



송규호 아마존웹서비스 솔루션즈 아키텍트
[아이티데일리] 송규호 솔루션즈 아키텍트는 KT, 오라클, 아마존 등에서 약 16년여 동안 오픈소스를 기반으로 한 클라우드 및 빅데이터 기술에 대한 경험을 쌓았고, 이를 토대로 다양한 엔터프라이즈 고객들을 대상으로 새로운 기술을 고객의 비즈니스 환경에 최적화시키는 컨설팅 업무 수행하고 있다. 현재는 아마존웹서비스(AWS)의 다양한 클라우드 서비스들을 활용해 기술을 이용한 비즈니스 혁신에 기여하고 있다. <편집자 주>

2020년대를 관통하는 IT 업계의 핵심 키워드는 디지털 전환(Digital Transformation)이다. 디지털 전환은 이제 더 이상 피할 수 없는 현실이 됐다. 컴퓨터와 인터넷으로 시작된 디지털라이제이션(Digitalization)은 아이폰을 필두로 모바일 환경을 양분 삼아 성장했고 코로나 팬데믹이 촉발한 위기 속에서 폭발적으로 팽창하고 있다. 그 배경에는 모바일과 결합된 생활 편의 시설들의 디지털화, 클라우드 컴퓨팅을 활용한 신기술 접근성 강화, 블록체인과 NFT 기술을 활용한 금융 디지털화 등이 있다.
2007년 시장에 출시된 아이폰은 전세계를 스마트폰화 시켰고, 인터넷에 ‘접속’해 있는 시간도 점점 확대되었다. 지금 우리는 은행에 가지 않고 모바일 뱅킹으로 모든 금융 관리를 하고 냉장고에 붙어 있는 중국집에 전화를 거는 대신 앱에서 유명한 레스토랑의 메뉴를 배달시켜 먹는다. 심지어 화장실의 악취를 제거하는 일, 파워포인트를 만들어 주는 일, 음식물 쓰레기를 버려주는 일, 미용실을 예약하는 일들을 모바일을 통해서 한다.
또한 기업들은 클라우드 서비스 제공사(CSP, Cloud Service Provider)들이 제공하는 최신 기술들이 적용된 인프라를 사용하며 전문가들이 개발 공급하는 AI 알고리즘을 사용하고, 인공지능이 직접 응대하는 스마트 콜센터를 손쉽게 도입한다. 그런가 하면 블록체인과 NFT 기술을 활용해서 부동산, 주식 등을 토큰화시켜 원하는 만큼만 구매하고 국경을 초월하여 심지어 가상세계와 현실세계를 이어주는 화폐를 사용할 수 있다.
블록체인 결제 시스템이 보편화되면 지금의 복잡한 결제 모듈은 매우 간소화 될 것이고 자본은 무제한으로 국경을 초월하여 이동할 것이다. 인터넷이 정보들을 연결시켰다면 블록체인은 금융들을 연결시키고 세상의 모든 자산들을 디지털화시킬 것이므로 또 한 번의 대규모 디지털 전환의 트리거가 될 것이다.
블록체인은 디지털 전환의 트리거
기업들은 이러한 현실들을 이미 잘 알고 있고 너나 할 것 없이 앞다퉈 디지털 전환에 열을 올리고 있다. 그 결과 IT 인력들은 씨가 말라 버렸고 5년차 개발자는 상상 속의 동물이라는 웃픈 이야기가 들리고 있다.
디지털 전환에서의 핵심은 수평적인 기업문화로부터 출발하는 혁신적인 아이디어, 이 아이디어를 민첩하고 빠르게 비즈니스에 적용할 수 있는 스마트한 소규모 조직들, 데이터에 기반한 정확한 의사 결정, 고객 경험을 극대화 시킬 수 있는 혁신적인 기술 도입 등을 들 수 있다. 이 모든 것들을 다루려면 너무 방대한 이야기를 해야 하므로 여기서는 기술적인 측면에서만 살펴본다.
