



버즈니 AI Lab 권순목, 김선범 리서치 엔지니어

[아이티데일리] 모바일 홈쇼핑 포털 앱 홈쇼핑모아에서는 여러 홈쇼핑사에서 판매하는 여러 상품들을 한번에 모아서 검색할 수 있는 기능을 제공하고 있다. 많은 상품이 존재하는 만큼, 사용자가 어떠한 상품을 선택할지 미리 예측하고 그 상품을 유저에게 노출시키는 것은 E-커머스 산업에서 꽤 주요한 역할을 하고 있다. 따라서 버즈니 추천팀은 홈쇼핑모아 유저들의 상품 선호도를 실시간으로 파악해 유저가 원하는 상품을 제공해 주는 것에 중점을 두고 여러 연구와 개발을 진행하고 있다.
이 글에서는 이러한 기술을 개발하기 위해 버즈니에서는 어떤 연구와 개발을 진행하고 있는지 정리했다.
정리한 순서는 아래와 같다.
1. 추천 알고리즘에 대한 기본 알고리즘
2. Session based 추천 모델
3. 홈쇼핑모아에서 Session based 추천 모델을 서비스하기 위해 고려해야 할 것들
1. 추천 알고리즘에 대한 기본 알고리즘
추천에 대해서 이야기하기 전에, 먼저 추천 알고리즘들이 어떠한 방식으로 발전돼 왔는지 알아보고자 한다. 흔히 추천 알고리즘을 적용한다고 하면 쉽게 떠올릴 수 있는 알고리즘은 Collaborative filtering(CF) 알고리즘과, Content based(CB) 추천 방식이다.
CF 알고리즘은 꽤 많은 서비스에서 이미 도입되고 있는 유명한 추천 방식이다. CF는 여러 유저들의 취향을 기반으로 특정 유저의 취향을 예측한다. 쉽게 설명하자면, <그림 1>의 유저 a와 c는 선호하는 상품이 많이 겹치고 있다. 이를 통해 유저 a에게는 자신이 보지 못한 상품 2를 추천할 수 있다. 이것은 나와 비슷한 사람이 좋아하는 아이템이 있다면, 그 아이템에 대한 나의 호감도도 높을 것이라는 가정에서 출발하는 알고리즘이다.
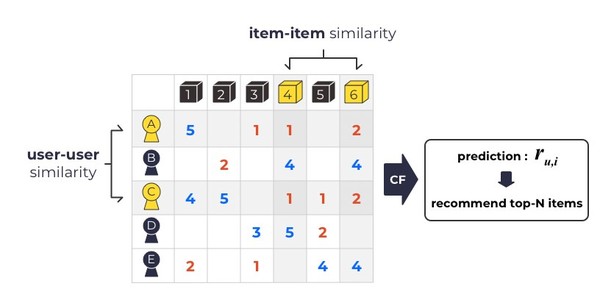
숫자는 유저가 각각의 아이템에 매긴 선호도(rating)를 의미하며, 빈칸은 유저가 해당 아이템에 대해 정보를 주지 않았다는 의미다. 우리는 이 표에서 빈칸으로 존재하는 곳의 값들을 채워야 한다. 이 값을 채운다는 것은 유저가 선택해보지 않은 아이템에 대해 어떤 선호도를 갖는지 예측한다는 것이다.
CB 알고리즘 방식은 각각의 아이템에 대한 정보들을 이용해 비슷한 아이템들을 추천하는 방식이다. CF 알고리즘과 다르게 아이템 속성 정보들을 활용해 아이템을 표현하고, 이를 기준으로 서로의 유사도를 파악한다. 속성 정보로는 상품의 가격, 상품명, 상품 이미지 등이 활용될 수 있다.
2. Session based 추천 모델
여러 서비스 기업들은 위와 같은 전통적인 알고리즘을 사용해 추천 서비스를 제공하고 있으며, 그중에서도 개인화 추천을 위해 Matrix Factorization(MF) 기반의 CF 방식을 많이 사용한다.
