


위세아이텍, ‘머신러닝 자동화 플랫폼 동향과 적용사례’ 세미나 개최
[아이티데일리] 위세아이텍(대표 김종현)이 지난달 15일 ‘머신러닝 자동화 플랫폼 동향과 적용사례’를 주제로 온라인 세미나를 개최했다.
이번 세미나는 다양한 산업분야에서 활용되고 있는 머신러닝 기술 트렌드를 살펴보는 한편, 복잡한 머신러닝 과정을 간소화‧자동화해주는 머신러닝 자동화 플랫폼의 발전방향을 살펴보는 자리로 마련됐다. 또한 그간 위세아이텍이 경험한 실제 머신러닝 프로젝트 사례를 바탕으로 오늘날 산업현장에서 머신러닝과 AI 기술이 어떻게 활용되고 있는지를 살펴볼 수 있었다.
머신러닝 프로세스 자동화하는 ‘와이즈프로핏’
첫 번째 세션은 김지혁 위세아이텍 연구소장이 ‘오토ML(AutoML) 플랫폼의 의사결정 지원 전략’이라는 주제로 발표에 나섰다. 김지혁 연구소장은 먼저 “오토ML은 실제 비즈니스 문제에 머신러닝을 적용하는 전체 과정을 자동화하는 것을 의미하며, 이를 통해 비전문가도 머신러닝 모델과 기술을 업무에 활용할 수 있다”고 말했다.
AI와 머신러닝 기술은 오늘날 다양한 산업군에서 주목받는 트렌드지만, 경험이 부족한 기업들이 손쉽게 따라할 수 있는 분야는 아니다. 트렌드를 따라가야 한다는 이유만으로 계획 없이 머신러닝 프로젝트를 시작할 경우 복잡한 기술적 어려움에 부딪히기 쉽고, 어떻게든 머신러닝 모델을 완성해 운용하더라도 충분한 성과를 기대하기 어렵다. 머신러닝 모델 개발 과정은 개발 환경 구축에서부터 모델 평가 및 최적화에 이르기까지 복잡한 과정을 수행해야 하기 때문이다.
가트너는 지난 2019년 10대 전략 기술 트렌드에 ‘AI 주도 개발’을 포함시키며 오토ML에 대해 언급했다. ‘AI 주도 개발’이란 AI 기반의 머신러닝 자동화 도구를 활용해 비전문가도 코딩 없이 머신러닝 기술을 활용할 수 있는 방법을 의미하며, 오토ML은 구글이 ‘머신러닝의 민주화’라는 슬로건을 통해 공개한 대표적인 머신러닝 자동화 도구다. 또한 머신러닝 자동화의 핵심 기업 중 하나인 데이터로봇은 “오토ML을 통한 모델 개발은 전체 머신러닝 모델 구현 공수의 70%를 줄일 수 있다”고 언급한 바 있다.
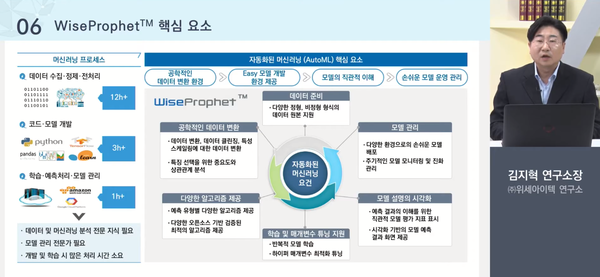
이러한 산업계의 요구에 발맞춰 위세아이텍은 자체 개발한 오토ML 플랫폼 와이즈프로핏(WISE Prophet)을 제공하고 있다. 와이즈프로핏은 전문지식이 부족한 사용자들이 손쉽게 사용할 수 있도록 머신러닝의 모든 과정을 GUI 기반으로 간소화했다. 사용자는 직관적인 인터페이스에서 마우스 클릭만으로 고품질의 맞춤형 머신러닝 모델을 구축할 수 있다. 이를 통해 기업 내 IT 조직의 도움 없이도 머신러닝 기술을 활용할 수 있어, 기업은 모델 개발에 소요되는 자원과 인력, 시간을 최소화할 수 있게 된다.