우선 디지털 전환을 위해 기술적인 측면에서 기업들이 고려해야 할 것은 고객의 디지털 경험을 극대화할 수 있는 애플리케이션 현대화(Application modernization)이다. 코로나 팬데믹 시대를 살고 있는 사람들은 모바일 환경에서의 디지털 경험에 민감하다. 디지털 세상의 큰 특징 중의 하나는 네트워크 효과를 일으키는 사용자의 규모가 그 어느 것보다 중요하다는 것이고 불편한 UX(User Experience)를 제공하는 서비스에 남아 있는 사용자들은 거의 없다는 것이다.
편리한 UX를 제공하기 위해서는 불편한 기능 혹은 모듈을 빠르고 지속적으로 개선하는 작업을 해야 한다. 그러기 위해서는 각각의 모듈을 분리하여 개발 및 배포할 수 있는 MSA(Micro Service Architecture)기반으로 애플리케이션(Application)을 설계해야 하며 사용자가 증가하면 서비스의 용량(Capacity) 또한 증가시켜서 버틀넥(bottleneck)이나 중단 없이 서비스를 제공해야 한다. 여기에 필요한 기술들을 바닥부터 모두 개발하여 적용하려면 천문학적인 비용이 들고 실패할 가능성도 매우 높다.
클라우드 서비스를 이용하면 CSP들이 개발해 놓은 기술들을 간편하게 적용할 수 있으며 실패에 대한 리스크도 줄일 수 있다. 아마존웹서비스(AWS)에서도 기업들이 애플리케이션 현대화를 적용할 때 활용할 수 있는 여러 가지 서비스를 제공하고 있다.
클라우드 서비스, 실패 리스크↓
첫째, 앱 현대화를 위해서는 인프라를 보다 유연하고 가볍게 사용할 수 있어야 한다. 이를 위해 컨테이너의 마스터 노드를 관리형으로 제공하는 Amazon ECS나 Amazon EKS 그리고 워커 노드를 관리형으로 제공하는 AWS Fargate 등을 활용할 수 있고 인프라를 아예 서버리스(Serverless) 형태로 사용하려면 AWS Lambda나 AWS Amplify 등을 쓰면 된다. AWS에서는 서버리스 기술들을 도입에 참고할 수 있는 다양한 서버리스 패턴들을 모아서 Serverless Patterns Collection Repository를 통해서 제공하고 있다.
둘째, 개별 서비스의 워크로드(Workload)에 맞는 데이터베이스를 선택하여 도입해야 하는데 AWS에서는 RDBMS뿐만 아니라 Key-value, wide-column, document형태의 NoSQL 데이터베이스(Amazon DynamoDB, Amazon Keyspaces for Apache Cassandra, Amazon DocumentDB), In-memory 데이터 베이스인 Amazon ElasticCache, Graph 데이터를 처리하기 위한 Amazon Neptune, 시계열 데이터용인 Amazon Timestream, Ledger 데이터를 처리하기 위한 Amazon QLDB등 다양한 형태의 데이터베이스를 관리형으로 제공하고 있다.
셋째, 개별 서비스들을 독립적으로 구성하고 각 서비스들 간의 통신은 API 혹은 메시징 서비스를 활용해야 한다. AWS에서는 API를 손쉽게 관리할 수 있는 Amazon API Gateway, pub-sub 기반의 분산 메시징 서비스인 Amazon Kinesis와 Amazon MSK 등을 제공하고 있다.
넷째, 인프라를 코드로 관리하고 배포하는 체계를 만들어서 애플리케이션의 배포 및 관리와 인프라를 묶어서 배포 시의 오류를 최소화하고 프로세스를 자동화해야 한다. AWS에서는 IaC(Infrastructre as a Code)를 위한 다양한 툴들을 제공하고 있으며 지속적으로 개선하고 발전시키고 있다. IaC툴로 AWS에서 가장 보편적인 서비스는 CloudFormation이다. CloudFormation은 YAML 형식을 따르기 때문에 인프라의 규모가 커지면 코드의 라인(line)수가 매우 길어지고 코드가 복잡해진다. CDK는 파이썬 등의 프로그래밍 언어를 이용하여 AWS의 서비스를 코드로 만들 수 있으며 훨씬 간편하게 AWS의 서비스에 IaC를 적용할 수 있다.