이 방식은 유저가 본 상품들의 순서를 고려하지 않으므로 Global 취향을 잘 고려할 수 있다. 반면 Local 취향 즉, 현재 가장 관심을 갖는 상품이 무엇인지는 알 수 없다. 또한 순서를 고려하지 않기 때문에 유저들의 구매 패턴을 알아낼 수 없는 문제가 있다.
예를 들어보자. 홈쇼핑모아에서 마스크를 구매한 대부분의 유저들은 직후에 바로 손 세정제를 구매하는 패턴을 보인다고 가정해 보자. 이런 패턴이 유저들에게 자주 발생하고 있다면, 우리는 최근에 마스크를 구매한 유저에게 손 세정제를 추천할 수 있다.
하지만 MF 방식으로 추천을 하게 된다면 이러한 추천은 할 수 없다. 그 이유는 <그림1>과 같이 유저가 본 상품들은 Matrix로 표현이 되는데, 유저가 상품들을 어떤 순서로 구매했는지 순서 정보를 알 수 없기 때문이다. “특정 유저가 손 세정제와 마스크를 구매했다”라는 정보만 표시되고 추천 모델도 그 정보만 가지고 학습을 하기 때문에 아이템 선택 순서에서 오는 정보를 모델링하기 힘들다. 즉 우리는 추천 모델에서 이러한 정보 자체를 전달하기 힘든 상황이다.
최근 여러 추천 연구 학회에서는 Session based 추천 모델을 주제로 한 연구들이 많이 나오고 있다. 이는 위에서 제시한 MF 기반의 추천 모델의 단점들을 해결한다. Session based 추천 모델이란 유저들이 선택했던 아이템 순서를 고려해 학습한 추천 모델을 의미한다.
AI 분야에서 자연어 처리 모델이 급속도로 발전됨에 따라 일련의 순서를 가진 데이터들을 잘 처리하는 모델이 개발됐고, 추천 도메인 연구 집단에서는 이러한 지식들을 추천 도메인에 맞게 활용하고 있다. 자연어 처리 모델에서 각각의 단어들을 토크나이징 하고 토큰들을 단어로 취급해 학습을 했다면, 추천 도메인에서는 각각의 상품들을 하나의 단어로 취급해서 학습한다. 따라서 모델에 적용될 학습데이터는 각각 유저들이 일정한 기간 동안 선택했던 아이템들을 순서대로 제공돼야 하며, 모델은 이러한 순서로 들어오는 데이터들을 받고 학습하게 된다.
홈쇼핑모아에서는 이러한 Session based 추천 모델 개발을 진행하고 있으며, 서비스에 배포할 준비를 하고 있다. Session based에 관련된 모델링 및 서비스 적용에 대한 히스토리를 보여주는 추천 도메인 학회 논문들은 아래에 정리했다.
■ Session-based Recommendations with Recurrent Neural Networks
: 세션 log에 RNN을 적용해 추천을 하도록 연구했지만, 유저들의 선택에서 랜덤성이 너무 심한 문제점을 해결하지 못한 논문(세션의 main purpose를 구분하지 못했다)
■ Improved recurrent neural networks for session-based recommendations.
: RNN 계열 모델에 data-augmentation과 pre-training 기법을 사용해 성능을 올린 논문
■ Recurrent neural networks with top-k gains for session-based recommendations
: Ranking loss function을 RNN 계열의 모델에 적용한 논문
■ A Repeat Aware Neural Recommendation Machine for Session-based Recommendation
: Session based 추천 모델에서 반복되는 소비 현상을 발견하고 이를 추천 시스템에 통합하기 위해 encoder-decoder 형식의 모델을 고안하고 적용한 논문
■ Neural attentive session-based recommendation
유저들의 선택에서 나타난 랜덤성을 해결하기 위해 attention 모델을 적용해 유저의 current intention을 찾아냈다. 하지만 다음과 같은 문제가 있었다.
