


신중훈 AWS코리아 솔루션즈 아키텍트

※ 신중훈 아마존웹서비스(AWS) 코리아 솔루션즈 아키텍트는 금융권을 상대로 클라우드 전략을 제안하고 클라우드 전환을 지원하는 정보관리기술사다. 솔루션즈 아키텍트 활동 이전에는 금융 회사에서 근무했다.
[아이티데일리] 2016년 세계 경제 포럼(World Economic Forum)에서 ‘4차 산업혁명’의 개념이 소개된 이후 국내외 기업은 4차 산업혁명 시대의 성공을 위한 디지털 전환(Digital Transformation)에 주목하기 시작했다. 이후 각 산업 분야에서 디지털 기술을 바탕으로 한 새로운 형태의 비즈니스 모델이 제시되면서 산업 간의 경계가 허물어지는 빅 블러(Big blur) 현상이 나타났다. 이런 현상을 포괄하는 디지털 전환은 최근 2년의 코로나 팬데믹 현상으로 더욱 가속화되는 추세다.
디지털 전환을 주도하는 기술은 사물 인터넷(IoT), 클라우드, 빅데이터, 인공지능(AI) 등 다양하지만 이 중에서도 빅데이터와 AI는 모든 산업 분야에서 주목하고 있는 디지털 기술이라고 볼 수 있다.
우리나라는 2020년 8월 ‘데이터 3법’ 시행에 들어갔으며, 지난 4월에 시행된 ‘데이터 산업진흥 및 이용촉진에 관한 기본법’은 전 산업을 아우르는 세계 최초의 데이터 기본법으로 ‘데이터 경제’ 시대의 도래를 앞두고 제도적 초석이 될 것으로 보인다. 또한 금융 분야에서 시행되는 마이데이터(My Data) 서비스가 정보 주체의 데이터 이동권(Right to Data Portability)을 보장하고 데이터를 활용한 맞춤형 정보를 제공하고 있는 만큼, 초개인화 금융 서비스의 등장이 가능해질 것으로 보인다.
이번 기고문에서는 다가오는 데이터 경제 시대를 위한 준비의 일환으로 현재의 정보 시스템 환경을 재조명하고, 초개인화 비즈니스를 위한 주요 데이터 기술들을 살펴보고자 한다.
정보 처리 시스템 환경
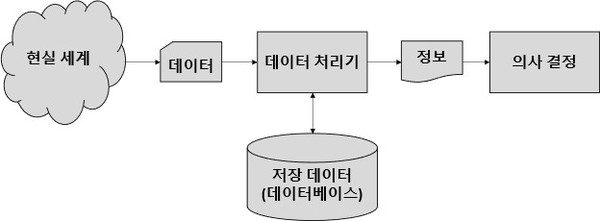
정보 처리 시스템은 현실 세계의 데이터를 수집, 저장하고 저장된 데이터를 가공하여 유용한 정보를 생성, 의사 결정에 활용하는 시스템이다. 이러한 정보 처리 시스템은 크게 조직의 비즈니스 활동을 추적 관리하기 위한 거래 처리 시스템(Transaction Processing System, TPS)과 조직 내 의사 결정을 지원하기 위한 의사결정시스템(Decision Support System, DDS)으로 분류된다. 이는 데이터 처리 방식에 따라 온라인 처리 시스템과 일괄 처리 시스템으로 분류되기도 하는데, 온라인 처리 시스템은 데이터 사용자를 중심으로 실시간 데이터(real-time data)를 처리하는 반면 일괄 처리 시스템의 경우에는 데이터 사용자가 아닌 시스템 중심으로 데이터를 순차적으로 처리하며 높은 성능이 요구된다.
데이터 저장소로서의 관계형 데이터베이스
관계형 데이터베이스는 현실 세계의 값이나 사실을 설명하는 개체(Entity)와 개체를 구성하는 속성(Attribute) 간의 ‘복잡한 관계’들에 대해서 함수적 종속성(functional dependency)을 식별하고 이를 논리적으로 표현하기에 용이하다. 따라서 운영 데이터를 저장하고 활용하는 데 있어서는 오늘날 온라인 처리 시스템, 일괄 처리 시스템 구분 없이 관계형 데이터베이스가 범용적으로 쓰이고 있다.
