


계산량이 높은 머신러닝에서 적합한 하이퍼매개변수 자동화 탐색 방법

[아이티데일리] 머신러닝(ML) 알고리즘에서 학습 성능에 영향을 미치는 적합한 매개 변수(Parameter)를 선택하는 것은 학습 모델의 성능을 결정할 수 있는 매우 중요한 작업이다. 최근 대규모 데이터를 기반으로 고성능 모델을 확보하기 위한 학습 시간이 늘어나고 있다. 예를 들어 모델 레이어가 어느 정도 깊이 있는 인공신경망(DNN, Deep Neural Network) 기반의 모델은 많은 학습 데이터를 필요로 하고, 계산량이 많기 때문에 학습 속도가 느릴 수밖에 없다. 현업에서 단순한 DNN ML 모델의 경우에도 최적의 하이퍼매개변수를 찾는데 수 시간 내지는 수 일이 소요될 수 있다.
데이터 사이언스 파이프라인 과정은 데이터 수집과 구축, 큐레이션, 통계적 분석과 ML 등 다양한 기술과 지식을 활용해 복잡한 데이터로부터 인사이트를 얻거나 인공 지능(AI) 기반의 자동화 시스템을 구현하기 위한 업무를 의미한다.
해당 파이프라인은 크게 ML을 이용한 분류/예측 자동화 모델 구현 엔지니어링 부분과 탐색적 데이터 및 시각화 분석(Exploratory Data Analysis, EDA) 과정으로 나눌 수 있다. 이 중 ML 모델 최적화 과정은 원시(RAW) 데이터의 규모가 커지며 ML에 사용할 학습 데이터가 증가함에 따라 성능이 좋은 모델을 학습하기 위해 충분한 컴퓨팅 자원과 학습 시간이 요구되고 있다. 따라서, 모델 학습의 성능을 결정하는 매개 변수들을 탐색하는 최적화 과정의 자동화에 대한 관심도 높아지고 있다.
이번 기고에서는 ML알고리즘을 자동 설계하는 영역 중, ML 모델의 학습 과정에서 높은 성능을 결정하는 매개 변수들의 값을 자동화 탐색하는 다양한 방법들을 소개한다.
AutoML의 종류와 하이퍼매개변수 최적화
자동화 기계학습(AutoML)은 반복적인 ML모델을 개발 및 성능을 높이는 작업을 자동화하는 것을 의미한다. 기존에 성능이 좋은 모델을 구현하기 위해서는 도메인 경험이 풍부한 ML 개발자나 데이터 과학자(data scientist)가 필요했다. 모델 학습과 연관된 데이터를 선정 및 전처리하고, 이들이 모델 학습 과정에서 경험에 의존하여 학습 매개 변수들을 직접 변경해가며 수십 개의 모델 학습을 반복해 테스트하며 최적의 매개 변수 값들을 찾곤 했다.
그러나 ML 모델이 복잡해지고, 학습에 필요한 데이터가 증가하면서 ML모델 성능을 결정하는 최적화 영역은 사람이 수동으로 탐색하기에는 비용이 커지고 있다. [1]
AutoML은 ML을 이용해서 모델을 설계하는 방법으로, 모델 레이어를 탐색하는 검색 스페이스(Search Space), 탐색 방법 최적화인 검색 전략(Search Strategy), 여러 레이어 디자인 후보 중 성능을 바탕으로 더 좋은 모델을 선택하는 성과 측정 전략(Performance Estimation Strategy)으로 구분된다. AutoML에 대한 연구는 아래와 같이 크게 세 가지 방향에서 이루어지고 있다.
● 신경 아키텍처 검색(Neural Architecture Search, NAS) : ML을 이용해 자동화된 신경망 레이어 구조를 디자인하는 방법이다. 모델 학습 레이어 컴포넌트(Component)의 최적화 탐색 방법은 하이퍼매개변수 최적화에서 사용되는 방법론과(Feurer and Hutter, 2019) 동일하다. [1]
● 자동화된 기능 학습(Automated Feature Learning) : 기능(Feature) 엔지니어링은 전체 데이터 집합의 많은 정보를 하나의 테이블로 나타내는 새로운 기능(설명 변수, 또는 예측 변수)을 만드는 과정이다. ML에서 자동화된 기능 엔지니어링은 데이터 세트에서 수백 또는 수천 개의 새로운 기능변수들을 자동으로 생성해 ML개발자나 데이터 과학자가 기능 변수 생성 문제 해결을 돕는 것을 의미한다.
