


정윤진 피보탈 랩 프린시플 테크놀로지스트
[컴퓨터월드]

| 1. 스프링 부트 <2017.5월호> 2. 스프링 클라우드 Config server <2017.6월호> 3. 스프링 클라우드 Service discovery <2017.7월호> 4. 스프링 클라우드 Zipkin <2017.8월호> 5. 스프링 클라우드 Zuul <이번호> 6. 스프링 클라우드 Hystrix |
클라우드 기반의 애플리케이션 아키텍처를 이야기할 때 빠지기 힘든 주제 중 하나가 ‘사용자 요청을 어떻게 백엔드 서비스로 적절히 분리해낼 것인가’이다. 이것은 단순히 요청을 순차적으로 백엔드 서버에 할당하는 방식의 분배 문제를 포함, 요청이 어떤 것인지 구분해 백엔드에 전달하는 기술을 동시에 구현해야 한다.
웹의 초창기에 이런 부분은 네트워크적인 접근에서 처리됐다. 도메인에 연결된 ‘로드 밸런서’라는 네트워크 장치의 역할은 외부 인터넷으로부터 받은 모든 HTTP/s 요청에 대해 내부에 등록된 서버들로 전달하고, 서버로부터의 응답을 대신해 전달하거나 분배만 밸런서가 하고 응답은 서버가 직접 클라이언트에 수행하는 등의 방식(DSR)으로 구현했다. 이런 네트워크적인 접근방식은 우리가 익히 들어 알고 있는 OSI 7 Layer 구분방법에 따라 구분했는데, 예를 들면 L4 또는 L7과 같은 ‘네트워크 장치’들이 있었다.
여담이지만, 한국의 인터넷 쇼핑몰들을 보면 상품을 설명하기 위한 이미지의 크기가 상당한 경우를 자주 볼 수 있다. 경우에 따라서는 수십 메가바이트의 이미지를 보기도 하는데, 그것도 하나의 이미지가 아니라 이런 이미지를 여러 개 붙여서 상품을 설명한다.
이런 경우 요청을 받은 웹서버가 자바(Java)나 PHP를 구동하는 동시에 하나의 요청에 대한 응답으로 수십 MB의 파일을 클라이언트에 전송해야 한다면, 이 이미지 전송 부분이 굉장한 오버헤드가 아닐 수 없다. 요청의 처리를 위한 콘텍스트 스위칭으로 인해 비효율성이 매우 증가하고, 캐시의 효율이 떨어지며, TCP 패킷의 재전송 등의 보이지 않는 실패와 재시도가 서버의 성능을 좀먹기도 하는 데다, 상품에 관심이 떨어져 다른 페이지로 이동하는 브라우저가 발생하면 자원의 낭비가 시작된다. 이 모든 것들은 서비스의 품질을 기하급수적으로 낮추게 되는데, 이로 인해 ‘이미지 서버 팜’이라는 구현을 원하게 된다.
이에 대해 현재 CDN(콘텐츠전송망)이 많은 부분을 처리해주고 있기도 한데, 업체 간 경쟁의 심화로 합리적 가격에 사용할 수 있는 서비스들이 많지만 그 이전의 시점에는 직접 구현해야 하는 경우가 많았다. 이 경우 이미지만을 전문으로 처리하는 서버들을 따로 로드 밸런서로 그룹화하고 유입되는 요청을 크게 두 가지로 처리하는 것이 일반적이었다. 첫 번째는 ‘서브 도메인’, 즉 image.우리쇼핑몰.com과 www.우리쇼핑몰.com 등의 형태로 구분하고 각각의 밸런서를 별도로 두는 형태다. 다른 하나는 www.우리쇼핑몰.com/images/*와 www.우리쇼핑몰.com/uploads/* 등의 방식으로 구분하는 것이다.
