


기업 데이터 전략의 포스트 스탠다드
[아이티데일리] 데이터의 중요성이 높아지고 새로운 기술이 등장하는 속도가 점점 더 빨라지면서 데이터 관리에 어려움을 겪는 기업은 늘어만 가고 있다. 한때 데이터 레이크는 많고 복잡한 데이터 저장소들을 통합 관리해 대부분의 어려움을 해결해줄 수 있을 것으로 보였지만, 특유의 한계에 의해 기업에서 선택할 수 있는 새로운 선택지가 됐을 뿐 기존의 데이터 아키텍처들을 대체하는 새로운 표준(post standard)를 세우지는 못했다.
오늘날 전 세계의 많은 기업들은 자사의 비즈니스 변화에 맞춰 데이터 전략을 새롭게 수립하고 있다. 차세대 데이터 전략을 수립하려는 기업들이 가장 주목해야 할 것은 데이터 가상화(data virtuarization) 기술이다. 이는 데이터 웨어하우스로 대표되는 기존 데이터 저장소들의 한계와 데이터 레이크의 실패를 극복하기 위해 가장 효과적인 수단으로 보인다.
① 데이터 사일로 가속화하는 클라우드와 MSA
② 차세대 전략의 핵심은 데이터 소스의 논리적인 연결
레이크의 한계 극복하는 데이터 가상화
데이터 레이크가 가진 수많은 장점에도 불구하고, 데이터 레이크는 DB와 DW로 구성된 전통적인 데이터 아키텍처를 완전히 대체하지 못했다. 대다수 기업들은 전통적인 데이터 아키텍처와 데이터 레이크를 필요에 따라 구분해 사용하고 있다. 이는 즉 전통적인 데이터 아키텍처가 가진 많은 문제들은 여전히 해결되지 못한 상황이라는 것을 의미한다. 기업들은 여전히 전통적인 데이터 아키텍처에서 분산된 데이터 저장소들 사이를 연결하고 서로 다른 이종간 데이터를 손쉽게 결합할 수 있는 방법을 찾고 있다. 이러한 측면에서 최근에는 데이터 패브릭, 데이터 메시, 데이터 레이크하우스(data lakehouse) 등 다양한 기술과 개념들이 차세대 데이터 전략으로 주목받고 있다. 그리고 이러한 차세대 데이터 전략에서 가장 중요한 기술로 꼽히는 것이 데이터 가상화(data virtuarization)다.
데이터 레이크가 추구한 것은 데이터 저장소들 간의 물리적인(physical) 통합이다. 쉽게 말해 여러 저장소들에 산재돼 있던 모든 데이터들을 하나의 거대한 저장소에 물리적으로 복사해 저장하자는 개념이다. 반면 데이터 가상화는 데이터 저장소들간의 논리적인(logical) 통합을 추구한다. DB, DW, 데이터 레이크까지 기존의 모든 데이터 저장소들을 각각의 데이터 소스로 정의하고, 이러한 데이터 소스에 접근할 수 있는 가상화 레이어를 구성한다. 가상화 레이어는 그 자체로 데이터를 가지고 있지 않지만 각각의 데이터 소스들이 어떤 데이터를 가지고 있는지를 알고 있다. 따라서 사용자는 각각의 데이터 소스에 직접 접근하지 않고, 가상화 레이어에서 원하는 데이터를 찾아 쿼리를 날릴 수 있다. 가상화 레이어는 사용자의 요청에 따라 각각의 데이터 소스를 뒤져 필요한 데이터를 찾고 결합해 보여준다.
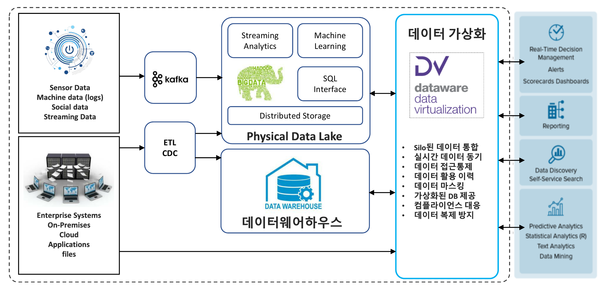
개념적으로 데이터 가상화는 데이터 레이크의 두 가지 실패를 완전히 해결한다. 먼저 ROI 측면에서, 구축 단계에서 물리적인 데이터 복제가 최소화되기 때문에 인프라 구축 비용을 크게 절약할 수 있다. 데이터 레이크는 스토리지를 구입하는 비용만 해도 최소한 기존에 보유하고 있던 수준의 2배 이상을 필요로 하지만, 데이터 가상화는 가상화 레이어를 통해 각 데이터 저장소 간의 논리적인 연결고리만을 만들어줄 뿐 물리적으로 복제해 저장하지 않기에 훨씬 비용 효율적이다. 또한 데이터 레이크는 원본이 되는 DB나 DW와 데이터 레이크 사이에 물리적으로 복제된 데이터들을 실시간으로 동기화하고 정합성을 유지해줘야 하지만, 데이터 가상화는 요청이 발생한 순간에 각각의 데이터 소스에서 데이터를 가지고 오기 때문에 실시간 동기화에 대한 부담도 적다.
