



학습용 데이터셋 1300종 확보해 AI 기술 발전 근간 다진다
[아이티데일리] 최근 IT 업계에서 가장 많은 이목을 집중시키고 있는 것은 정부의 디지털 뉴딜 프로젝트일 것이다. 코로나19로 인해 비대면 트렌드가 확산되고 이를 지원하기 위한 디지털 역량의 중요성이 높아지면서, 정부는 전 산업 분야의 디지털 역량을 강화하고 IT 기술 기반을 다지기 위한 디지털 뉴딜 프로젝트를 추진하고 있다. 오는 2022년까지 총 23조 4000억 원의 예산을 투입해 ▲D·N·A 생태계 강화 ▲교육 인프라 디지털화 ▲비대면 산업 육성 ▲SOC 디지털화 등 4개 대표 분야에서 12개 세부 과제를 추진한다.
‘AI 학습용 데이터 구축사업’은 디지털 뉴딜 정책의 핵심 과제 중 하나인 ‘데이터댐 구축’에서 가장 많은 주목을 받고 있는 사업이다. 국내 AI 생태계를 활성화시키기 위해, 정부 예산을 통해 상대적으로 미흡한 학습용 데이터 구축을 지원하겠다는 목표다.
① 디지털 뉴딜의 핵심 과제, ‘AI 학습용 데이터 구축사업’
② 사용자 수요 고려해 활용성 높은 데이터셋 마련
편의성‧사용성 고려한 수요자 중심 데이터셋 구축
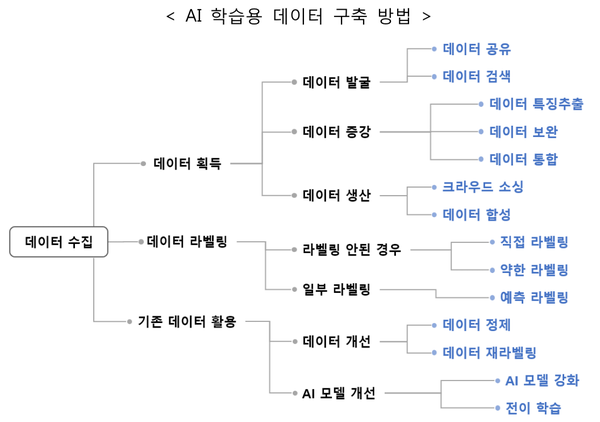
하지만 그동안 AI 학습용 데이터 구축사업의 결과는 썩 만족스럽지 않았다. 다수의 기업‧기관이 산발적으로 데이터를 수집하면서 데이터 간의 불균형이나 편향성 문제가 발생했고, AI 서비스를 개발하려는 수요자의 요구를 반영하기보다는 공급자의 편의에 따라 데이터셋을 만들다보니 현장에서의 실효성에 대해서도 의문이 제기됐다. 수요자를 고려하지 않다보니 필요 이상으로 데이터 자체의 정확도에 집중해 역량이 낭비되는 경우도 있었다. 또한 데이터 구축이 일회성 프로젝트로 진행돼 시간이 지남에 따라 정확성이 떨어지거나 누락된 데이터가 발생하기도 했다.
특히 데이터의 성질을 표현해야 하는 라벨링 작업에서 명확한 가이드라인이 세워져 있지 않아 라벨링 작업자/검수자/수요자 간에 이해가 부족해 기껏 만들어놓은 데이터의 활용성이 떨어지기도 했다. 데이터 라벨링을 자동화하는 기술이 활성화돼있지 않다보니 대부분의 라벨링을 수동으로 진행해 시간과 비용 대비 성과도 아쉬웠다.
새롭게 추진된 ‘AI 학습용 데이터 구축사업’에서는 이러한 부분을 인지하고 개선하기 위한 시도가 나오고 있다. 이전에 추진했던 사업들의 성과와 실책을 참조해 학습용 데이터 구축 방법론을 체계화하고, 산업 분야와 데이터의 성질에 따라 수요층의 요구와 비용을 저울질해 가장 최적화된 방식으로 구축한다.
특히 공급자 중심으로 구축됐던 데이터셋을 보다 수요자 중심으로 개선한다. 가령 데이터셋을 개별 컴퓨팅 환경에 다운받지 않고 클라우드 기반으로 활용할 수 있도록 해 보다 편리하게 사용할 수 있도록 하고, 수요자의 개발 환경이나 깃허브(Github)와의 연동을 지원해 개발자 중심으로 개선한다. 또한 한 번 구축된 데이터셋도 지속적으로 품질 관리가 이뤄질 수 있도록, 정확하지 않은 데이터를 새로운 데이터로 재구축하거나 대규모 데이터 품질 검증‧관리 절차를 구체적으로 마련할 계획이다. 이외에도 AI 서비스의 학습 결과에 영향을 미칠 수 있는 데이터셋의 편향성을 방지할 수 있도록, 데이터셋이 다양성과 특수성을 포괄해야 한다는 점을 RFP 상에 명시한다.