와이즈프로핏은 정형/비정형 데이터는 물론 데이터 변환‧정제‧스케일링 등 공학적인 데이터 변환을 모두 지원한다. 데이터로부터 특징(feature)을 추출하고 선정하기 위한 중요도 및 상관관계 분석, 반복적인 모델 학습을 통한 하이퍼 매개변수 최적화 역시 가능하다. 또한 지도학습에 사용되는 분류/회귀 알고리즘과 비지도 학습에 사용되는 클러스터링 알고리즘도 제공하는 등, 자주 사용되는 검증된 최신 알고리즘들이 지속적으로 업데이트되고 있다.
김지혁 연구소장은 “디지털 뉴딜 정책의 일환으로 AI 학습용 데이터 구축사업이 활발히 진행되고 있으며, 특히 텍스트‧이미지‧음성‧동영상과 같은 비정형 데이터의 수요가 증가하고 있다. 아직 비정형 데이터에 대한 오토ML 기술 적용은 단순 분류 모델에 한정돼 있지만, 향후 더 적은 자원으로 비정형 데이터를 학습할 수 있는 기술이 뒷받침된다면 더 다양한 문제를 해결하는 데에 머신러닝을 활용할 수 있을 것”이라고 덧붙였다.
강화학습을 통한 보험금 부당청구 탐지 모델
이어서 조아 위세아이텍 연구소 책임연구원이 오토ML 플랫폼을 활용해 보험금 부당청구 탐지 모델에 강화학습(Reinforcement Learning)을 적용한 사례에 대해 발표했다.
보험사기의 일종인 보험금 부당청구는 매해 증가하고 있다. 금융감독원이 발표한 바에 따르면 2015년 보험금 부당청구액은 약 6,500억 원이었지만, 2019년에는 8,800억 원까지 증가했다. 특히 사기 수법이 다양화되면서 기존의 룰 기반 탐지모델이 새로운 사기 패턴을 탐지하지 못하는 한계를 보이게 되자, 머신러닝‧딥러닝 기술을 활용해 새로운 사기 패턴에도 즉각 대응할 수 있는 지능형 부당청구 탐지모델에 대한 수요가 생겨났다.

위세아이텍은 와이즈프로핏에 강화학습 방법론을 적용해 보험금 부당청구 탐지모델을 구현했다. 강화학습이란 머신러닝 모델이 시행착오를 겪으며 최대의 보상을 얻을 수 있는 행동을 찾고 스스로 교정하는 방법이다. 정해진 환경(Environment)에서 학습을 위한 데이터를 사전 정의된 에이전트(Agent)에 전달하면, 에이전트는 전달받은 데이터를 바탕으로 행동을 결정한다. 그러면 환경은 에이전트의 행동을 확인하고 적절한 보상(Reward)를 제공한다. 이러한 과정을 반복하며 에이전트는 환경으로부터 가장 많은 보상을 획득할 수 있도록 스스로의 행동 패턴을 교정해나가게 된다.
특히 보험금 부당청구 탐지모델에서는 적대적 환경에서의 강화학습 방법이 적용됐다. 적대적 환경의 강화학습이란 복수의 에이전트가 서로 경쟁/협동하면서 최적의 의사결정을 학습하는 방법론을 의미한다. 이러한 방법이 필요한 이유는 보험금 청구 데이터가 극단적인 불균형을 이루고 있기 때문이다. 전체 보험금 청구량에 비해 부당청구가 차지하는 비율은 극히 적다. 머신러닝에서는 SMOTE와 같은 샘플링 기법도 사용할 수 있지만, 그럼에도 불구하고 부당청구 탐지 정확도는 낮게 나타났다.