● 하이퍼매개변수 최적화(Hyperparameter-Optimization, HPO) : HPO는 학습이 완료되었을 때, ML 모델 학습에서 높은 성능의 모델이 도출되도록 결정하는 모델 학습 매개 변수들을 역으로 찾는 과정을 말한다.[2] 따라서 하이퍼매개변수 튜닝 작업은 모델 학습의 필수적인 부분이며 학습 데이터가 증가함에 따라 모델의 학습 계산량도 증가해 모델 학습 과정 중 가장 시간이 많이 걸리는 작업 중 하나다.
최근 BERT(Bidirectional Encoder Representations from Transformer)나 GPT와 같은 트랜스포머(Transformer) 기반의 계산량이 많은 ML모델이 등장하면서 시간과 비용이 크게 증가하고 있는 추세다.
기계학습 과정에서 학습 데이터셋이 커짐에 따라 모델의 높은 성능을 얻기 위한 비용이 커지고 있다. 여기에서는 AutoML 중 기계학습 과정에서 학습 성능을 결정하는 매개 변수 선정과 반복적인 학습을 통해 모델의 성능을 높이는 과정인 하이퍼매개변수 최적화 방법에 대해 알아본다.
하이퍼매개변수 최적화(HPO) 개념
모델 매개 변수 튜닝은 학습 데이터와 학습 모델 알고리즘이 결정되어 있을 때, ML 모델의 성능을 결정짓는 매개 변수들을 사용해서 반복 탐색 학습을 시도하고, 모델의 성능이 높아질 때 매개 변수들을 기록한 뒤 최적의 탐색 결과를 도출하는 작업이다. 문제는 이러한 매개 변수를 찾기 위해서는 반복적인 학습 과정을 통해 결과를 얻고, 다시 매개 변수의 조정을 통해 다음 결과와 비교하며 찾아가야 하는 등 많은 컴퓨팅 자원은 물론 시간과 비용이 크게 소요되는 작업이라는 데 있다.
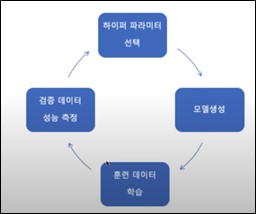
이러한 모델 매개 변수 튜닝 작업에 대한 최적화를 하이퍼매개변수 최적화라고 부른다. 하이퍼매개변수 최적화에서 비용 함수는 아래와 같이 에너지 함수로 나타낼 수 있다.
![그림2. 하이퍼매개변수 최적화 비용함수 출처 : J. Bergstra외 [3]](https://cdn.itdaily.kr/news/photo/202209/210339_212625_5911.jpg)
<그림 2>에서, 비용 함수는 모델 학습 알고리즘 A와 학습 데이터 셋 x가 있을 때 학습 응답 함수가 최소 에러를 나타낼 수 있도록 하는 하이퍼매개변수 λ를 찾는다. 여기서 ℒ은 비용함수, ψ는 하이퍼매개변수 응답 함수, Gx는 표본(sample) x에 대한 자연분포(natural distribution)를 의미한다. 위와 같이 ML 모델 알고리즘 A의 비용함수를 한번 더 래핑(wrapping)한 비용 함수의 최적화 과정이기 때문에 한번 더 차원을 높였다는 의미로써 λ를 하이퍼매개변수라고 부른다.
예를 들어, 분류 모델 학습에서 학습과정에서 출력되는 검증 정확도(Validation Accuracy)는 하이퍼매개변수 응답 함수이고, 에폭(epoch), 학습 속도(learning rate), 배치 사이즈(batch size)와 같은 매개 변수나 경사하강법(gradient decent) 알고리즘, 옵티마이저 등은 하이퍼매개변수라고 볼 수 있다.