- attention 모델을 적용한 부분이 current session만 집중적으로 사용해 history information을 제대로 적용하지 못함
- static offline setting에서만 돌아가도록 실험 환경을 구축해, 실제 서비스에서 실시간성을 가지고 추천을 할 수 없음
■ STAMP: short-term attention/memory priority model for session-based recommendation
유저들의 마지막 클릭 데이터를 embedding 시켜서 유저의 short-term intention을 모델에 녹일 수 있도록 했다.
상기한 논문들은 대부분 current session 정보로 유저의 short-term 선호도만 얻어내는 것에 집중하고 있다. 반면 이하 논문들은 Long-term 정보를 잘 활용할 수 있다.
■ Self-Attentive Sequential Recommendation
Transformer Decoder 기반으로 Language Model 방식을 사용해 학습한다.
■ BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
Transformer Encoder 기반으로 Masked Language Model 방식으로 학습한다.
3. 홈쇼핑모아에서 Session based 추천 모델을 서비스하기 위해 고려해야 할 것들
그렇다면 이러한 모델을 홈쇼핑모아에서는 어떻게 학습하고 관리할 수 있을까?
실전에서 추천 모델 구축할 때는 여러 대회에서 진행하는 AI 해커톤이나 Kaggle 대회에서 모델링만 집중하는 환경과 많이 다르다.
첫번째로는 학습 로그들을 실시간으로 처리하고 지속적으로 모델을 학습시킬 수 있어야 한다. 실시간으로 생성되는 데이터들을 기반으로 학습한 딥러닝 모델을 서비스에 적용하려면 실시간으로 학습 데이터를 처리 및 관리할 수 있어야 한다.
우리가 구축한 Session based 추천 모델의 경우, 유저별로 추천 모델에 필요한 로그들만 필터링하고 이 로그들을 각 유저들에게 매핑시켜둬야 한다. 각각의 유저들 별로 유저의 로그들을 시간순으로 처리해야 하며 이러한 데이터들을 주기적으로 전처리하고 모델을 학습시킬 수 있는 시스템이 구축돼야 한다. 또한 모델은 주기적으로 학습돼야 하며, 학습이 끝난 뒤에는 서비스에 적용되고 있는 모델과 교체돼야 한다.
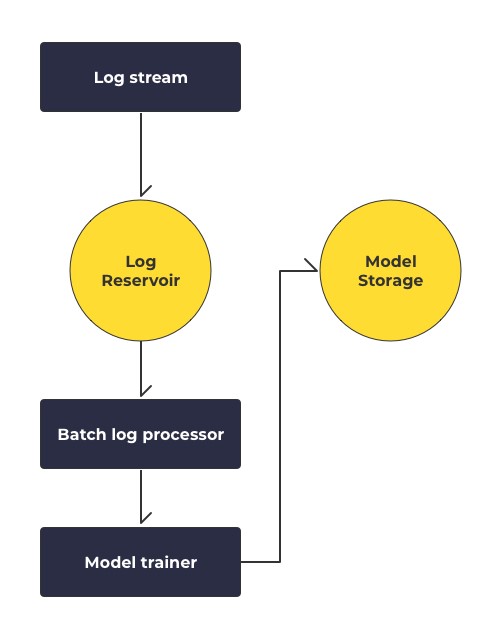
버즈니 추천팀에서는 홈쇼핑모아에서 생겨나는 여러 로그들 중 추천 모델에 필요한 로그들을 kafka stream을 통해 실시간으로 필터링하고 데이터베이스에 저장하고 있으며, 일정 기간의 로그들을 각각의 유저들별 log sequence로 표현하고 있다. 이러한 log sequence는 당연하게도 로그가 발생한 시간 순서대로 나열돼 있다. 이러한 학습 과정은 일정한 시간마다 반복되는 cron job으로 설정 돼 있으며, 학습이 완료될 때마다 Google Cloud Storage에 새로운 모델이 저장된다.