물론 밸런서에 메모리를 많이 추가하고, 이미지나 파일과 관련된 요청에만 캐시를 적용할 수도 있다. 물론 이런 콘텐츠의 전송에 gzip과 같은 압축을 적용하는 방법으로 대역폭의 소비를 줄이고 전송시간을 빠르게 하는 방법을 제공하는 등 다양한 형태로 진화하는 구간이기도 했으며, 이런 기능들은 모두 이제 CDN의 일부로 흡수됐다고 볼 수 있다.
이런 트래픽 흐름의 조정에 종전의 네트워크의 장비에만 의존하기 힘든 상태의 서비스들이 출현하면서 밸런서의 성능에 따른 비용을 추가하는 것보다 ‘리버스 프록시’라는 기법을 사용한 서버를 추가하는 방법이 대두되기 시작했다. 즉, 이제 더 이상 네트워크의 주소 체계를 사용하는 형태만 사용하는 기법 대신 실제 클라이언트의 요청이 ‘어떤 것인지’ 확인하고 이를 적절한 내부 서버로 전달하는 기능이 서비스들에 추가된 것이다.
클라이언트의 요청을 확인한다는 것은 바로 밸런서가 분배 처리를 위해 마치 웹서버처럼 요청을 받아서 확인을 할 수 있다는 말이다. 요청의 확인은 보통 클라이언트가 사용한 브라우저 또는 장치의 종류, 어디서 접속해왔는지 등과 같은 지리정보, 어떤 HTTP 메소드를 사용했는지, 예를 들면 GET, PUT, POST, DELETE 중 어느 것인지 등등 각종 헤더 정보를 포함한 요청내용을 바탕으로 더 세밀한 분배를 하게 될 수 있었다. 이런 세밀한 분배정책의 사용은 물론 일정부분 오버헤드를 수반하지만, 더 다양한 분배 시나리오를 지원함으로서 서비스의 가용성을 높일 수 있는 방법을 제공한다.
그리고 이런 기능성은 단순히 외부 요청에 대해서만 동작하는 것이 아니라, 내부 서버의 응답에 대해서도 적용할 수 있다. 예를 들면 외부 클라이언트로부터 전달받은 요청을 특정 내부 서버에 전달했는데 할당받은 내부 서버가 5xx 관련 에러를 발생시켰다면, 이 응답을 클라이언트에 그대로 전달하는 대신 내부의 다른 서버에 요청, 즉 클라이언트 대신 서비스에 요청을 다시 시도하는 동작을 구현할 수도 있게 된다. 이 모든 방법들은 서비스의 신뢰를 향상시키며, 가용성을 높일 수 있는 방법이다.
모바일을 필두로 한 ‘데이터 폭발’ 현상이 발생하고, 이 수많은 장치에서 생산되는 트래픽의 처리를 위해 인기 있는 서비스들은 클라우드 서비스로 옮겨가기 시작한다. 클라우드 서비스는 종량제 과금 방식으로, 서버를 몇 대 사용했는지에 대한 단위 시간 비용에 따라 운영비용이 달라지지만, 필요한 만큼 서버를 바로 할당해 사용할 수 있는 장점을 통해 가변적 서비스 운용이 가능해졌다.
이 가변적 서비스 운용이라는 측면을 밸런서에 대입해보자면, 일단 리버스 프록시나 밸런서들은 특정 요청 또는 URI에 대해 매핑될 서버 클러스터를 사전에 등록해야 한다. 그리고 이 등록에 변경이 발생할 때마다 프락시의 프로세스 재시작을 요구한다. 프로세스의 재시작은 즉 서비스의 순단을 의미하며, 이 동안은 클라이언트와 서버 사이에 트래픽이 흐르지 않음을 의미한다.
이런 문제를 해결하기 위해, 넷플릭스와 같은 회사들은 앞서 설명한 ‘유레카’와 같은 서비스 디스커버리 도구를 프락시와 백엔드 서비스 모두에 적용해 서로가 서로의 네트워크적인 위치를 애플리케이션에서 참조할 수 있도록 하는 모델을 만들었다. 즉, 동적으로 변경되는 자원들의 네트워크적인 위치를 계속 업데이트함으로써, 생겨나고 없어지는 자원들을 순식간에 활용할 수 있도록 하는 것이다.