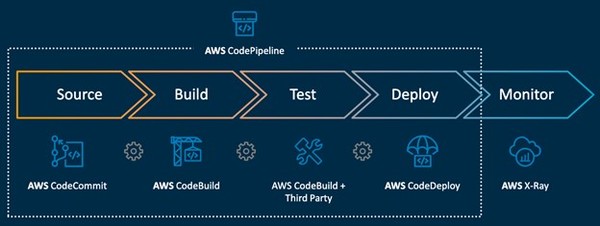
마지막으로 애자일(Agile)한 개발 환경을 구축하여 애플리케이션 개발 및 배포 시간을 단축하고 분산되어 있는 애플리케이션 들의 문제점을 손쉽게 파악할 수 있어야 한다. CI/CD 파이프라인을 구축하려면 AWS CodePipeline 서비스들을 사용하면 되고 AWS X-Ray를 활용하여 분산되어 있는 애플리케이션들의 퍼포먼스 보틀넥을 확인하거나 트러블 슈팅을 할 수 있다.
또한 자바스크립트(Javascript)의 헤더에 코드 몇 줄만 추가하면 Amazon CloudWatch Rum(Real User Monitoring) 기능을 활용하여 application page의 로딩에 관련된 지표들, 사용자들이 사용하는 브라우저의 정보, 사용자들이 웹 페이지에서 어떤 경로로 이동하는지에 대한 내용들을 간편하게 모니터링 할 수 있다.
디지털 전환에 성공한 기업들의 사례에서 빼놓지 않고 등장하는 것은 데이터의 활용이다. 십여 년 전에 IT업계에서 빅데이터 열풍이 불 때만 해도 반신반의 하는 기업들은 존재했지만 지금에 와서 데이터의 활용이 중요하지 않다고 이야기하는 사람은 거의 없다. 다만, 여전히 데이터의 활용 및 분석을 어떻게 잘 할 수 있을지 고민하는 목소리는 많이 듣고 있다.
아마존은 1990년대에 인터넷으로 책을 판매하던 때부터 사용자의 구매 패턴을 분석하여 책 추천 서비스를 했을 만큼 회사를 설립했을 때부터 지금까지 데이터를 분석하고 활용하는 것에 대해 진심이었다. 클라우드 사업을 시작하면서 고객들에게 지속적으로 아마존이 사용하는 데이터 활용 및 분석에 대한 노하우를 공유해 달라는 요구를 계속해서 받아왔었고 고객의 성공이 곧 아마존의 성공이라는 핵심 철학에 따라 AWS 클라우드를 사용하는 고객들이 데이터를 편리하게 활용할 수 있는 여러가지 서비스들을 제공하고 있다.
AWS, API 기반 AI 서비스 제공
데이터에 맞는 정교한 머신러닝 모델을 만들어서 적용하는 일은 쉽지 않다. 고액 연봉을 받는 우수한 인재를 채용해서 팀을 꾸려야 하고 여러 시행착오를 거쳐서 이를 비즈니스에 적용시키면서 지속적으로 이를 개선해야한다.
AWS에서는 머신러닝에 전문적인 노하우가 없는 회사들도 간편하게 사용할 수 있도록 API기반의 AI서비스들을 제공하고 있다. Amazon Forecast를 사용하면 Amazon.com에서 사용하고 있는 기술에 기반한 정확한 시계열 예측 알고리즘을 도입할 수 있고 Amazon Personalize를 사용하면 역시 Amazon.com에서 사용하고 있는 기술에 기반한 실시간 개인화 및 추천 서비스를 간편하게 도입할 수 있다.
이외에도 NLP 엔진을 기반으로 자연어 처리를 할 수 있는 Amazon Comprehend, 이미지 데이터를 처리할 수 있는 Amazon Rekognition, 온라인 사기 탐지에 사용할 수 있는 Amazon Fraud Detector, 제조 공정에서의 기계들의 지표 이상탐지 및 품질검사 등에 활용할 수 있는 Amazon Lookout, 프로그램 코드를 리뷰하고 프로파일링해서 중요한 문제 및 찾기 어려운 버그를 찾아주고 애플리케이션의 성능을 개선해주는 Amazon CodeGuru등 다양한 AI 서비스들을 제공하고 있다.