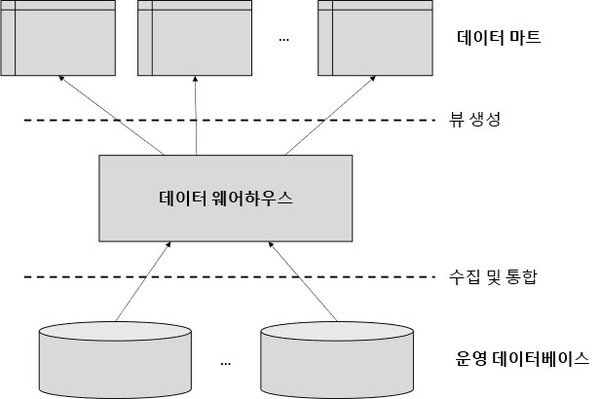
네트워크에 분산되어 있는 다수의 데이터베이스로부터 데이터를 수집, 통합, 분석하기 위해서는 데이터 웨어하우스(Data Warehouse)를 구축하는 것이 일반적이다. 물론 관계형 데이터베이스를 활용해서 데이터를 통합, 분석할 수도 있지만 데이터 웨어하우스는 관계형 데이터베이스와는 다르게 데이터 속성(컬럼) 기반의 분석과 MOLAP, ROLAP 등 다양한 데이터 모델, 그리고 병렬 처리(Massive Parallel Processing, MPP)를 지원하기 때문에 대규모의 데이터를 분석하기 위한 수단으로 전문적인 데이터 웨어하우스 솔루션을 도입하기도 한다. 또한 데이터 마트(Data Mart)는 특정 부서나 사업을 지원하는 소규모로 구축한 데이터 웨어하우스를 의미하는데, 최종 사용자가 이를 기반으로 직접 데이터를 탐색하고 의사 결정에 활용할 수 있다.
다중 데이터 저장소와 분산 컴퓨팅 환경 도입
세계 모든 데이터 중 텍스트, 비디오, 오디오, 서버 로그 등 비정형 데이터(Unstructured data)가 80% 이상의 비중을 차지한다. 이러한 비정형 데이터를 처리(수집, 분석, 저장)할 수 있는 기술들이 대거 등장하면서 기존 정보 처리 시스템에서도 많은 변화를 꾀하며 비정형 데이터에서도 비즈니스 통찰력을 얻는 방안을 강구하고 있다.
그중에서도 가장 큰 관심을 받는 부분은 데이터 기술이다. 현실 세계의 값이나 사실을 데이터베이스로 관리하기 위해서 데이터 구조를 사전적으로 정의(Schema-On-Write)해야 했던 관계형 데이터베이스와는 다르게, 데이터 기술을 통해서 흔히 빅데이터라고 부르는 원시 데이터를 저장하고 데이터를 사용하는 시점에 원하는 데이터 속성(컬럼)들을 대상으로 데이터 구조를 유연하게 정의(Schema-On-Read)할 수 있다.
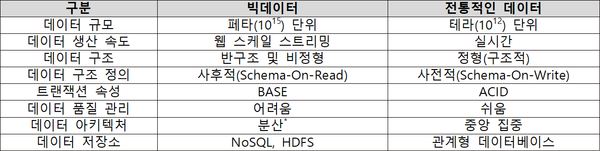
우선 NoSQL 데이터베이스가 도입되기 시작했다. NoSQL 데이터베이스는 관계형 데이터베이스와는 다르게 반정형 및 비정형 데이터 구조를 사용할 수 있기 때문에 웹 스케일의 트랜잭션을 처리하기 위한 현대적인 응용 시스템에 많이 적용된다. 그리고 데이터 구조가 관계형 데이터베이스와 비교했을 때 상대적으로 간단하고(키값Key-Value, 컬럼 기반Column-Family, 도큐먼트Document 등) 수평적으로 확장이 가능한 분산 저장소를 지원하기 때문에 관계형 데이터베이스보다 높은 성능을 기대할 수 있다.
또한 분산 데이터 저장소는 클러스터를 이용한 분산 컴퓨팅을 활용하기 때문에 관계형 데이터베이스의 트랜잭션 속성인 ACID(Atomicity, Consistency, Isolation, Durability)를 지원하지 않고 BASE(Basically Available, Soft-State, Eventual consistency)을 보장한다. 추가적으로 분산 데이터 저장소에 대해 더 많은 특성을 이해하려면 CAP 이론과 PACELC 이론을 확인하면 도움이 될 것이다.