경험에 의존하여 모델 매개 변수를 튜닝하는 과정을 가정해보자. 먼저 ML모델을 디자인하고, 학습을 위한 초기 매개 변수들을 선택하게 된다. 그리고 반복적으로 학습을 진행하고 연구 노트에 결과 성능이 좋게 나온 몇 가지의 매개 변수 셋을 기입한다. 그렇게 최적의 값을 결정한 학습모델을 애플리케이션 프로그램 인터페이스(API)로 제공하고 잘 동작하다 입력 학습 데이터셋에 데이터 드리프트(Data drift, 새로운 학습 데이터셋과 기존 모델에 사용한 데이터셋 사이에 분포에 변화가 발생하는 경우 데이터 사이 편향이 증가하고, 기존 모델의 성능이 떨어지는 것을 의미)가 발생하거나 또한 매개 변수의 조정 개수를 추가하는 경우도 ψ하이퍼매개변수 응답함수의 형태가 변하게 된다. 그리고 팀 미팅을 통해 출력 레이블 개수 조정을 결정하고 난 후 기존 모델에서 사용한 최적화는 새로운 학습에서 잘 동작하지 않게 된다.
아래 그림은 ML모델 학습 성능 튜닝 과정에서 사람의 경험에 의존하여 매개 변수를 찾는 과정에 대한 예시다.
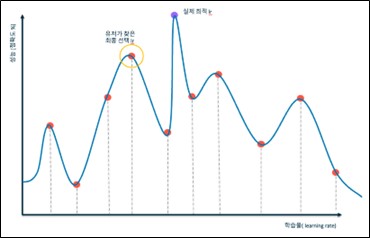
하이퍼매개변수를 찾는 과정에서, 학습 속도 매개변수에 따른 원하는 미지의 응답 함수 그래프가 파란 실선이고, 붉은 점은 사람이 수동 학습을 통해 얻은 매개 변수일때 사용자는 지금까지의 학습에 경험에 의존해서 learning rate값을 10번 대입하고 성능을 비교한 다음, 10번의 성능 결과 중 가장 성능이 높았던 하이퍼매개변수인 주황색 점을 찾는다. 그런데 그림과 같이 최종적으로 사람이 찾은 해의 오른쪽에 실제 응답함수의 성능이 가장 높았을 해(파란색 점)가 존재한다. 경험에 의존하는 방법의 더 큰 문제는 하이퍼매개변수들의 종류를 추가하거나 제외할수록 푸른색 응답함수의 convex함수 형태도 변한다는데 있다.
최근 큰 학습데이터셋을 사용하는 딥러닝 모델들과 학습을 결정하는 매개 변수들이 증가하면서 좋은 성능을 내는 기계학습 모델의 학습 매개 변수를 찾기가 점점 더 어려워지고 있다.
따라서 보다 효율적으로 기계학습 모델의 성능을 결정하는 매개 변수들을 찾는 방법을 자동화하는 하이퍼매개변수 최적화 방법들에 대한 필요성이 대두되고 있다.
하이퍼매개변수 최적화 알고리즘의 종류
하이퍼매개변수를 자동화 하는 방법은 크게 초기 설정한 컴퓨팅 자원을 소모하며 해를 찾는 Exhaust 검색[2][3], 컴퓨팅 자원의 재분배를 통해 해의 검색 속도를 높이는 Successive Halving 알고리즘기반 검색[4][7], 통계적인 목적함수의 분포를 기반으로 하는 베이지안(Bayesian) 기반 최적화[5][6] 방법이 있다.
1. Exhaust 검색
Exahust 검색알고리즘은 빠른 컴퓨팅 연산 성능을 기반으로 학습을 탐색하는 알고리즘 방식이다. 대표적인 알고리즘으로 그리드 서치(Grid Search)[2], 랜덤 서치(Random Search)[3]가 있다.
![그림4. 함수 최적화를 위한 9번 시도한 Grid 및 Random Search 예. 출처 : J. Bergstra 외[3]](https://cdn.itdaily.kr/news/photo/202209/210339_212627_5939.jpg)
그리드 서치는 하이퍼매개변수의 범위와 간격을 정해놓고, 각 범위의 경우에 모두 대입해 최적의 경우의 수를 찾는 방식이다. 예를 들어, 하이퍼매개변수가 4개이고, 각각의 범위에서 대입 가능한 값이 10개라고 가정하면 10x10x10x10으로 1만번의 탐색 시도를 하게 된다. 이 경우 Grid의 범위와 하이퍼매개변수의 수가 추가됨에 따라 계산량이 기하급수적으로 증가하기 때문에 하이퍼매개변수 응답함수의 해를 찾는 최적화 알고리즘은 경우 차원의 저주에 빠질 수 있는 단점이 있다.[2]
반면, 랜덤 서치[3]방식은 그리드 서치와 마찬가지로 무차별 대입(Brutal force) 탐색이지만 각각의 하이퍼매개변수는 독립이라고 가정하고, 모든 범위에서 대입 가능한 매개 변수들을 변경하며 빠르게 목적해를 찾는다. 컴퓨팅 연산능력이 높은 경우 범위 설정과 회수에 따라 응답함수의 최적 해를 찾는 속도가 빠른 편이다. 다만, 찾고자 하는 하이퍼매개변수의 종류가 많거나 각 매개 변수의 범위가 넓은 경우 응답함수의 최적화 결과는 반복 탐색 회수에 크게 영향을 받게 된다.