여기에 프락시를 구성한 것이 기본적으로 넷플릭스의 ‘주울(Zuul)’이라고 볼 수 있다. 백엔드의 어디에서 어떤 애플리케이션이 동작하고 있는지에 대한 정보는 유레카를 통해서 받고, 이렇게 얻은 정보를 통해 요청을 전달하는 역할을 하는 것이 이 Zuul이라는 도구가 하는 역할이다.

추가적으로 중요한 몇 가지 사실이 더 있다. 첫째로, 지금까지 이야기해왔던 분배의 모델을 모두 적용할 수 있어야 한다. 둘째로, 이 프락시 도구 자체가 동적으로 확장과 축소가 가능해야 트래픽을 제한 없이 처리할 수 있다는 것이다. 셋째로, 이 구간은 서비스에 유입되는 모든 트래픽이 통과하는 구간이라는 점이다.
이 세 번째 역할이 새롭게 다뤄지는 부분인데, ‘모든’ 트래픽이 오고가는 부분이라는 것은 다음과 같은 장점을 가질 수 있게 된다.
▶ 서비스에 유입되는 모든 요청과 서비스가 응답하는 모든 요청을 ‘기록’할 수 있다.
▶ 서비스에 유입되는 모든 요청과 서비스가 응답하는 모든 요청을 ‘변조’할 수 있다.
▶ 서비스에 유입되는 모든 요청을 확인하기 때문에, 보안을 적용하기 좋다. 즉, 게이트 키퍼 역할을 한다.
▶ 다수의 서비스에 대한 모니터링이 가능하다. 즉, 특정 기능을 하는 API 호출에 대해 지연시간 등을 보기 좋다.
▶ API의 종류별로 요청에 응답을 제공하기 위해 적절한 백엔드를 다양한 방법으로 선택하는 것이 가능하다. 즉, API 게이트웨이(Gateway)의 역할을 한다.
이러한 이해를 바탕으로, Zuul이 제공하는 기능은 아래와 같은 것들이 있다. 넷플릭스는 영화 이름이나 영화에 나오는 캐릭터 이름으로 소프트웨어 이름을 자주 짓는데, Zuul은 영화 ‘고스트 버스터즈’에서 지옥문을 지키는 게이트 키퍼다.
▶ 인증 및 보안: 각 요청이 갖춰야 할 내용을 충족하지 못한 경우 해당 요청을 거부한다.
▶ 모니터링: 모든 트래픽이 지나기 때문에 의미 있는 데이터와 지표를 수집할 수 있다.
▶ 동적 라우팅: 필요에 따라 즉시 원하는 백엔드 클러스터로 트래픽을 보내고 끊을 수 있다.
▶ 부하 테스트: 신규 추가한 서비스 또는 백엔드에 트래픽을 점진적으로 증가하는 등의 방식으로 부하를 유발할 수 있다.
▶ 트래픽 드롭(정확히는 Shedding): 각 요청에 대해 제한된 이상의 요청이 발생한 경우 이를 드롭하는 방식을 사용할 수 있다.
▶ 정적 응답 처리: 특정 요청에 대해서는 백엔드로 트래픽을 보내는 대신 즉시 응답하도록 구성할 수 있다.
▶ 멀티 리전 고가용성: Zuul은 받은 요청을 아마존웹서비스(AWS)의 리전 레벨에서 분배할 수 있다.
그리고 넷플릭스가 추가적으로 사용하고 있는 기능성은 아래와 같다.