데이터 라벨링 프로세스도 개선한다. 수요자를 고려한 명확한 라벨링 가이드라인을 마련해 활용도를 높이는 것은 물론, 자동화된 라벨링 도구를 적극적으로 활용해 생산성 또한 향상시킨다. 특히 모든 데이터에 대해 동일한 라벨링 프로세스를 수행하는 것이 아니라, 데이터의 성질과 목적에 따라 요구되는 라벨 양과 품질을 구분함으로써 효율적인 라벨링 작업이 가능하도록 한다.
전문성 고려한 단계별 인재 양성 계획 수립
특히 이번 AI 학습용 데이터 구축사업에서 주목할만한 것은 크라우드소싱 방식을 보다 적극적으로 활용해 데이터 라벨링 등을 수행한다는 점이다. 데이터 라벨링 업무는 어렵지는 않지만 AI 학습용 데이터를 구축할 때 가장 많은 시간과 비용이 소요되는 업무다. 업종과 데이터의 종류에 따라 차이가 있으나 대체로 전체 비용의 60~80%는 데이터의 수집‧정제‧라벨링 작업에 소요된다. 이러한 업무에 비용효율인 크라우드소싱 방식을 적용함으로써 전반적인 사업 생산성을 높일 수 있을 것으로 예상된다.
일각에서는 크라우드소싱을 적극 활용한다는 점이 디지털 뉴딜 프로젝트가 추구하는 ‘일자리 창출’과는 배치되는 것이 아니냐고 지적한다. 실제로 데이터 라벨링 업무에 크라우드소싱 방식이 빈번이 이뤄지기는 하지만, 이는 일회성으로 아르바이트 형식의 일자리를 만들 수는 있겠으나 장기적인 고용을 보장하지는 않기 때문이다.
참여기업 입장에서는 이번 사업을 진행하는 동안 단기적으로 지원이 필요한 것이기에 지속적으로 근무할 인력을 채용하기에는 부담이 된다. 이번 사업에 참여한 A사 관계자는 “라벨링 자동화 도구와 크라우드소싱 방식을 활용하고 있다”며, “데이터 라벨링 업무만을 위해 정규직 인력을 채용하는 것은 비효율적”이라고 선을 그었다. ‘데이터 라벨링’은 IT나 데이터에 대한 지식이 부족한 비전문가도 할 수 있을 정도로 업무 난이도가 낮고 단순반복적이라 ‘IT 업계의 눈알 붙이기’로 불릴 정도이기에, 보다 적은 비용으로 많은 업무량을 소화할 수 있는 크라우드소싱 방식이 보다 효과적이라는 것은 부정할 수 없다. 하지만 단기 아르바이트 형식의 고용 창출로는 업계에서 원하는 데이터 전문가 양성도 요원한 일이다.
이에 대해 AI 학습용 데이터 구축사업을 진두지휘하는 한국정보화진흥원(NIA)은 데이터 인재 양성 전략을 세 가지 경우로 나누어봐야 한다고 설명했다. ▲단순 데이터를 구축하는 1단계에게는 기본 교육을 지원해 인력풀을 확장하고 ▲데이터 라벨링을 수행하는 2단계에게는 데이터라벨링 기술과 통계적 전문지식을 위한 커리큘럼을 제공하며 ▲소수의 데이터 전문가로 구성된 3단계에게는 실무 경험을 쌓고 전문성을 강화할 수 있도록 중‧소규모 데이터 구축 과제를 마련해야 한다는 것이다. 고용창출이라는 명분으로 필요치 않은 고용을 무리하게 독려하기보다, 담당업무와 역량에 따라 단계별로 구분해 효과적인 인재 양성 전략을 수립해야 한다.
2025년까지 학습용 데이터셋 1300종 확보
향후 AI 학습용 데이터 구축사업은 2025년까지 1,300여 종의 데이터셋 구축을 목표로 한다. 지난해 12월에는 음성‧자연어, 비전, 헬스케어, 농‧축‧수산, 교통, 재난‧안전‧환경 등 6개 분야에서 총 200여 종에 달하는 후보 과제를 발굴했으며, 지난 1월에는 제조‧금융‧교육 등 전략분야를 포함한 7개 분야에서 110개의 과제 후보안을 공개했다. 이후 민간기업과 공공기관, 학계 전문가들의 의견을 수렴해 중장기 로드맵을 새롭게 수립하고 추진할 계획이다.
한편 NIA 측은 AI 학습용 데이터셋을 반복적으로 대량 생산하는 것은 시간과 비용 측면에서 합리적이지 않으므로, 데이터가 부족하더라도 AI 모델의 성능을 개선할 수 있는 방안에 대해 고민해야 한다고 조언했다. AI 산업 환경이 변화함에 따라 기존의 데이터셋을 최신화하고 품질을 관리하는 작업은 필요하겠지만, 이번과 같이 대규모 예산을 투입해 새로운 데이터셋을 처음부터 만들어내는 것은 지양하겠다는 의도로 풀이된다. 또한 현재 연구 중인 분야별 AI 학습 모델만이 아니라, 오픈API가 공개한 GPT-3(Generation Pre-trained Transformer 3)과 같이 대규모 범용 AI 모델에 대한 대비와 정책도 함께 필요하다고 조언했다.