최근 대용량의 데이터를 저장, 처리하기 위해 오픈소스 소프트웨어를 도입하는 사례가 많아지고 있다. 특히 대규모의 데이터를 처리하기 위해서 고사양의 단일 시스템을 사용하는 것이 아니라 많은 범용 컴퓨터를 네트워크로 연결하여, 클러스터를 구성하고 데이터를 분산 저장 및 처리할 수 있는 아파치 하둡(Apache Hadoop) 프레임워크가 널리 사용되고 있다.
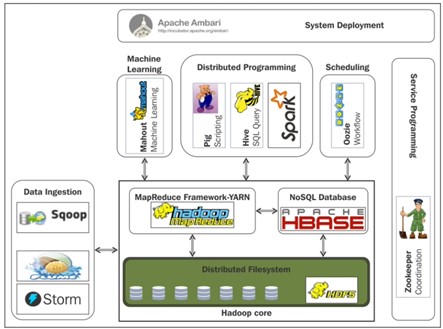
아파치 하둡은 하둡 분산 파일 시스템(Hadoop Distributed File System, HDFS)을 비롯해서 NoSQL 데이터베이스(HBase), SQL기반의 데이터 웨어하우스(Hive)를 구축할 수 있고 인-메모리 데이터 처리가 가능한 아파치 스파크(Apache Spark)와 통합할 수 있다. 이러한 아파치 하둡을 활용한 데이터 분석 환경은 통계적 기법을 활용하여 비즈니스 의사결정에 활용하기 위한 정보를 획득하는 것뿐만 아니라 AI, 기계 학습(ML)과 같은 고급 분석을 활용하여 초개인화 서비스 모델을 만들기 위한 기반 기술로도 각광받고 있다.
지금까지 설명한 내용을 바탕으로 데이터 요구사항에 알맞은 데이터베이스 선택을 위해 활용할 수 있는 기준을 제시하겠다.
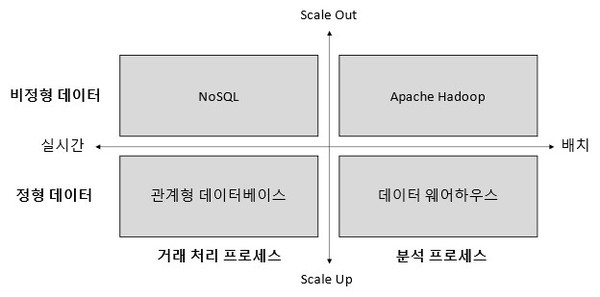
먼저 세로축은 데이터 유형과 확장성을 나타낸 것이다. 정형 데이터를 관리하기 위해서는 관계형 데이터베이스와 데이터 웨어하우스를 사용하고 비정형 데이터를 관리하기 위해서는 NoSQL이나 HDFS를 사용하는 것이 일반적이다. 그리고 데이터 규모가 증가할 때 관계형 데이터베이스와 데이터 웨어하우스는 높은 사양의 하드웨어를 사용(Scale up)해야 하는 반면, NoSQL과 HDFS의 경우는 범용 하드웨어를 수평적으로 확장(Scale out)할 수 있다.
가로축은 데이터를 처리하는 트랜잭션 속성에 따라 분류한 것이다. 거래 처리 프로세스(OLTP)에는 관계형 데이터베이스와 NoSQL가 적합한 반면, 의사 결정 지원 시스템과 같은 분석 프로세스(OLAP)에는 데이터 웨어하우스나, 아파치 하둡 오픈 소스 소프트웨어 플랫폼을 사용하는 것이 좋다.
데이터 레이크(Data Lake)의 등장
데이터 레이크는 거래 처리 시스템의 데이터를 비롯해서 센서 데이터, 소셜 데이터 등 원시 데이터의 복사본이나 탐색적 분석, 보고서, ML과 같은 작업에 사용되는 변환된 데이터를 포괄하는 ‘단일 데이터 저장소’이다.
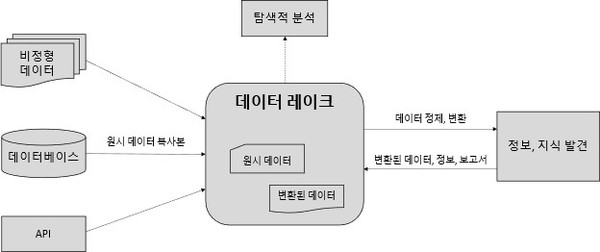
먼저 데이터 레이크는 데이터의 유형과 포맷에 관계없이 데이터를 저장할 수 있다. 또한 데이터를 데이터 레이크에 저장하기 전에 전 처리가 필요하지 않는 편리성을 가진다. 즉, 일반적으로 원시 데이터의 구조가 동적 스키마(dynamic schema)인 경우 데이터를 저장하기 전에 데이터를 구조화하고 정제하는데 많은 시간과 노력이 요구되지만, 데이터 레이크에서의 데이터 정제 작업은 데이터를 분석하는 시점에만 필요하다.