2. Successive Halving Algorithm기반의 하이퍼밴드 검색
Successive Halving Algorithm(SHA)[7]은 제한된 비용(Budget)에서 early stop을 기반으로 비용함수의 에러를 최소화 하는 방식이다. 이 방법은 하이퍼매개변수 최적화 검색 속도에 중점을 두고 있다.[7] 평가할 수 있는 매개 변수들을 빠르게 선정하고, 적절한 중간 학습 과정에서 결과 응답 함수의 값이 최적인 그룹을 남기고 나머지 학습을 중단(절반 혹은 1/3)한다. 추출된 소수 매개 변수들은 다음 중간 학습 과정에 사용하여 각 학습의 리소스의 할당과 학습량을 점점 크게 하여 매개 변수들을 찾는 방식이다. 사용하는 알고리즘의 흐름은 <그림 5>와 같다.
![그림5. SHA와 hyperband 알고리즘 출처 : K. Jamieson, Lisha Li 외 [4][7]](https://cdn.itdaily.kr/news/photo/202209/210339_212628_5953.jpg)
우선 하이퍼밴드 검색알고리즘의 기반이 되는 SHA의 경우, 처음 모든 매개 변수 탐색에 사용할 비용을 설정한다. 이때 비용t은 학습에 반복적으로 성능을 수렴하는 에폭이나 배치 반복이 될 수 있다. 그리고 n개의 하이퍼매개변수를 랜덤하게 선택한다. S는 반복 회수를 뜻하며 초기값의 경우 동일한 비용을 할당한 다음 학습을 진행하고 중간 소실을 추출한다. 중간 응답 함수의 결과를 기준으로 하위 성능 하이퍼매개변수들을 1/2만큼 버린다. 그 다음 하나의 매개 변수가 남을 때까지 반복한다.
예를 들어 찾는 하이퍼매개변수가 학습 속도(lr)이며 16개를 랜덤하게 뽑고(n=16), 모든 최적화에 제한한 에폭이(B=64), 그리고 탐색 도중 하위 성능 매개 변수를 절반을 제거((=2)한다면 아래와 같이 동작한다.
· lr 16개를 랜덤하게 추출해서 1 epoch(r0) 학습하고, 응답함수의 상위 성능 8개의 매개 변수만 추출하고, 나머지 학습 매개 변수들을 제거.
· 추출된 lr 8개를 선택해서 2 epoch(r1) 학습하고, 응답함수의 상위 성능 4개 매개 변수만 추출하고, 나머지 학습 매개 변수들을 제거.
· 추출된 lr 4개를 선택해서 4 epoch(r2) 학습하고, 응답함수의 상위 성능 2개 매개 변수만 추출하고, 나머지 학습 매개 변수들을 제거.
· 추출된 lr 2개를 선택해서 8 epoch(r1) 학습하고, 응답함수의 상위 성능 1개 매개 변수만 추출하고, 나머지 학습 매개 변수들을 제거.
따라서 프로세스가 사용한 총 에폭(Budget)은 64번이 된다. 그리고 단계별 탐색 학습은 16-8-4-2 순서의 개수로 프로세스가 제한된 컴퓨팅 자원을 사용하게 됨으로써 프로세스 당 탐색 속도가 가속화 된다.
하지만 SHA방식에서는 B와 n에 따라서 탐색과 활용(exploitation)의 비율이 정해지고, 최종 후보 매개 변수가 남았을 때 원하는 만큼의 비용을 설정할 수 없다는 불편함이 있었다.