내부에 머신러닝 전문가 집단을 보유하고 있는 회사들에서는 Amazon SageMaker에서 제공하는 기능들을 사용하여 머신러닝을 준비하는 단계부터 모델을 생성하는 과정 그리고 모델 튜닝 및 배포 후의 관리까지 간편하게 수행할 수 있다. 준비 과정에서는 데이터를 EDA하고 전처리 하는 작업들을 간편하게 도와주는 SageMaker Data Wrangler, SageMaker Clarity등을 사용할 수 있으며 모델을 빌드할 때는 주피터 노트북 기반의 IDE 환경을 제공하는 SageMaker Studio Notebooks를 활용할 수 있으며 AWS의 머신러닝 전문가들이 예제로 만들어서 제공하는 수백 가지의 주피터 노트북을 무료로 다운받아 사용할 수가 있다.
데이터만 입력하고 자동으로 최적의 알고리즘을 찾아서 머신러닝 모델을 생성하고 싶다면 SageMaker Autopilot을 사용하면 된다. 이외에도 생성한 모델을 편리하게 튜닝하고 모니터링할 수 있는 다양한 도구들도 제공하고 있다. 작년 말에 새롭게 출시한 Amazon SageMaker Canvas는 코드 작성이나 머신러닝에 익숙하지 않은 비즈니스 담당자들도 손쉽게 머신러닝 모델을 생성할 수 있도록 GUI 환경에서 워크플로우(Workflow)를 그리는 것만으로 모델을 생성하고 사용할 수 있게 해준다.
기업 내부에서 데이터를 보다 유의미하게 활용하려면 각각의 조직들이 가지고 있는 데이터를 통합하고 여기에 더해 기업 외부에서 발생하는 데이터들도 수집하여 데이터 활용이 필요한 개별 조직들이 원하는 데이터에 손쉽게 접근하고 활용하게 해야한다.
Amazon S3는 데이터를 비용 효율적이고 안전하게 저장할 수 있으며 다양한 AWS 서비스를 활용하여 S3에 저장된 데이터를 처리할 수 있다. 또한 Intelligence Tiering 기능을 활용하여 ILM 정책을 자동으로 적용하고 저장 비용에 최적화된 스토리지(Storage) 계층으로 데이터를 이동시켜서 데이터 저장에 대한 비용 부담을 줄일 수 있다. S3를 중심으로 한 데이터 레이크 구축은 디지털 전환을 염두에 두고 있는 기업들이 가장 먼저 시작해야하는 과제라고 생각한다.
느림의 미학, 디지털 세상에서는 통하지 않는다
데이터 레이크를 구축하고 나면 정당한 권한이 있는 사람들만 필요한 데이터에 접근 할 수 있게 해주는 체계를 만들어서 데이터의 거버넌스를 수립해야한다. AWS LakeFormation을 이용하여 데이터에 엑세스 하는 사용자 별로 세분화된 권한을 테이블, 열, 행 수준에서 제어할 수 있다. LakeFormation에서 정의한 접근 제어 정책은 S3를 데이터 소스로 사용하는 다양한 AWS의 Analytic 서비스들(Redshift, Athena, Glue, QuickSight 등)로 상속되므로 LakeFormation을 사용한 중앙화된 통제를 할 수 있다. LakeFormation에서는 데이터 접근 제어 기능 외에도 여러 가지 기능들을 제공하고 있다. 작년말에 새롭게 출시한 Governed table기능을 활용하면 이전 버전의 테이블에 쿼리를 할 수 있는 Time-Travel 쿼리 기능을 Athena등을 통해서 수행할 수 있으며 S3에 저장된 데이터를 대상으로 행 단위의 Write, Delete, Update 작업을 수행할 수도 있다.
AWS 마켓 플레이스에서는 AWS 클라우드 위에서 실행되는 여러 파트너사들의 솔루션을 판매하고 있는데 PaaS, SaaS 솔루션들 이외에도 기업들이 내부에 보관하고 있던 데이터도 Data Exchange를 통해 판매하고 있으며 기업들이 내부에서 개발한 머신러닝 알고리즘과 모델들도 판매하고 있다. AWS 클라우드를 사용하는 고객들이라면 누구나 필요한 데이터를 사고 팔고 할 수 있고 머신러닝 알고리즘과 모델도 거래할 수 있다.