▶ 테스트 & 업데이트 : 넷플릭스 규모의 마이크로서비스 구성에서는 어떤 테스트는 반드시 프로덕션을 통해서만 가능한 경우가 발생한다. 이때 신규 서비스를 배포하고, 전체 트래픽 중 아주 일부의 트래픽만 흘려 테스트를 수행하고 있다. 또는 이 개념을 조금 더 확장해서 Canary 테스트로 사용할 수도 있다. 배포 전 신규 버전의 서비스를 준비하고, 이 신 버전으로 구 버전을 대체하기 전에 동일한 요청에 대해 아주 작은 양의 트래픽만 신 버전으로 흘린다. 로그를 모니터링하고, 테스트를 통과해 서비스에 문제가 없다는 것이 확인되면 트래픽의 비율을 조정한다. 자연스럽게 구 버전으로 흐르는 트래픽은 감소하고 신 버전은 증가하며, 구 버전에 더 이상의 트래픽이 처리되지 않으면 모두 terminate한다.
▶ FIT(Fault Injection Test): 굉장히 넷플릭스다운 도구인데, 클라이언트의 요청을 특정 시나리오에 맞게 변조해 서비스가 정상 동작하는지 테스트한다. 즉 악의적 사용자가 사용할법한 공격을 서비스에 대고 직접 수행함으로써 이에 대한 면역력을 키우는 방법으로 보안성을 높여가는 것이다. 단순히 보안성뿐만 아니라 보안 위협으로 인해 발생할 수 있는 가용성 문제, 그리고 실제 동작하는지 테스트를 수행함으로써 프로덕션의 운영에서 동일한 문제가 발생하더라도 강성을 확보할 수 있는 방법을 제공한다.

SpringOne platform에서 넷플릭스의 Zuul 담당 디렉터가 다양한 내용을 소개해줬다. 넷플릭스는 Zuul을 사용해 50개 이상의 ELB로 트래픽을 분배하고, 3개의 AWS 리전을 사용하고 있으며, 넷플릭스 서비스의 대부분의 트래픽을 처리하고 있다고 했다. 그리고 이 도구를 Edge-gateway라고 부르고 있다. infoq.com 계정이 있는 이들은 Netflix의 Zuul 매니저의 발표를 다음 링크를 통해 확인할 수 있다.
https://www.infoq.com/presentations/netflix-gateway-zuul?utm_source=infoq&utm_medium=QCon_EarlyAccessVideos&utm_campaign=SpringOnePlatform2016
넷플릭스가 공개하고 있는 Zuul에 대한 정보는 아래 링크에서 더 찾아볼 수 있다.
https://github.com/Netflix/zuul/wiki
https://github.com/Netflix/zuul/wiki/How-We-Use-Zuul-At-Netflix
이전의 내용들과 마찬가지로, 스프링 클라우드에서는 이 마이크로 프록시를 사용하기 쉽게 제공하고 있다. 그리고 이 도구는 일전에 구성한 Config, Zipkin, Eureka 등의 도구와 연동해 클라우드에서 동적인 확장과 축소, 그리고 자원의 분배를 처리할 수 있다. start.spring.io로 접근해 마이크로서비스 구조를 만들어보기로 한다. 다이어그램은 아래와 같다.
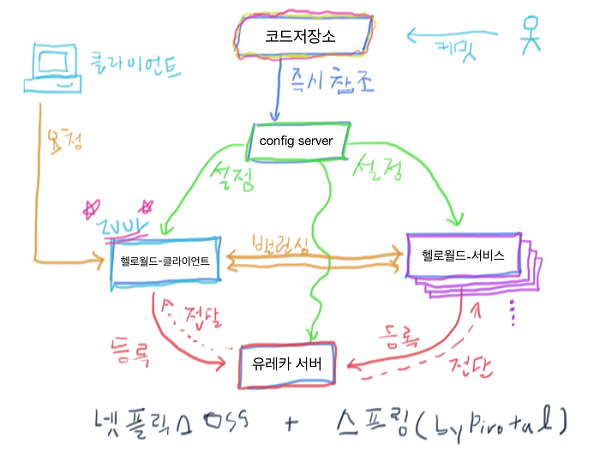
Zuul proxy의 동작만을 확인하는 간단한 코드는 spring cloud 프로젝트에서도 참조할 수 있으며, 아래의 github 링크를 참조하면 된다. 간단한 데모이므로 별도의 암호화 처리 등은 없다. 본 데모에서 가장 중요한 것은 온라인 설정의 업데이트, 유레카를 참조한 로드 밸런싱의 처리다.