하이퍼밴드[4]는 이러한 SHA의 단점을 보완한 알고리즘으로 마지막 하나의 매개 변수에 최대로 할당할 수 있는 비용을 설정(R)할 수 있어서 사전학습 모델의 파인 튜닝(Fine tunning)과 같이 일정 수준의 비용을 알고 있는 경우에 최적화 성능을 보다 좋게 도출할 수 있다. 하이퍼밴드는 R과 에 따라서 단계적으로 SHA를 반복하게 된다. 이때 총 비용은 SHA의 반복 회수 만큼으로 결정된다.B=(Smax +1)R
3. 통계적 베이지안 기반 최적화 알고리즘
통계적인 방법을 사용하는 HPO 탐색 방법 중 베이지안 최적화[5]는 가장 널리 알려진 알고리즘 중 하나이다. 목적 응답 함수의 임시 확률모델(Surrogate Probability Model)을 구축하고, 이 임시 모델을 최대로 하는 최적의 해를 찾는 방법이다.
하이퍼매개변수가 있을 때 최적화 모델을 찾는 확률은 베이지안 법칙을 사용해서 아래와 같이 나타낼 수 있다.

이 방법은 현재까지 얻은 모델성능(prior)과 그 모델 함수를 바탕으로 추가적인 탐험 정보(likelihood)를 통해서 매개 변수가 주어졌을 때의 모델성능(posterior)을 추정해 나가는 방식이다.
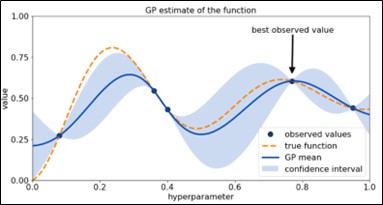
<그림 6>과 같이 알 수 없는 미지의 함수(주황색 점선)의 최대점을 찾는다고 가정하면, 임의의 검은색 점을 찍어서 GP 회귀(GP Regression)을 수행하면 사후분포 평균(posterior mean) 함수(푸른색 영역)와 사후분포 공분산(posterior covariance)(하늘색 영역)을 구할 수 있다. 이 중간 임시 사전정보 모델을 대체 모델(surrogate model)이라고 부른다. 대체 모델은 현재까지 조사된 입력 함수 값을 바탕으로 미지의 함수 형태 추정을 업데이트 하는 모델이다.
대체 모델 최대 관측 점 부근에서는 평균과 공분산이 높게 나타나는데, 이는 관측된 최대값 부근에서 가장 큰 목적 함수가 나올 확률이 높다는 것을 의미한다(Exploitation).
목적 함수에 대한 추정 결과로 관측 값을 추가해서 다시 GP 회귀를 반복 수행하는데 하늘색 영역은 관측된 두 점 사이의 거리가 먼(불확실한) 경우 아직 탐색하지 않은 영역으로 최적 관측 값이 나올 확률이 높은 것(exploration)을 뜻한다. 베이지안 획득(Bayesian Acquisition) 함수는 이 두 활용과 탐색의 확률적 추정 결과를 바탕으로 최적 해가 있을 만한 다음 검은 점을 추천해주게 된다.
베이지안 최적화은 그리드, 랜덤 탐색과 다르게 하이퍼매개변수를 선정하는 과정에서 이전 하이퍼 매개 변수로 얻어진 목적함수의 추정값을 사용해서 다음 매개 변수를 찾게 된다. 이러한 방식을 순차 모델기반 최적화(SMBO, Sequential model-based optimization)라고 한다. 통계적 정보를 활용해 다음 성능을 추정하기 때문에 모델의 성능이 높은 매개 변수를 찾을 확률이 높다.
다만 대체 모델은 일정 비용(컴퓨팅 자원)을 어느정도 사용하여 모델을 업데이트하기때문에 최적화 탐색 계산량이 비교적 높고, 만약 미지의 컨벡스(Convex) 함수가 평탄한 경우 함수의 업데이트 추정이 이뤄지지 않는 경우가 발생하기도 한다.
최근 대체 모델로 TPE(Tree Parzen Estimator)를 사용하는 방식[6]이 소개되었다.
조건부 확률에서 목적함수의 점수가 주어졌을 때 하이퍼매개변수의 확률을 최대화 업데이트하는 대체 모델은 아래와 같은 수식으로 나타낼 수 있다.