이러한 데이터 레이크의 특징으로는 데이터 분석을 위한 아키텍처를 유연하게 설계할 수 있고, 데이터 엔지니어 혹은 데이터 분석가가 원하는 도구를 활용하여 데이터를 탐색할 수 있으며, 분석이 용이하다는 점이 있다. 이처럼 많은 장점을 지니고 있는 데이터 레이크 기반의 아키텍처는 데이터 분석 환경을 구축하는데 있어서도 각광받고 있다.
데이터 마이닝과 AI
데이터 마이닝은 대규모의 데이터로부터 관련된 정보나 패턴을 발견하는 프로세스이다. 이를 위해서는 데이터 웨어하우스를 도입하는 것이 효과적인데, 데이터 웨어하우스는 원천이 되는 다수의 데이터베이스로부터 이미 데이터를 수집, 정제, 변환하여 통합, 저장하고 정보로 가공했기 때문에 고품질의 데이터 및 데이터 카탈로그를 활용하여 데이터 마이닝을 하기에 이상적이다.
대표적인 데이터 마이닝 기법으로는 이상치 탐지(Anomaly detection), 연관 규칙(Association rule), 클러스터(Cluster), 분류(Classification), 회귀(Regression) 분석이 있다.
ML과 딥러닝(Deep Learning)을 활용하는 정보 시스템이 등장하기 전까지는 특정 영역의 문제를 해결하기 위하여 규칙기반 ‘전문가 시스템(Expert System)’을 구축했지만, 최근에는 ML, 딥러닝 등을 활용하여 업무를 자동화(Robotic Process Automation, RPA)하고 초개인화 서비스 모델을 만들기 위한 시도가 이어지고 있다.
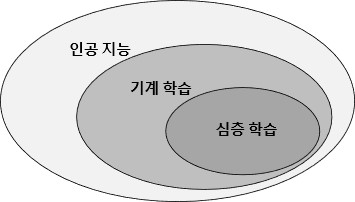
AI는 인간의 지각, 학습, 추론 능력을 모방하여 기계가 보여주는 지능으로 ML, 딥러닝을 포함한 개념이다. 또한 ML은 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)으로 분류된다.
지도 학습은 입력 값에 대한 출력 값이 있는 데이터(Labeled Data Sets)로부터 새로운 데이터가 있을 때 출력 값을 결정할 수 있는 패턴을 찾는 학습 방법으로 분류(Classification)나 회귀(Regression) 분석이 대표적이다.
비지도 학습은 입력 값에 대한 출력 값이 없는 데이터(Unlabeled Data Sets)로부터 특정 패턴을 찾는 학습 방법으로 군집 분석(Clustering)이 대표적이다. 강화 학습은 학습 알고리즘이 환경과 상호 작용하면서 주어지는 누적 기대 보상 값(Reward)이 최대가 되는 정책을 학습하는 방법으로 상태 전이가 현재의 상태와 입력에 의해 확률적으로 정해지는 마르코프 결정 프로세스(Markov Decision Process)에 기초한다.
딥러닝은 심층 신경망(Deep Neural Network)을 사용하여 데이터로부터 특징을 추출하고 문제 해결을 위한 학습을 동시에 할 수 있는 ML의 한 유형으로 이미지로부터의 객체 분류나 음성 인식, 자연어 처리 등이 대표적이다.
ML 과정
CRISP-DM(CRoss-Industry Standard Process for Data Mining)은 데이터 마이닝을 위한 개방형 표준 프로세스이다. CRISP-DM은 데이터로부터 지식을 발견하는 표준 프로세스인 KDD(Knowledge Discovery in Databases)의 변형으로 비즈니스에 대한 문제 인식과 해결을 위한 절차를 포함하는 것이 특징적이다. 비즈니스 문제를 해결하기 위한 ML 과정을 CRISP-DM 프로세스로 표현하면 다음과 같다.