https://github.com/younjinjeong/demo-config
https://github.com/younjinjeong/spring-cloud-zuul-proxy-demo
Config server 구성
● github.com에 가서 신규 repository를 만든다. (위 demo-config 참조)
● 애플리케이션의 properties 파일을 생성한다:
application.properties / helloworld-service.properties / helloworld-client.properties / discovery-service.properties
https://github.com/younjinjeong/demo-config 참조
● bootstrap.properties 파일에 spring.cloud.config.uri 주소를 조정한다.
● Config server를 시작한다.
Discovery-service
● start.spring.io에 접근한다.
● artifact에 discovery-service
● dependencies에 eureka server, config client를 추가하고 프로젝트를 다운받는다.
● 설정은 demo-config의 discovery-service를 참조
Helloworld-service
● http://start.spring.io로 접근한다.
● artifact에 helloworld-service 대신 더 상상력 넘치는 이름을 준다.
● dependancies에 web, rest repositories, actuator, actuator docs, config client, eureka discovery를 적용한다.
● Generate project를 눌러 프로젝트 파일을 다운로드받고, IDE를 사용해서 연다. 아래와 같이 간단한 코드를 작성한다.
| package com.example; import org.springframework.boot.SpringApplication; @SpringBootApplication public static void main(String[] args) { @RefreshScope @Value("${message}") @Value("${eureka.instance.metadataMap.instanceId}") @RequestMapping("/") @RequestMapping("/id") |
Helloworld-client
실제 Zuul proxy가 동작하는 구간이다. 보통 edge-service라는 이름을 사용하기도 한다.
● http://start.spring.io 접근한다.
● artifact에 helloworld-client 대신 더 상상력 넘치는 이름을 준다.
● dependancies에 Zuul, Config client, Discovery client, Ribbon을 적용한다.
● Generate project를 눌러 프로젝트 파일을 다운로드받고, IDE를 사용해서 연다.
Zuul Proxy를 사용하기 위해서는 기본적으로는 어노테이션 추가 외에 아무것도 할 일이 없다.
| package com.example; import org.springframework.boot.SpringApplication; @SpringBootApplication public static void main(String[] args) { |
당연한 말이지만 라우팅 설정이 필요하다. 설정에 대한 내용은 demo-config 저장소의 helloworld-client.properties를 살펴볼 필요가 있다. 아래의 설정을 살펴보자.
| server.port=${PORT:9999} info.component="Zuul Proxy" endpoints.restart.enabled=true zuul.ignored-services='*' #route 규칙은 zuul.routes.스프링애플리케이션이름=path ribbon.ConnectTimeout=3000 |
정리해보면,
▶ helloworld-service는 백엔드 서비스로 동작한다. 두개의 RequestMap을 가지는데, 하나는 “/” 요청에 대해 설정파일에 주어진 메시지를 응답하는 것이고, 다른 하나는 /id로 현재 동작중인 인스턴스의 정보를 서버의 정보를 리턴한다. 즉, 동일한 애플리케이션을 로컬에서 서로 다른 포트로 동작하거나, 실제 클라우드에 배포해 로드 밸런싱이 정상적으로 수행되는지 확인할 수 있다.
▶ helloworld-client는 edge 서비스로서 zuul proxy를 사용하고, 유레카를 통해 얻어진 백엔드 서버 정보를 기반으로 ribbon을 사용해 로드 밸런싱한다.