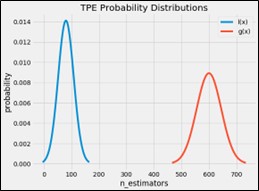
여기서 함수와 함수는 확률 분포를 의미하고, 목적함수의 점수인 score와 추정된 score*을 비교하여 두 개의 확률 분포로 나타낸다.
예를 들어, TPE의 대체 모델에서 아래와 같은 가우시안 커널을 이용한 확률밀도 분포 (hyperparameters)는 선호되는 분포, (hyperparameters)는 피해야 하는 분포로 분류된다.
하이퍼매개변수 최적화 알고리즘의 성능
하이퍼파리미터 최적화 알고리즘들에 대한 성능을 비교해봤다.[9] 데이터는 sklearn의 내장 데이터셋(dataset)인 당뇨병 데이터[8]를 사용했고, 모델은 회귀모델로 선정했다. 통제 조건은 동일 컴퓨팅 리소스를 사용한 환경에서 LightGBM 학습 모델과 매개 변수를 고정했으며 비용은 iteration 50으로 고정했다.
테스트에 사용한 당뇨병 토이 데이터는 일부 환자 및 대상 측정 항목에 대한 정보가 포함된 데이터로 ‘기준선 1년 이후 징병 진행의 정량적 측정’이라는 회귀 문제에 대한 간단한 모델링에 사용했다. 데이터 세트는 총 442개로 매우 작지만 HPO의 기본 개념을 쉽고 빠르게 보여줄 수 있기 때문에 선택했다. 학습데이터는 80%(353개), HPO로 생성한 모델의 검증을 위한 테스트 데이터 20%(89개)로 분리하고 HPO에는 80%의 데이터만 사용해 탐색했다. HPO로 탐색한 최종 학습 모델은 테스트 데이터를 사용하여 HPO 탐색된 결과와의 교차 검증 MSE를 측정했다.
HPO 테스트에는 LightGBM의 3개의 매개 변수[10]만 조정하는 모델을 최적화하였다.

하이퍼매개변수 최적화 알고리즘들의 수행속도와 버짓의 진행에 따른 각 알고리즘이 찾은 최적의 매개 변수들과 모델 스코어수렴 그래프를 출력한 결과는 다음과 같다.
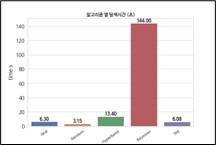
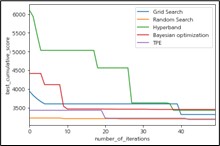

각 HPO 알고리즘을 동일한 조건에서 테스트해본 결과 랜덤 검색은 시간의 비용에 따른 스코어가 비교적 다른 방식에 비해 높은 것으로 나타났으나 초기에 좋은 최적 스코어를 찾은 다음 반복에 따른 변화의 개선이 적었다. TPE 알고리즘의 경우 테스트와는 별개로, 50번의 반복 이후 단계에서도 점진적으로 결과를 개선시켰다.
최적화 탐색 속도는 베이지안 최적화 검색이 가장 느렸다. HPO를 탐색하여 생성한 기계학습 모델들을 사용하여 탐색에 사용하지 않았던 20%의 테스트 데이터셋을 이용하여 교차 검증을 한 결과 TPE 알고리즘이 가장 모델 성능이 좋았다.
분산처리 기반 하이퍼매개변수 최적화 방법의 등장
최근 딥러닝 기계학습 모델(Deep Neural Network 기반의 모델들)의 레이어가 복잡해지고, 학습에 사용하는 데이터의 양이 기하급수적으로 늘어나면서 기계학습에 필요한 컴퓨팅 자원은 단일 컴퓨팅 용량을 넘어서는 경우가 많다. 예를 들어, 구글의 제이콥 델빈(Jacob Devlin)과 그의 동료들이 만든 2018년 등장한 BERT와 같은 자연어 처리(Natural Language Processing, NLP) 모델의 경우, 모델 레이어는 12개~16개의 자체 집중(self-attention) 헤드가 있는 24게의 인코더로 구성 되어있다.[11] 또한, 학습에는 8억개 이상의 자연어 말뭉치(corpus)[12]와 2,500M이상의 영어 Wikipedia를 사용하여 학습했다고 알려져 있다.