디지털 세계에서는 빠르고 민첩한 조직을 만들어서 혁신적인 실험들을 지속하고 이를 토대로 고객이 원하는 제품과 서비스를 제공해야 살아남을 수 있다. 디지털 전환을 고민하는 기업들이 클라우드 서비스를 사용했을 때의 이점은 명확하다. 빠르게 시작할 수 있고 신기술 도입이 간편하며 언제든지 엔터프라이즈급으로 확장할 수 있다. 느림의 미학은 적어도 디지털 세상에서는 틀린 말이다.
● AWS Fargate: ECS나 EKS와 같은 컨테이너 클러스터를 만들 때 Worker node들도 생성해야 하는데 Worker node들을 AWS에서 관리형으로 제공해주는 서비스. 관리형이라는 말은 AWS에서 인프라를 관리해주는 서버리스형 서비스라는 의미.
● AWS Lambda: AWS의 대표적인 서버리스 서비스이며 인스턴스나 컨테이너를 띄울 필요도 없이 코드만 작성해서 구동하는 서비스
● AWS Amplify: 웹 이나 모바일 앱 백엔드를 간편하게 구성할 수 있게 해주는 PaaS 서비스
● key-value, wide-column, document: NoSQL 데이터베이스 중에서 데이터를 저장하는 방식에 따른 차이가 있는 데이터베이스.
● Key-value: 데이터를 key와 value라는 튜플 형태로 저장
● Wide-column: 행마다 저마다의 컬럼을 가지고 있는 데이터베이스 즉 행별로 다른 스키마를 가질 수 있는 형태로 데이터를 저장
● Document: 데이터를 Json형태로 저장
● Amazon Timestream: 시계열 데이터 형태로 데이터를 저장하는 데이터베이스
● Ledger: 블록체인에서 주로 사용하는 형태의 데이터. 거래의 원장형태로 데이터를 저장함
● Pub-sub: 메시지를 전달하는 하나의 형태. 복수개의 publisher(주로 application)가 큐에 메시지를 집어넣고 복수개의 subscriber(application혹은 분석에 사용되는 도구)들이 원하는 메시지를 구독 받아서 처리하는 형태
● Amazon Kinesis: 아마존에서 관리형(서버리스) 형태로 제공하는 분산 큐
● Amazon MSK(Managed Streaming for Apache Kafka): Kafka라고 하는 오픈소스 분산 큐를 AWS에서 관리형으로 제공하는 서비스
● YAML: json이나 xml 형태 같은 데이터 구조체의 종류
● 모델 빌드: 데이터를 특정한 머신러닝 알고리즘 등을 사용하여 트레이닝시키는 개념. 프로그램 빌드처럼 일반적인 용어.
● Intelligence Tiering: 오래되거나 잘 사용하지 않는 데이터는 자동으로 저장 대비 비용이 더 저렴한 곳으로 이동시켜서 스토리지 비용을 최적화 시키는 기술
● Governed table: LakeFormation 기능 이름. 즉 고유명사
● Time-Travel 쿼리기능: LakeFormation에서는 테이블을 버전별로 관리할 수 있다. 어떤 테이블에 있는 데이터가 변경되면 이전 데이터를 담고 있는 테이블을 v1으로 남겨두고 새로운 데이터가 담긴 테이블을 V2로 저장하고 디폴트 버전을 V2로 설정한다. 만약에 변경되기 전의 데이터에 접근하려면 v1테이블에 쿼리를 할 수 있게 해주는 기능이다. 과거 데이터에 쿼리를 할 수 있게 해주는 기능이므로 Time-travel이라고 한다.
● Data Exchange: AWS 마켓플레이스 중의 하나이며 고객들이 가지고 있는 데이터를 이곳에 올려서 거래하게 해주는 플랫폼. 예를 들어 쿠팡에서 2021년 구매 이력에 대한 데이터를 판매하고 싶다면 민감정보 등을 처리한 뒤에 이곳에 올려서 판매할 수가 있다. 쿠팡의 이 데이터가 필요한 고객은 이를 구매해서 사용할 수가 있다.