보안 측면에서는 사용자의 접근 경로가 단일화된다는 것, 그리고 물리적인 데이터 복제가 없다는 것이 큰 장점으로 작용한다. 사용자는 각각의 저장소에 직접 접근하는 대신 가상화 레이어를 포털처럼 이용하게 된다. 접근 경로가 단일화되기 때문에 접속 이력이나 활동 내역 등을 보다 손쉽게 관리할 수 있다. 포털처럼 기능하는 가상화 레이어에서 사용자의 권한 관리 시스템을 잘 구축한다면, 접근 권한이 있는 데이터 소스에서만 데이터를 찾고 결합하도록 함으로써 동일한 쿼리에 대해서도 사용자에 따라 서로 다른 결과물을 보여주게 된다. 만약 각각 암호화가 적용된 데이터 소스들을 결합해야 할 경우, 가상화 레이어에서 복호화해 데이터를 결합한 후 결과물은 다시 암호화해서 반환하는 것도 가능하다. 기존에 운영하던 RDB 기반의 데이터 아키텍처들을 그대로 유지할 수 있으니 고도화된 보안 기술들을 그대로 활용할 수 있다는 장점도 있다.

MSA, 서비스 중심의 데이터 분리
엔코아 김범 전무
MSA가 등장한 가장 큰 이유는 시스템 간의 느슨한 결합(loosely coupled system)이라는 목적을 달성하기 위한 것이다. 서비스들을 작은 단위로 쪼개서 전체 서비스 중단 없이도 독자적인 업데이트나 점검이 가능하도록 하고, 한 곳에서 장애가 발생하더라도 전체가 영향을 받는 일을 방지하기 위해 나왔다. 완전히 새로운 용어라기보다는 앞서 나온 SOA(Service Oriented Architecture)와 비슷한 사상으로 탄생했다. ‘서비스 오리엔티드’라는 이름에서 알 수 있듯 이는 서비스 중심의 관점이다. 그렇다면 MSA를 데이터 중심적인 관점에서 들여다보면 어떻게 될까?
기존의 모놀리식 아키텍처에서는 다양한 서비스에서 사용되는 데이터들이 서로 중첩되도록 섞여있었다. 가령 서비스A에는 데이터1과 2가, 서비스B에는 데이터 2와 3이 사용되는 식이다. 그렇다면 모놀리식 아키텍처를 MSA에 맞춰 분리하기 위해서는 데이터를 어떻게 분리하고 저장할 것인지 고민해야 한다. 여기서 데이터 아키텍트는 모놀리식 시스템에 맞춰 쌓아온 데이터들을 개별 서비스에 맞춰 잘 분리하고, 중첩되는 데이터들이 지속적으로 동기화되고 정합성을 맞출 수 있도록 데이터 거버넌스를 제대로 만들어나가야 한다.
한편 모놀리식 아키텍처에서 MSA로 전환한다고 해도 개별 서비스들이 완전히 독립적으로 작동하지는 않는다. 하나의 비즈니스 트랜잭션에서는 여러 개의 서비스들이 동시에 돌아가야 하기 때문이다. 특정 비즈니스 트랜잭션을 구성하는 서비스 중 하나가 장애를 일으키면 해당 트랜잭션은 멈춰버리게 마련이다. MSA 관점에서는 각각의 서비스들이 서로 악영향을 주고받지 않고 잘 돌아가더라도, 전체 비즈니스 트랜잭션 관점에서는 모놀리식과 다르지 않다. 데이터 관점에서는 더 골치가 아프다. MSA에서는 중첩되도록 나누어놓은 데이터 위에서 하나의 비즈니스 트랜잭션을 구성하는 서비스들이 동시에 돌아가야 하니, 나누어놓은 데이터 간의 정합성이 항상 실시간으로 보장돼야 한다. 오히려 데이터 관점에서는 모든 서비스들이 하나의 저장소 안에서 돌아갔던 모놀리식 아키텍처가 편하다고 여겨질 정도다.
