


공공‧연구기관 등에 API 형태로 개방…AI 생태계 발전 위한 민관 협력 모델 제시

[아이티데일리] 과학기술정보통신부(장관 이종호, 이하 과기부)는 초거대 AI 모델을 활용한 혁신 서비스 개발을 위해 ‘초거대 AI 모델 활용 시범사업’을 추진한다고 20일 밝혔다.
초거대 AI는 대용량 데이터와 슈퍼컴퓨팅 인프라를 활용해 AI의 규모를 수천억~수조 개 매개변수 규모로 확장한 AI 기술이다. 지난 2020년 5월 미국 오픈AI(Open AI)가 최초의 초거대 AI 모델 ‘GPT-3(Generative Pre-trained Transformer 3)’를 공개하면서 해당 분야의 경쟁이 본격화됐고, 국내 주요기업들도 초거대 AI 모델 구축에 대규모 투자와 기술 개발을 추진하고 있다.
정부의 초거대 AI 지원 계획은 민‧관이 함께한 ‘AI 최고위 전략대화’에서 국내 기업의 초거대 AI 기술 주도권 및 경쟁력을 확보를 위한 생태계 활성화 방안으로 제시됐다. 이번 초거대 AI 활용 시범사업을 통해 정부는 대학, 중소기업 등에서 연구, 서비스 개발에 초거대 AI 모델을 활용할 수 있도록 지원할 예정이다.
과기부는 지난 5월부터 초거대 AI 모델을 활용하기 위한 시범 서비스 공급자‧사용자를 수시로 모집하고 있다. 현재 서비스 공급자로는 네이버클라우드가 선정됐다. 네이버클라우드는 초거대 AI ‘하이퍼클로바’를 활용해 사용자가 대화, 질의응답, 요약, 텍스트 생성, 변환 등의 AI 기능을 API 형태로 이용할 수 있도록 제공한다.
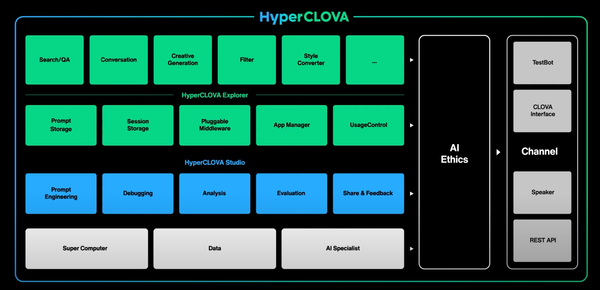
‘하이퍼클로바’는 네이버가 자체 개발한 초거대 AI 모델이다. 지난해 5월 공개된 당시 이미 오픈AI의 ‘GPT-3’를 뛰어넘는 2,040억 개 파라미터 규모로 개발돼 업계의 관심을 모았다. 특히 영어가 학습 데이터의 대부분을 차지하는 ‘GPT-3’와 달리, 5,600억 개에 달하는 한국어 대용량 데이터를 바탕으로 학습 데이터의 한국어 비중을 97%까지 높였다. 영어 중심의 글로벌 AI 모델과 달리 한국어에 최적화한 언어모델을 개발해 AI 주권을 확보하겠다는 취지다.
이번 시범사업의 사용자는 초거대 AI를 자체 연구나 서비스 개발에 활용하고자 하는 국내 공공‧연구기관, 대학교(원)가 대상이다. 올해 8월까지 시범 운영한 결과를 토대로 향후 중소기업 등 민간기업까지 지원 대상 확대를 검토할 계획이다.
과기부 류제명 인공지능기반정책관은 “이번 시범사업은 우리나라 AI 발전을 위해 정부와 민간이 함께 협력해 대기업에서 개발한 초거대 AI를 대학, 중소기업 등이 연구에 활용할 수 있도록 개방하는 것에 의의가 있다”며, “초거대 AI를 경험한 국내 기업, 연구자들이 국내 초거대 AI 생태계 활성화에 기여하기를 기대한다”고 말했다.