위세아이텍은 적대적 환경의 강화학습 방법을 적용해, 메인 에이전트에게 데이터를 제공하는 환경 내에 서브 에이전트를 추가했다. 서브 에이전트는 시뮬레이션을 통해 메인 에이전트의 예측 정확도를 계산하고, 정확도가 낮은 샘플에 더 높은 보상을 준다. 이를 통해 메인 에이전트는 예측 정확도가 낮은 데이터 샘플을 우선적으로 학습하고 더 자주 노출되게 된다. 서브 에이전트가 오히려 잘못된 샘플에 보상을 줌으로써, 메인 에이전트가 정상 데이터라는 쉬운 문제와 사기 데이터라는 심화 문제를 균형있게 풀어나가며 학습의 성능을 높인다.
이와 같은 강화학습 방법을 머신러닝 모델에 적용한 결과 기존의 부당청구 탐지 모델 대비 10% 이상 성능이 향상됐다. 특히 데이터가 적어 학습이 어려운 부당청구 샘플에 대한 탐지 정확도가 기존 모델 대비 20% 이상 높아져 확실한 성능 향상을 확인할 수 있었다.
끝으로 조아 책임연구원은 기업에서 강화학습을 통한 머신러닝을 적용하고자 한다면 ▲비즈니스 문제에 적합한 환경‧보상‧에이전트 정의 ▲반복적인 실험을 통해 최적화된 보상값 결정 등에 주의해야 한다고 조언했다. 특히 에이전트는 항상 보상을 최대화하는 방향으로 행동을 교정하게 되므로 적절한 보상값을 설정해야만 학습 능력과 정확도를 높일 수 있으며, 보상값을 설계할 때에는 도메인 지식을 가진 비즈니스 전문가와 데이터 분석가 간의 협업이 필요하다고 강조했다.
빅데이터 기반의 엔지니어링 프로젝트 관리 시스템
다음 세션은 ‘AI 기반 엔지니어링 빅데이터 분석’이라는 주제로 김건민 위세아이텍 연구소 선임연구원과 김현수 상아매니지먼트컨설팅 부장이 나섰다. 해당 세션에서는 엔지니어링 산업계에서 AI 및 빅데이터 기술을 적용하기 위한 방법을 공유하고, 플랜트 엔지니어링 산업계에서 프로세스를 최적화하기 위해 신규 시스템을 개발한 사례를 소개했다.
기존의 엔지니어링 산업계는 ▲프로젝트 데이터의 DB화가 부족하고 ▲프로젝트 데이터에 대한 분석 시스템이 미흡해 ▲전문가 개개인의 경험과 지식에 크게 의존한다는 문제에 직면해있었다. 따라서 각종 프로젝트 실적을 DB화하고, 이를 분석해 비즈니스 리스크를 확인하고 대응하기 위한 데이터 기반의 의사결정 체계를 마련하고자 했다. 이에 위세아이텍은 빅데이터와 AI 기술을 이용해 ▲프로젝트 원가 예측 ▲설계 및 시공 과정 리스크 분석 ▲고장 진단 및 비용 절감 등 고도화된 운영 관리 체계를 갖춘 지능형 의사결정 시스템을 구현했다.
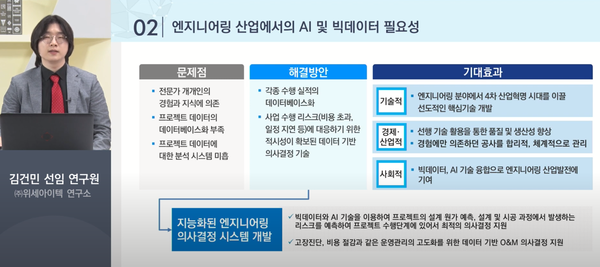
해당 시스템은 ▲엔지니어링 전 주기에서 발생하는 데이터를 수집‧저장하는 지식 베이스 ▲데이터 전처리와 모델 학습‧운영 등을 지원하는 머신러닝 플랫폼 ▲단계별 데이터를 활용해 실제 인사이트를 제공하는 의사결정 지원 시스템 ▲레퍼런스 데이터를 정리하고 의사결정 지원 기술의 분석 결과를 시각화하는 프로젝트 단위 적용 시스템 등으로 구성됐다.