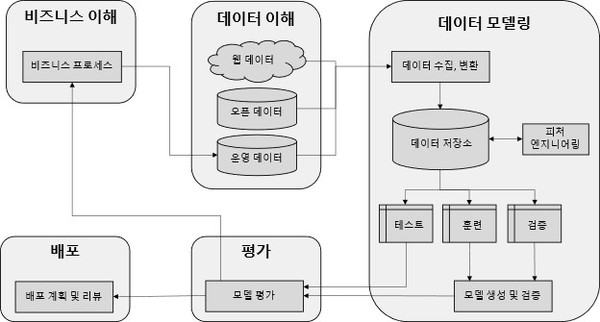
● 비즈니스 이해 : 먼저 산업 분야와 조직이 영위하고 있는 비즈니스에 대한 이해가 필요하다. 이 단계에서는 비즈니스 전문가와 데이터 분석가가 함께 비즈니스 목표와 ML 목표를 수립하고 프로젝트 계획을 세운다.
● 데이터 이해 : 비즈니스 이해를 바탕으로 데이터 요구사항을 확인한다. 정보 시스템에서 이미 관리하고 있는 데이터를 비롯하여 새로운 데이터를 수집, 탐색하고 데이터 품질을 확인한다.
● 데이터 모델링 : 기계 학습을 위해 데이터를 준비하는 ETL(추출, 변환, 로드) 단계이다. 식별된 데이터에 대한 정제, 구조화 및 포맷을 정의하고 데이터 저장소에 저장한다. 이때 수집하는 데이터에 대한 자동화된 데이터 파이프라인 구축도 가능하다. 이후 수집한 데이터를 기반으로 피처 엔지니어링(Feature Engineering)을 수행하고 훈련 데이터(training data), 검증 데이터(validation data), 테스트 데이터(test data)로 분할한다.
훈련 데이터에 종속적(Overfitting)이지 않고 새로운 데이터에 대해서도 잘 분류하거나 예측할 수 있는 일반화된 모델(generalized model)을 만드는 것이 중요하기 때문에 데이터를 세 종류로 분류하고 있으며, 모델 생성 및 검증 단계에서는 훈련 데이터와 검증 데이터만 사용한다.
● 평가 : 모델이 완성되면 비즈니스 목표에 부합하는 모델이 만들어졌는지 확인하기 위해 테스트 데이터로 모델을 평가하고 평가 결과에 따라 배포 계획을 수립하거나 생성된 모델을 보완하기 위한 다음 단계를 결정한다.
● 배포 : 생성된 모델에 대한 배포 계획을 수립한다. 그리고 시시각각 변하는 비즈니스 환경에서도 배포한 모델이 올바르게 작동할 수 있도록 배포 라이프 사이클(deployment life cycle)을 관리한다.
클라우드 컴퓨팅 환경에서의 빅데이터(Big Data in the Cloud)
데이터 기술을 조직 내에 새롭게 도입하거나 이를 운영하는 과정에서 빈번하게 고민하는 사항들로는 다음과 같은 이슈들이 있다.
● 스케일의 트랜잭션을 처리하기 위한 컴퓨팅 자원이 필요하다. 또는 일시적으로 큰 규모의 자원이 필요한 비즈니스 이벤트나 이미 알려진 트랜잭션 패턴이 있다.
● 비즈니스 통찰력을 얻기 위해 정형 데이터를 비롯해서 비정형 데이터를 수집, 저장하기 위해서는 대규모의 데이터를 저장할 스토리지가 필요한데 스토리지 구매에 필요한 규모 산정이 어렵다.
● 유형과 포맷에 상관없이 대규모의 데이터를 포괄적으로 저장하고 거버넌스하기 위한 데이터 레이크가 필요하다.
● 사용자 누구나 직접 데이터에 접근해서 데이터를 탐색하고 비즈니스에 응용할 수 있는 ‘셀프 서비스’ 환경이 필요하다.
● 과학자가 새로운 가설을 개발하고 테스트 할 수 있는 샌드박스 환경이 필요하다.
하지만 위와 같은 데이터 요구 사항을 수용하기 위해서는 대규모의 인프라 투자 뿐만 아니라 다양한 분석, 가시화 도구가 수반되어야 한다. 더 나아가 데이터에 대한 보안, 감사, 내부 통제를 위한 거버넌스 도구가 반드시 필요하다.