▶ 라우팅 규칙은 “zuul.routes.[유레카를통해 얻어진 spring.application.name]=경로”로 구성된다.
▶ 위에 설명한 기능을 제공하기 위한 더 많은 설정이 존재한다.
Config Server, Discovery service, helloworld-service, helloworld-client의 순서대로 애플리케이션을 구동한다. localhost:8000/ 으로 요청해 서비스가 정상 동작하는지 확인한다. 정상적이라면 Hello world!를 볼 수 있다.
| $ curl http://localhost:8000/ Hello World! |
먼저 서비스의 재시작 없이 설정을 변경하는 방법을 위의 메시지 처리를 통해 확인해보자. demo-config/helloworld-service에서 message 설정을 원하는 메시지로 변경한다. 변경했으면, 연결된 커밋, 푸시한다. 설정이 정상적으로 반영됐다면, Config 서버에서는 변경된 최신의 설정을 바로 참조하고 있으나 서비스에는 반영이 안 된 것을 확인할 수 있다. 아래의 주소로 접근하면 message의 내용이 변경됐고 이를 config server가 들고 있는 것을 확인할 수 있다.
http://localhost:8888/helloworld-service/default
| { name: "https://github.com/younjinjeong/demo-config/helloworld-service.properties", source: { server.port: "${PORT:8000}", message: "Spring Cloud is awesome! " } } |
서비스에 바로 반영되지 않는 것은 원래 그렇게 디자인했기 때문이다. 설정이 변경될 때마다 자동으로 서비스에 반영하는 것은 위험할 수도 있으며, config server에 부담을 주지 않기 위한 것도 있다. 서비스에 변경을 적용하려면, 지난번에 설명한 바와 같이 empty post 요청을 다음과 같이 전달하면 된다.
| $ curl -X POST http://localhost:8000/refresh ["message"] |
정상적으로 동작했다면, 어떤 내용이 변경돼 반영됬는지 리턴될 것이다. 그럼 이제 백엔드 서비스로 다시 직접 요청해보도록 하자.
| $ curl http://localhost:8000/ Spring Cloud is awesome! |
이 동작이 의미하는 바는 무엇인가. 설정을 변경하고 프로세스 재시작, 재배포와 같은 과정을 별도로 수행하지 않아도 변경된 설정이 동작중인 서비스에 즉각 반영할 수 있는 메커니즘이 있다는 것이다. 이러한 방법은 Config server / client를 통해 동작하며, 이는 당연하게도 Zuul proxy의 라우팅 변경에도 사용할 수 있는 것이다. 즉, 신규 애플리케이션을 만들어 동작하고 있는 중이라면, 해당 애플리케이션으로의 트래픽을 서비스 재시작 없이 변경하거나 추가할 수 있다는 의미가 된다.
이제 로드 밸런싱을 살펴보자. 포트 8000에서 동작하고 있는 서비스는 백엔드다. 그리고 Zuul 은 9999 포트에서 동작중이다. 그리고 오늘의 주제와 마찬가지로 Zuul이 정상적으로 프록싱을 수행하고 있는지 확인해보도록 하자. 위의 라우팅 규칙에 따르면, Zuul proxy 서버의 /hello로 요청하게 되면 위 메시지가 리턴돼야 한다.
| $ curl http://localhost:9999/hello Spring Cloud is awesome! |
사실 helloworld-client 애플리케이션에 보면 딱히 한 것도 없다. 그럼에도 불구하고 프록싱은 정상적으로 동작하고 있는 것이다. 이제 밸런싱을 확인해야 하는데, 위의 메시지는 설정 서버로부터 동일하게 가져와 반영되는 것이므로 밸런싱이 정상적으로 동작하는지 확인하기가 쉽지 않다. 따라서 동일한 백엔드 서비스를 다른 포트로 동작하게 하고 실제 밸런싱이 되는지 확인해보자. 아래의 커맨드를 사용하면 동일한 애플리케이션을 다른 포트로 구동할 수 있다.
| # helloworld-service 디렉토리로 이동하여 먼저 빌드를 수행한다 PORT=8989 java -jar target/helloworld-service-0.0.1-SNAPSHOT.jar |
유레카 서비스를 확인해보면, 새로 구동한 백엔드 서비스가 HELLOWORLD-SERVICE 애플리케이션으로 2개의 인스턴스에서 동작하고 있는 것을 확인할 수 있다.