위세아이텍은 이렇게 개발한 지능형 의사결정 시스템을 다양한 플랜트 엔지니어링 현장에 직접 적용했다. 지능형 의사결정 시스템은 ▲NASA 터보 팬 엔진 데이터를 분석해 잔존 유효 수명(RUL, Remailning Useful Life) 계산 ▲고틱스(Gotix) 기어박스 진동 데이터 분석 ▲폐수 처리 시설의 펌프 데이터를 분석해 정비 수요 예측 등 실제 산업 현장에서 우수한 성과를 거뒀다. 특히 유지 보수(O&M, Operation&Maintenance) 단계의 데이터는 종류가 복잡하고 다양해, 수집된 데이터의 특징을 파악하고 제각기 다른 분석 과정을 선택하는 것이 중요하다고 강조했다.
3D 도면 관리하는 금형 빅데이터 시스템
이어서 위세아이텍 연구소 이지현 선임연구원과 임수연 선임연구원이 ‘AI 기반의 비정형 데이터 분석 사례’를 공유했다.
먼저 이지현 선임연구원은 금형 산업 분야에서 딥러닝 기술을 활용해 금형 데이터를 분석한 사례를 발표했다. 금형 산업은 제조업에서 제품의 대량 생산을 위한 틀을 만들어내는 분야로, 흔히 제조업을 위한 제조업으로 불리는 다품종 소량생산 산업이다. 국내 금형 산업계는 높은 기술력과 뛰어난 완성도를 바탕으로 전 세계 생산량 5위를 기록하고 있다.
하지만 국내 금형 산업계는 89.5%가 50인 미만의 중소기업으로 구성돼있다는 한계도 가지고 있다. 중소규모 금형기업에서는 제각기 다른 기준으로 제품 도면을 만드는 데다 도면의 DB화도 제대로 수행하지 않고 있다. 새로운 금형을 설계할 때는 각 개인의 노하우와 과거의 도면 데이터를 참조하게 되는데, 잦은 인력 변동과 데이터 관리 소홀로 인해 제품 설계 시간이 증가하고 반복적인 오류가 발생하는 것이다. 이러한 문제를 해결하기 위해 위세아이텍은 과거의 도면 데이터를 체계적으로 관리하고, 필요에 따라 원하는 금형 도면을 손쉽게 찾을 수 있는 ‘금형 빅데이터 시스템’을 구축하게 됐다.
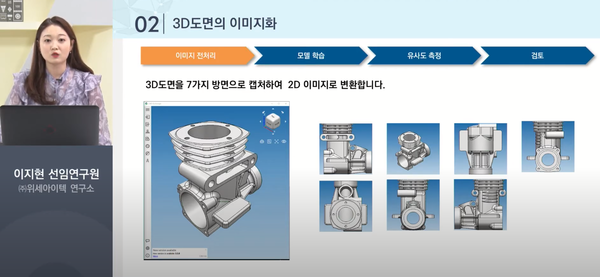
해당 시스템을 구축하면서 가장 먼저 문제가 된 것은 딥러닝 기술을 활용하기 위한 도면 데이터가 턱없이 부족하다는 점이었다. 문제를 해결하기 위해 위세아이텍은 이미지 데이터의 전처리 과정에서 3D 도면을 7가지 방면에서 캡처해 2D 이미지로 변환했다. 이 방법은 현시점에서 2D 이미지 처리 기술이 3D 이미지 처리 기술보다 진보해있다는 점과 맞물려, 모델 정확도를 보다 향상시킬 수 있다는 이점도 있었다. 또한 도면 데이터라는 특징을 고려해 기준점 제거, 병합된 도면 분리 등의 방법을 통해 학습 모델이 제품 형상을 좀 더 쉽게 확인할 수 있도록 변환했다.