초기 개발자들이 이러한 무거운 기계학습 모델을 공개했기 때문에 우리는 파인튜닝이나 퓨샷러닝에 모델을 재 학습하고 활용하는 상황이지만, BERT나 GPT 기반의 기계학습 모델은 파인튜닝 마저도 시간과 컴퓨팅 자원의 소요가 많다. 빅데이터를 이용해서 이런 무거운 모델을 만들 때는 HPO 또한, 반복적인 학습과정을 통해 매개 변수 값들을 찾아야하기 때문에 컴퓨팅 자원 문제가 발생한다.
최근에는 분산환경에서 HPO 알고리즘 탐색 자체를 스케쥴링하고, 탐색 프로세스들을 자동화 코디네이팅 해주는 플렛폼들이 등장하고 있다.
잘 알려진 분산 환경 기반의HPO 코디네이터는 컨테이너 기반의 쿠버네티스(Kubernetes, K8S)환경에서 네이티브 프로젝트로써 제공되는 쿠브플로우 카티브(Kubeflow Katib)[13]이다. 카티브는 컨테이너화 시킨 HPO 알고리즘 탐색 프로세스 부분을 K8S의 분산 워커(worker) 클러스터에 배포하고, 각 프로세스들은 K8S의 코디네이팅 환경 아래에서 실행 동작한다. 쿠브플로우는 AutoML을 지원하며 K8S를 제공하는 모든(AWS, GCP, 마이크로소프트 애저 등) 클라우드 플랫폼에서 사용할 수 있다.
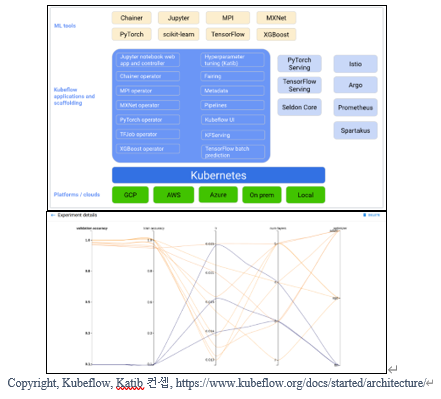
HPO를 컨테이너화 시키면 파이썬(Python) 라이브러리 패키지를 컨테이너 안에 종속시킬 수 있는 장점이 있다. 많은 사람들이 ML 서버 환경에서 동작했던 ML모델이 패키지 라이브러리 업데이트 후 동작하지 않은 경험을 했을 것이다. 컨테이너는 기계학습 라이브러리의 버전에서 오는 불편함에서 해방시켜줄 수 있다.
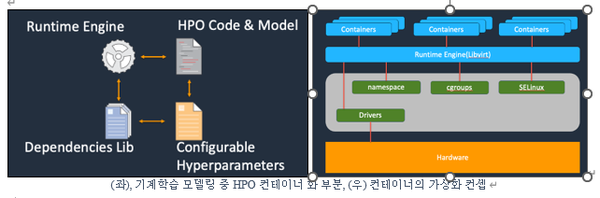
컨테이너는 프로세스가 하나의 독립 공간(Network/ File-System/ Process etc.)인 것과 같이 독립적으로 동작할 수 있도록 하는 네임스페이스(namespace), CPU/메모리/IO/ 네트워크 등의 자원들을 컨테이너 프로세스에 할당하는 Cgroups, 컨테이너간 서로 간섭을 격리하기 위한 역할기반 접근제어 Selinux로 구성된다.
따라서 각 클러스터 워커 서버에서는 HPO에 필요한 복잡한 기계학습 라이브러리가 설치되지 않아도 샌드박스(sandbox) 형태로 탐색 프로세스를 병렬로 실행할 수 있다.
예를 들어, HPO 학습 코드 부분을 컨테이너로 빌드한다면 HPO 모델 학습 부분 코드를 시작점(entry point) 실행 파일로 코드화 시킨 다음, 코드에서 사용하는 ML 패키지 라이브러리를 베이스 컨테이너 이미지에 미리 설치하고, 하이퍼매개변수들을 입력 변수로 바인딩 받을 수 있도록 생성한다.
AWS 클라우드 플렛폼을 이용하여 분산 HPO 플렛폼을 구축한다면 아래와 같은 설계 디자인으로 하이퍼매개변수 최적화 기계학습 워크플로우를 자동화할 수 있다.