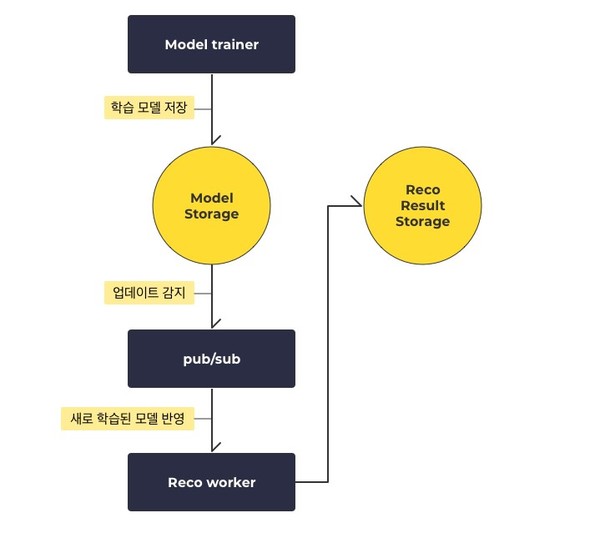
두 번째로는 지속적으로 학습되는 모델을 이용해서 빠르게 추천 결과들을 서비스에 제공 할 수 있어야 한다. 추천 시스템에서는 여러 추천 모델들이 업데이트가 되는 상황에서 체계적으로 여러 모델들의 update를 감지하고 모델 변경이 바로 서비스에 반영될 수 있어야 한다. 또한 여러 추천 모델들의 결과들을 안정성있고, 빠른 속도로 서비스에 제공해줄 수 있어야 한다.
이를 위해 버즈니 추천팀에서는 각각의 추천 결과들을 미리 뽑아서 key-value storage에 저장하는 방식을 사용하고 있다. 따라서 현재 학습된 추천 모델을 이용해서 추천 결과들을 저장하는 worker가 존재하며, 이 worker는 새로운 모델 파일이 갱신될 때마다 rollout restart를 통해 update 된다. 이 과정을 추천팀에서는 GCP에서 제공하는 pub/sub 기능을 사용하고 있다. pub/sub가 모델 저장소에서 일어나는 update를 감지하고 이에 맞도록 추천 결과들을 저장하는 worker들을 update 한다.
또한 추천팀이 개발한 추천 모델 중 Tensorflow 기반으로 개발된 모델의 경우 TF estimator 형식으로 모델을 관리하고 있고, 이 모델로 Google Tensorflow에서 제공하는 TF Serving을 통하여 Model API를 제공하고 있다. 이 API를 통해 다른 추천 모델과 동일하게 추천 결과들을 뽑아내고 추천 결과 저장소에 저장한다. 서비스에 사용되는 추천 API는 모두 reco result storage(key-value store)에서 뽑아 쓰는 형태이기 때문에 동일한 속도와 안정성을 가지고 추천 결과를 제공해 줄 수 있다.
세 번째로는 각각의 단계에서의 컴퓨팅 자원을 효과적으로 사용하고 관리할 수 있어야 한다. AI 모델 학습과, 관련 프로세스에서는 많은 컴퓨터 자원이 필요할 때가 많다. 각각의 과정 속에서 자원들이 효율적으로 관리되도록 하기 위해 홈쇼핑모아 추천팀에서는 추천 연관 프로세스들을 kubernetes에서 관리하고 있으며, 각각의 프로세스에 대한 필요 리소스와 최대 리소스들을 결정해 효율적으로 자원을 사용할 수 있도록 하고 있다.
앞으로는?
현재 홈쇼핑모아 추천팀에서는 여러 추천 모델들을 서비스에 적용하기 위해 A/B 테스팅을 진행하고 있다. 앞으로는 추천 모델을 안정적으로 서비스할 수 있도록 tensorflow extended ML pipeline을 활용해 실시간으로 추천 모델을 학습할 뿐만 아니라 자동화된 데이터 검증 및 추천 결과 검증 프로세스를 구축하려고 한다. 또한 홈쇼핑모아 유저에게 즐거운 쇼핑 경험을 제공하기 위해서 State of the art 추천 모델들을 지속적으로 연구 및 개발할 예정이다.