모델 학습 과정에서는 이미지넷에서 우수한 성능을 보인 바 있는 VGG16 모델과 인풋 데이터에서 중요한 특징을 추출해주는 오토인코더(AutoEncoder)를 결합했다. 일상 이미지를 학습하며 성능을 높인 VGG16 모델은 전이 학습(Transfer Leaning)을 통해 3D 도면 이미지에 최적화시켰으며, 오토인코더는 인풋 데이터의 중요한 특징 벡터를 추출해 유사도 분석에 활용할 수 있도록 했다.
자연어처리를 활용한 기술문서 리스크 분석
끝으로 임수연 선임연구원은 ‘텍스트 기반의 기술문서 분석 사례’에 대해 발표했다. 임수연 선임연구원은 기술문서(ITB, Invitation to Bid)란 엔지니어링 산업계의 입찰안내서라고 소개하며, 대규모 엔지니어링 프로젝트에서는 수백 페이지에 달하는 기술문서를 점검하고 리스크 분석을 수행해야 한다고 설명했다. 하지만 자연어처리(NLP) 기술을 활용한다면 기술문서를 손쉽게 분석하고 리스크 요소를 점검할 수 있다.
NLP 기술을 활용해 기술문서를 검토하기 위해서는 엔지니어링 및 기술문서에 대한 전문가와 데이터 분석 전문가가 협력할 필요가 있었다. 기술문서에는 일반적으로 사용되지 않는 어려운 단어들이 다수 사용되며, 문장 또한 복문과 장문 등으로 복잡하게 구성돼 있어 이해가 어렵기 때문이다. 엔지니어링 분야에 대한 전문지식 없이는 영문으로 작성된 기술문서를 번역하기도 쉽지 않다. 이에 위세아이텍은 이을범 포항공대 철강대학원 교수와 협력해 기술문서에 대한 리스크 분석 솔루션을 개발했다.
가장 먼저 리스크 요소를 정의해 DB화하는 작업이 필요했다. 무엇보다 NLP 기술을 적용해 리스크 요소를 확인하기 위해서는 무엇이 리스크를 만들어낼 수 있는지를 알아야 하기 때문이다.
위세아이텍과 이을범 교수는 ▲리스크가 많이 발생하는 단어(Word) ▲두 개 이상의 리스크 단어로 구성된 구(Phrase) ▲리스크를 감당하는 주체와 행위를 연결하는 절(Clause) ▲리스크에 대해 완결된 내용을 담은 문장(Sentence) 등으로 구분해 리스크 요소를 정의했다. 이를 바탕으로 리스크 분류 체계와 어휘집을 만들어 텍스트 분석에 활용할 수 있도록 DB를 만들었다.

실제 기술문서 분석에는 데이터 정형화부터 추출에 이르기까지 전 과정에 NLP 기술이 적용됐다. 여기에는 일반적인 룰 베이스에 더해 머신러닝‧딥러닝 알고리즘이 모두 활용됐다. 텍스트 분석을 위한 전처리로 불용어 제거와 워드 임베딩(word embedding)을 수행했으며, 기술문서를 구성하는 문장이 대체로 길다는 점을 고려해 LSTM(Long Short Term Memory) 알고리즘을 메인으로 모델을 구성했다. 특히 LSTM 알고리즘은 장기 의존성(long-term dependencies) 문제, 즉 은닉층의 과거 정보가 마지막 단계까지 전달되지 못하는 현상을 보완할 수 있어 기술문서 분석에 탁월한 효과를 보였다.
현재 위세아이텍의 기술문서 분석 솔루션은 ▲PDF 정형화 ▲상업계약서 분석 ▲기술사양서 분석 ▲리스크 영향도 평가 등 4가지 모듈로 구성돼있다. 이어서 임수연 선임연구원은 각각의 모듈을 실제로 사용하는 모습을 시연하며, GUI 기반의 간소화된 화면에서 효과적으로 기술문서의 리스크 요소를 분석하는 방법을 소개했다.