이때 사용되는 대표적인 기술이 데이터 가상화다. 각각의 서비스들이 개별적으로 돌아가는 가운데 서비스 간의 데이터 정합성을 맞추기 위해 데이터 레이크를 활용할 수는 없다. 비용도 비싸겠지만 무엇보다 실시간성을 보장할 수 없다는 점이 문제다. 하나의 비즈니스 트랜잭션 위에서 모든 서비스들이 동시에 돌아가야 하니까. 그러니 데이터 레이크 대신 데이터 가상화 기술을 통해 실시간으로 데이터 저장소 간의 정합성을 검증하는 것이 유리하다.
그동안 수많은 기업들이 MSA로 전환하면서 데이터와 관련된 어려움을 겪어왔고, 그 결과 데이터 가상화에 대한 필요성을 인식하게 됐다. MSA로의 전환을 추진하려는 기업은 서비스 중심의 아키텍처에서 어떻게 데이터를 분리하고 정합성을 실시간으로 유지할 것인지 충분한 고민과 논의를 거쳐야 할 것이다.
‘데이터 주도적인 혁신’을 위한 차세대 전략
오늘날 기업들은 데이터 레이크의 실패를 딛고 데이터 리터러시를 높일 수 있는 차세대 데이터 전략을 추구하고 있다. 이에 따라 데이터 패브릭이나 데이터 메시와 같은 새로운 용어들이 각광받고 있는 상황이다. 아직은 사람마다 각각의 용어에 다른 해석을 내놓고 필요한 기술 스택도 다르게 정의하고 있지만, 결국 중요한 것은 데이터 가상화를 통한 데이터 소스들의 논리적인 연결이다. 따라서 데이터 가상화는 기업들의 차세대 데이터 전략에 있어 새로운 기준(post standard)으로 자리잡을 것으로 보인다.
데이터 가상화를 통해 기업이 보유한 모든 데이터 소스들이 논리적으로 연결되고, 사용자가 데이터 카탈로그(data catalog) 등을 통해 편리하게 원하는 데이터를 찾고 결합해 데이터 리터러시를 확보할 수 있는 환경, 이것이 오늘날 기업들이 추구하는 차세대 데이터 전략의 핵심이다. 이러한 관점에서 데이터 패브릭 등은 과거의 DW나 데이터 레이크와 같이 특정 기술 스택이나 제품을 의미하는 것이 아니라, 기업이 데이터를 관리하고 활용하는 방법 자체가 다음 단계로 나아가는 것으로 해석할 수 있다.
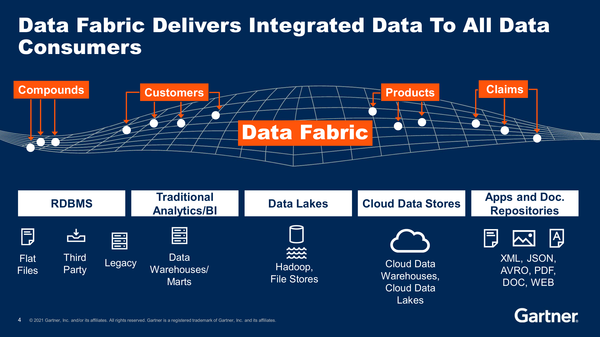
특히 이러한 변화는 기존에 우리가 쌓아왔던 수많은 데이터 관련 기술들이 고도화된 끝에서 만들어졌다는 점이 인상깊다. 앞서 데이터 레이크는 물리적인 데이터 공간을 통합한다는 거대하고 파괴적인 변화를 만들면서 기존의 기술들과 배치되는 부분들이 많았지만, 데이터 가상화로 대표되는 차세대 데이터 전략들은 기존의 기술과 인프라를 최대한 활용하면서 데이터 리터러시를 극대화한다. 이에 대해 데이터스트림즈 나희동 전무는 “오늘날 기업들이 추구하는 것은 데이터 주도적인 혁신(Data Driven Innovation)이다. 이것은 데이터 메시, 데이터 패브릭 등으로 표현되는 현대적인 데이터 아키텍처로 실현될 것이고, 그동안 데이터를 수집하고 저장하며 분석하기 위해 만들어졌던 모든 기술들이 궁극적으로 현대적인 데이터 아키텍처를 만들기 위해 활용될 것”이라고 강조했다.