 아키텍처라고 해서 ‘탄력성 아키텍처(Resiliency Architecture)’라고 일컫는다. 이 아키텍처를 간략하게 도식화한다면 아래와 같은 형태가 될 것이다.
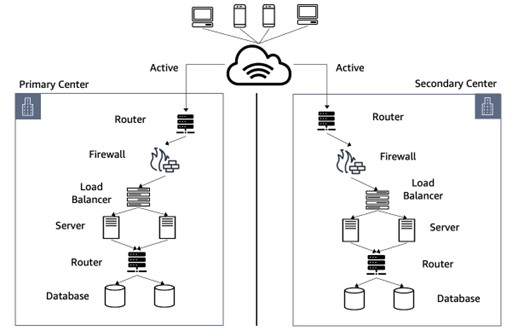
아마존웹서비스(Amazon Web Services, 이하 AWS) 클라우드의 경우에는 기본적으로 지리적으로 분리된 여러 지역에 구성된 멀티센터를 이용해 구성하도록 되어 있다. AWS 클라우드에서 제공되는 많은 관리형 서비스들은 이러한 탄력성 아키텍처(Resiliency Architecture)를 자체 지원하도록 구성되어 있다. <그림 2>는 AWS 클라우드 환경에서 지원되는 탄력성 아키텍처(Resiliency Architecture)를 도식화한 것이다.
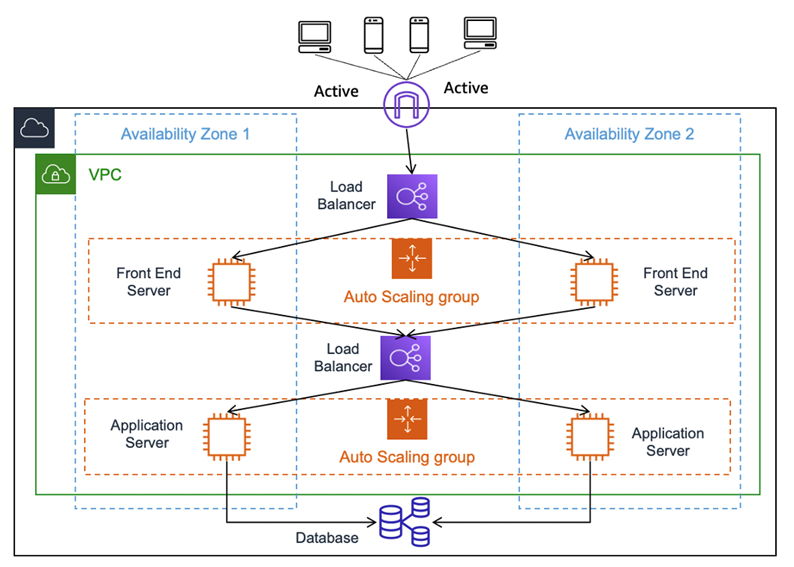
5. 클라우드를 이용한 빠른 DR 구성 방안
아직 DR 환경을 갖추지 못한 조직들이 많다. 이런 조직들은 탄력적으로 자원을 프로비저닝할 수 있는 클라우드를 이용한다면 DR 환경을 빠른 시간에 구성할 수 있을 것이다.
ㆍBackup & Restore 방식
온프레미스에 있는 데이터를 주기적으로 클라우드로 백업하고 재해 시 클라우드 환경에서 복구해 서비스를 제공할 수 있다.
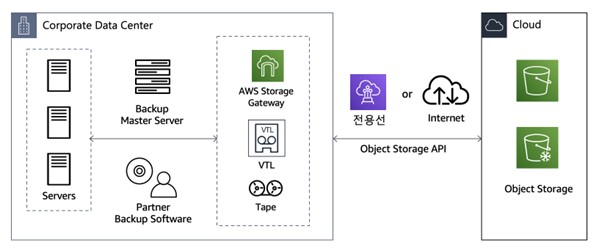
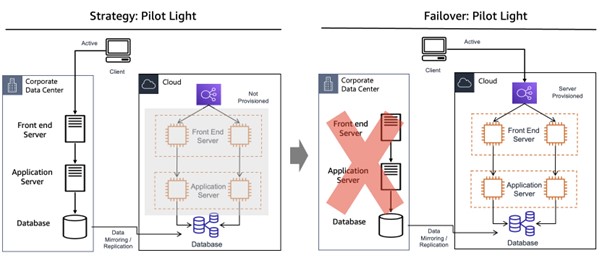
ㆍPilot Light 방식
아래와 같이 온프레미스에 있는 데이터 중에 주요 데이터는 클라우드로 실시간 복제를 수행하고, 재해 발생 시에만 연관된 서버들을 프로비저닝해서 서비스를 재개한다.
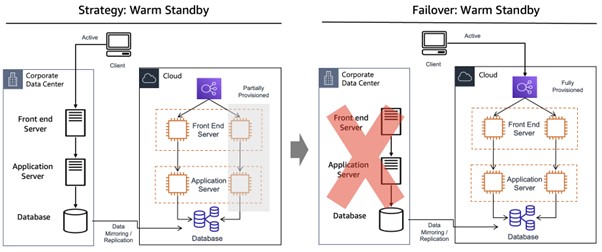
ㆍWarm Standby 방식
온프레미스에 있는 데이터 중에 주요 데이터는 실시간 복제를 클라우드로 수행하고, 어플리케이션 서버들은 제한된 용량만 프로비저닝하여 사용하다 재해 발생 시에 연관된 서버들을 스케일아웃 방식으로 프로비저닝해서 확보된 용량으로 서비스를 재개한다.
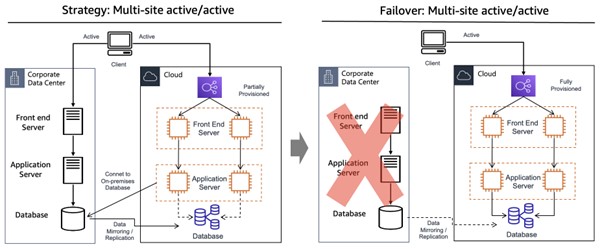
ㆍMulti-site active/active 방식
온프레미스 데이터센터와 클라우드 센터를 액티브-액티브 형태로 구성한다. 이 경우 온프레미스 자원과 클라우드 자원을 동시에 사용하면서 서비스를 지속할 수 있다. 한 센터에 장애가 일어나도 중단없는 서비스가 가능하다.
결론
지난 메신저 장애 사태를 계기로 금융권을 모든 산업 분야에서 중요한 서비스에 대한 DR 구성에 크게 공감하고 있다. 하지만, DR을 제대로 준비하려면 많은 설비와 자원이 필요해 쉽게 DR 프로젝트를 추진하지 못하는 경우도 있다. 이런 상황에서 탄력적으로 IT 자원을 프로비저닝할 수 있는 클라우드를 활용한다면 DR에 대한 고민을 해결할 수 있다. 많은 기업들이 고민하고 있는 DR 아키텍처를 비용 효과적으로 현대화할 수 있다는 것이다.