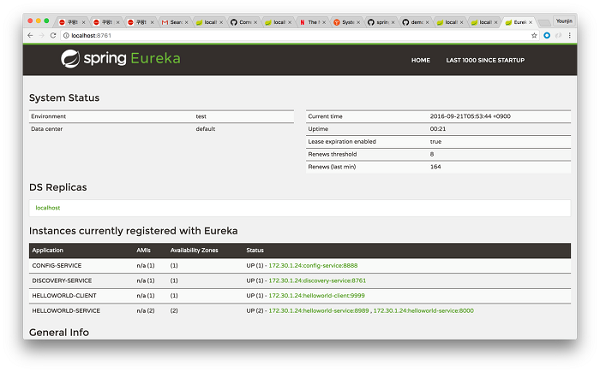
localhost:9999/hello/id로 요청을 수행하면 서비스 이름:포트 정보가 나타나는데, 반복적으로 요청을 수행하면 8000 포트와 8989 포트가 번갈아가며 나타난다. 즉, 정상적으로 로드 밸런싱이 수행되고 있는 것이다. 다시 8989로 동작중인 애플리케이션을 종료하게 되면 이는 즉시 밸런싱에서 제외되고 8000번만 나타난다. 이것은 무엇을 의미하는가. 바로 동적으로 멤버의 추가와 제거가 발생하고, 이 정보가 즉각 참조돼 서비스-인, 서비스-아웃을 수행할 수 있다는 것이다.
이러한 사용성은 필요에 따라서 전 세계에 위치한 데이터센터 중 내가 원하는 지역의 어디로든 트래픽을 동적으로 분산할 수 있는 유연성을 제공한다. 그리고 이런 동작은 그 어떤 프로세스의 재시작도 없이, 그 어떤 애플리케이션의 재배포도 없이 가능하다. 이런 구성이 바로 클라우드에서 동적으로 생성되고 삭제되는 각종 서비스와 그 서비스에 할당된 애플리케이션 인스턴스를 서비스에 사용하고 제거하는 ‘클라우드에 맞는’ 방법인 것이다.
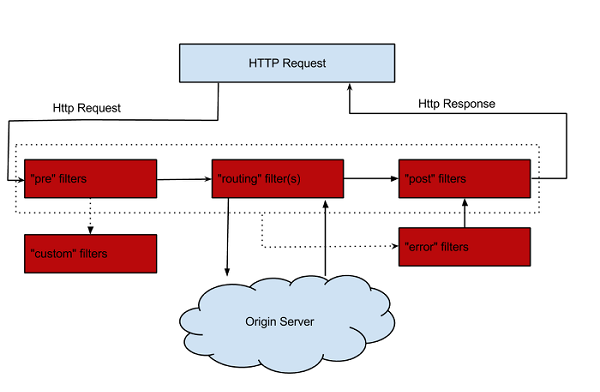
Zuul을 사용해 필터를 적용할 수 있다. 필터는 클라이언트의 HTTP 요청을 받고 응답하는 과정에서 리퀘스트를 라우팅하는 동안 어떤 액션을 수행할지에 대한 범위를 지정하는 역할을 한다. 아래는 몇 가지 Zuul의 필터에 대한 특징이다.
▶ Type: 리퀘스트/리스폰스 라우팅되는 동안 필터 적용 상태의 변경을 정의
▶ Execution order: Type 안에 적용되는, 여러 개의 필터 적용 순서를 정의
▶ Criteria: 순서대로 실행될 필터에 필요한 조건들
▶ Action: Criteria, 즉 조건이 매칭하는 경우 수행할 액션
필터에는 아래의 타입들이 존재한다.