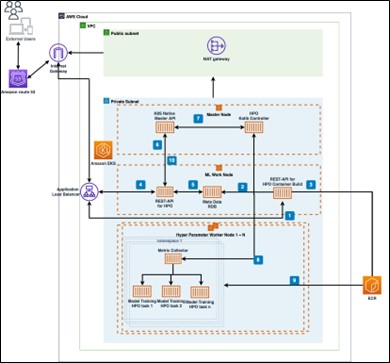
1. ML 엔지니어가 HPO 컨테이너를 카티브 템플릿, HPO코드 파일과 함께 API HPO 컨테이너 빌드 요청
2. 사용자 코드 및 카티브 템플릿정보를 데이터베이스에 입력
3. HPO 코드파일과 기본 이미지를 이용하여 HPO 탐색 컨테이너 빌드 트리거
4. 카티브 UI, 또는 사용자 생성 API에서 생성한 컨테이너 이미지 기반 HPO 작업 요청
5. 데이터베이스에 기록된 컨테이너 및 HPO yaml 템플릿을 이용해 멀티클러스터 분산 HPO작업 지정 조회(예를 들어, 랜덤 검색 7회 반복, 1회당 GPU 4개를 사용하는 HPO 프로세스 동시 4개 실행)
6. Katib UI 또는, K8S native master api에 GRPC로 HPO yaml 작업 요청
7. K8S master API는 자동 카티브 API 컨테이너작업 호출
8. 카티브/K8S는 컨테이너 클러스터 노드에 분산해서 K8S 서비스 프로세스 작업을 분산 실행 요청
9. K8S 클러스터 노드들은 작업 요청을 받은 HPO 컨테이너 이미지를 다운로드 후 프로세스 자동 실행
10. 탐색 진행 중, 또는 진행 완료된 HPO 메트릭 정보는 Katib UI, 또는 사용자 구현 gRPC API로 K8S Native Master Api를 호출하여 조회
프로비저닝된 K8S HPO 작업과 관련해 pod 내부의 카티브 컬렉터(Collector)는 주기적으로 모델 학습 Score 로그를 수집하고, 카티브에 전송한다. 따라서, 완료되지 않은 시도중인 HPO의 작업 메트릭정보도 조회할 수 있다.
하이퍼매개변수 최적화 엔지니어링을 위한 준비
지금까지 하이퍼매개변수 최적화 알고리즘의 종류와 동작 방식에 대한 기본개념, 테스트 데이터를 이용한 각 HPO 알고리즘에 따른 성능 비교 실험, 분산 컴퓨팅 환경에서 HPO 작업을 컨테이너화하고, 워크플로우 코디네이팅 및 ML 플랫폼을 현대화하는 방법에 대해 살펴보았다.
하이퍼매개변수 최적화 알고리즘은 모델의 디자인 특징이나 매개 변수의 종류, 또는 범위에 따라 다양하게 사용하는 것이 좋다. 컴퓨팅 파워에 제약이 비교적 유연한 분산 클러스터를 사용할 수 있는 환경에서는 찾으려는 하이퍼매개변수의 범위를 넓게 가져가고, 랜덤 서치와 같은 알고리즘을 사용하여 빠르게 병렬 탐색 후 결과를 도출하는 것도 좋은 방법이다.
성공적인 ML자동화 모델링은 컴퓨팅 자원의 제약에 관계없이 빠르게 품질 높은 모델을 테스트한 다음 빠르게 제공해서 비즈니스의 팀과의 시너지를 높이는데 있다고 볼 수 있다.
이러한 공통적인 이해를 출발점으로 HPO 뿐만 아니라 기계학습 플랫폼에 연관된 팀들의 역할 분배 및 협업이 중요하다. 예컨대, 모델 알고리즘을 주로 개발하는 팀에서는 모든 컴퓨팅 자원의 분산 리소스를 관리하거나 운영하기 어렵다. 또한 컴퓨팅 플랫폼 엔지니어 입장에서도 모델 학습에 필요한 알고리즘이 어떻게 동작하고 왜 GPU가 100개나 필요한지 이해하지 못할 수 있다. ML 자동화 또한 다른 데브옵스(DevOps)와 마찬가지로 각자의 전문 분야를 존중하고, 역할에 따른 페르소나를 정립한 다음 장기적인 관점을 바탕으로 개선해야 하는 활동이다.