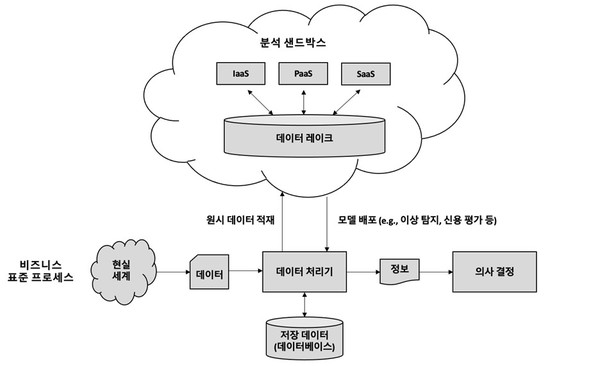
클라우드 컴퓨팅은 서버, 스토리지, 데이터베이스, 네트워크 등의 자원을 직접 소유하지 않고 자원에 대한 수요가 발생 시 바로(On-demand) 인터넷을 통해 자원을 사용할 수 있는 기술이다. 현대의 다양한 데이터 요구사항을 수용하기 위해서 클라우드 컴퓨팅을 도입할 경우 다음과 같은 이점을 누릴 수 있다.
먼저 클라우드 컴퓨팅 서비스는 자원을 사용한 만큼 비용이 발생(Pay-Per-Use)하기 때문에 처음부터 데이터를 분석하기 위한 대규모 인프라 투자에 대해서 고민할 필요가 없다. 데이터 처리를 위한 컴퓨팅 자원을 목표로 하는 성능에 맞춰 탄력적으로 확장 또는 축소할 수 있기 때문이다. 또한 데이터 유형과 포맷에 상관없이 대규모 데이터 저장이 가능하며, 데이터 요구 사항에 맞는 데이터베이스를 선택해서 사용할 수 있다. 데이터 저장소를 데이터 레이크로 구성할 경우 데이터 사용자는 셀프 서비스를 사용해서 데이터에 대한 접근성과 가용성을 높일 수도 있다. 또한 데이터 저장소에 대한 조직 차원의 데이터 카탈로그 관리와 백업, 감사, 추적이 가능하기 때문에 데이터 거버넌스 환경을 구축할 수 있다.
‘데이터 중심의 의사 결정’을 중요하게 생각하는 토스페이먼츠의 경우 클라우드에 데이터 레이크와 대용량 데이터 처리 플랫폼을 구축함으로써 실무자들이 셀프 서비스로 데이터 기반의 의사 결정을 내릴 수 있는 분석 인프라를 구축했다.
KB국민카드는 금융 분야 마이데이터 사업을 추진하는 데 있어서 데이터 분석계를 데이터 레이크와 ML환경을 구축함으로써 데이터 인프라의 탄력성과, 보안성, 그리고 새로운 금융 서비스를 실험하고 배포할 수 있는 확장성을 확보했다.
또한 신한금융그룹은 주요 계열사에 흩어져 있던 데이터를 신한 원데이터(One Data)를 통해 클라우드로 통합하고 AI 등을 활용해서 고객 맞춤형 금융 서비스를 제공하기 위한 기반을 마련하는 등 금융 산업 분야에서는 이미 클라우드 컴퓨팅 환경에 빅데이터 분석 환경을 구축하여 새로운 비즈니스 프로세스와 솔루션으로 차별화된 경쟁력을 확보하기 위한 경쟁이 치열하다.
데이터 거버넌스, 데이터 품질 관리
지금까지 데이터 경제 시대를 준비하기 위해 현재의 정보 시스템 환경을 재조명하고 초개인화 비즈니스를 위한 주요 데이터 기술들을 살펴보았다. 하지만 수많은 데이터 기술 중 특정 기술(알파고에 적용된 DQN 등)을 조직 내에 도입했다고 해서 비즈니스 혁신이 이뤄지는 것은 결코 아니다.
먼저 데이터 기술에 대한 투자는 비즈니스 목표와 연계되어야 한다. 그리고 데이터의 가용성, 유용성, 무결성, 보안 등 ‘데이터 품질’을 관리하는 것이 중요하다. 낮은 품질의 데이터는 조직의 비즈니스 의사결정에 사용되기 어려울 뿐만 아니라, 잘못 사용될 경우 높은 실패 비용이 발생한다. 이는 또한 고객에게 제공하는 서비스나 제품의 가격 상승으로 이어져 사회적 비용 증가를 초래하기도 한다.
따라서 데이터 품질을 지속적으로 관리하기 위한 데이터 관리 원칙과 데이터 관리 조직, 데이터 관리 프로세스 구축이 필요하다. 마지막으로 데이터를 활용해서 비즈니스 목표를 달성하기 위해 확장 가능한 유연한 인프라 구성과 데이터 기술의 내재화에 적극 나서야 한다.