▶ PRE: 백엔드 서버로 라우팅 되기 전에 수행되는 필터. 예를 들어 요청에 대한 인증, 백엔드 서버의 선택, 로깅과 디버깅 정보.
▶ ROUTING: 요청을 백엔드로 라우팅을 제어할 때 사용되는 필터. 이 필터를 통해 Apache HttpClient 또는 넷플릭스 Ribbon을 사용해 백엔드 서버로 요청을 라우팅한다.
▶ POST: 백엔드 서버로 요청이 라우팅되고 난 후에 수행되는 필터. 예를 들면 클라이언트로 보낼 응답에 스탠다드 HTTP 헤더를 추가한다든가, 각종 지표나 메트릭을 수집하거나 백엔드에서 클라이언트로 응답을 스트리밍하는 것 등이다.
▶ ERROR: 위의 세 단계 중 하나에서 에러가 발생하면 실행되는 필터
Zuul은 사용자에게 커스텀 필터 타입을 정의하고 사용할 수 있도록 한다. 따라서 특정 요청을 백엔드로 보내지 않고 바로 클라이언트에 응답을 수행하는 것과 같은 구성이 가능하다. 넷플릭스에서는 이런 기능을 내부의 엔드포인트를 사용해 Zuul 인스턴스의 디버그 데이터 수집에 사용하고 있다고 한다. 아래는 Zuul 내부에서의 요청이 어떤 흐름을 갖는지 보여주는 좋은 그림이다.
스프링에서 Zuul 필터의 사용은 아래의 두 코드를 살펴보자. 먼저 com.netflix.zuul.ZuulFilter를 익스텐드해서 pre 필터를 생성한다. helloworld-client 애플리케이션에 아래의 파일을 추가한다.
spring-cloud-zuul-proxy-demo/helloworld-client/src/main/java/com/example/filters/pre/SimpleFilter.java
| package com.example.filters.pre; import com.netflix.zuul.ZuulFilter; import javax.servlet.http.HttpServletRequest; public class SimpleFilter extends ZuulFilter { private static Logger log = LoggerFactory.getLogger(SimpleFilter.class); @Override @Override @Override @Override log.info(String.format("%s request to %s", request.getMethod(), request.getRequestURL().toString())); return null; } |
● filterType()은 필터의 타입을 String으로 리턴한다. 이 경우 pre이며, 만약 route에 적용했다면 route가 리턴된다.
● filterOroder()는 필터가 적용될 순서를 지정하는데 사용된다.
● shouldFilter()이 필터가 실행될 조건을 지정한다. 위 설명에서 Criteria 부분
● run() 필터가 할 일을 지정한다.
spring-cloud-zuul-proxy-demo/helloworld-client/src/main/java/com/example/HelloworldClientApplication.java
| package com.example; import org.springframework.boot.SpringApplication; @SpringBootApplication public static void main(String[] args) { @Bean |
curl http://localhost:9999/hello/id 로 요청을 해보면, 아래와 같은 로그를 확인할 수 있다.
| 2016-09-22 17:58:33.798 INFO 7307 --- [nio-9999-exec-6] com.example.filters.pre.SimpleFilter : GET request to http://localhost:9999/hello/id |
지금까지 소개한 Config Server, Eureka, Zuul 등 세 개의 도구는 모두 스프링 클라우드의 도구다. 스프링 클라우드에서는 클라우드에 맞는 서비스 연동을 제공하기 위해 이러한 넷플릭스 오픈소스들을 넷플릭스와 함께 만들고 있다. 피보탈의 스프링팀은 보다 범용적 사용을 위해, 스프링 클라우드 프로젝트에 API게이트웨이를 새로운 버전으로 구현하고 있다.