


딜로이트 컨설팅 코리아 은희용 Tech Strategy & Transform 팀장

[아이티데일리] 기업이 퍼블릭 클라우드 도입에서 기대하는 것은 IT 시스템의 확장성과 관리의 용이성도 있지만 사용한 만큼 비용을 지불할 수 있다는 경제적 이점이 크다. 그런데 클라우드의 유연한 과금정책이 어떤 기업에게는 독이 되기도 한다. 온프레미스 환경때보다 비용이 더 증가하는 것이다.
또한 애플리케이션 현대화 없이 퍼블릭 클라우드로 마이그레이션을 했다가 1~2년 내 온프레미스로 돌아가는 현상도 있다. 전 세계 24개국에서 IT임원 2,650명을 대상으로 한 2019년 뉴타닉스 조사에 따르면, 73%가 애플리케이션을 퍼블릭 클라우드에서 온프레미스로 다시 이동시키고 있다고 응답했다. 클라우드 전환이 능사가 아니라는 것이다.
딜로이트 컨설팅 코리아는 클라우드 적합도 평가 프레임워크를 토대로 많은 기업들이 클라우드 도입 전 방향성을 수립하고 성공적으로 클라우드 마이그레이션 할 수 있도록 지원해왔다. 이 과정에서 비효율적인 시스템 운영 관례를 개선해왔는데 클라우드를 클라우드답게 사용한다는 것은 단순히 기술만 바꾸는 것을 의미하지 않으며 기술을 사용하는 사람들의 인식 변화가 선행해야 한다는 사실을 확인했다. 또 이러한 인식의 변화는 비용에 직접적인 영향을 미쳤다.
다음의 예시를 통해 살펴보자. 한 기업의 서비스 트래픽을 처리하기 위해 CPU 8core 와 Memory 64GB, Disk 200GB가 필요하다면, 온프레미스에서는 통상 <그림1>과 같이 CPU 16 core와 Memory 128GB, Disk 400GB를 구성한다.
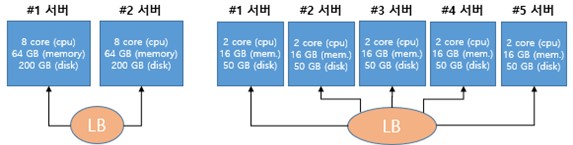
<그림1>처럼 구성하는 것은 하나의 서버가 비정상 동작하더라도 나머지의 서버로 모두 서비스를 할 수 있어야 하기 때문이다. 온프레미스에서는 #1서버에 장애가 발생하면 경우에 따라서 복구 시간이 얼마나 길어질지 알 수 없기 때문에 용량을 크게 산정한다. 서비스의 중단이 기업 브랜드 이미지에 미치는 영향이 치명적이기 때문이다.
반면 <그림2>처럼 구성하면 하나의 서버가 종료되어도 목표 리소스만큼 수용할 수 있게 된다. 2대 이상의 서버가 동시에 종료되는 사례가 많지 않아 목표 성능과 가용성을 보장할 수 있다. 2018년 ‘AWS 클라우드 기반 장애 극복 부하분산 메커니즘 및 가용성 평가’ 연구 결과에서도 병렬 구조를 이루는 서버 수를 증가시키면 가용성도 비례하는 것으로 나타났다.

<그림1>과 <그림2>의 다른 구성은 <표1>의 비용처럼 월 20만 원 정도의 비용 차이를 발생시킨다. 클라우드 컴퓨팅의 용량 산정에 따라 비용을 탄력적으로 운용할 수 있다는 뜻이다.
여기에는 필요시 시스템 용량을 증설해서 사용하고 리소스 최적화를 지원하는 오토스케일(Auto Scale) 기술이 활용된다. 오토스케일(Auto Scale) 기능을 적용하면 사람의 개입을 최소화하고, 시스템 가용성을 보장하는 동시에 서비스 안정성을 유지할 수 있다.
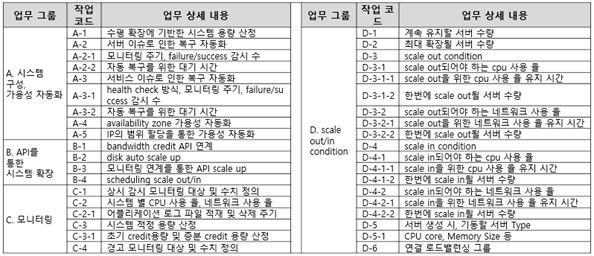
클라우드 전환에는 용량 산정 방식 외에도 시스템 관리자의 업무에 대해서도 재정의가 필요하다. <표2>처럼 크게 4가지 측면으로 고려해 볼 수 있다. 첫 번째로 시스템 가용성은 클라우드 서비스 사업자가 제공하게 되므로 시스템 관리자는 모니터링 범위를 시스템 가용성에서 서비스 전체로 확대하는 등의 변화가 필요하다. 또한 클라우드 서비스 사업자가 직접 자동화를 제공하지 않는 것은 API를 통해 자동화 처리할 수 있도록 하고 시스템의 위험 영역을 경보로 등록해 시스템 관리자에게 알람을 제공하도록 구성하고, 발생하는 경보가 재발하거나 장애로 연결되지 않도록 자동화를 확장해야 한다.
마지막으로 서비스의 안정성과 비용 최적화를 고려해 오토스케일 조건을 정의해야 한다. 스케일아웃(scale-out) 조건을 민감하게 반응하도록 할당하면, 목표 값을 높게 설정하지 않아도 서비스를 안정적으로 제공할 수 있다. 2021년 진행된 ‘K-Means Clustering 알고리즘 기반 클라우드 동적 자원 관리 기법에 관한 연구’에서도 프로비저닝(provisioning) 단계에서 필요한 자원만큼만 최적의 인스턴스 타입(instance type)을 선택해 잉여 자원을 최소화하는 것이 중요하다고 제언한 바 있다.
정리하자면 레거시 시스템에서의 모니터링 방식을 그대로 클라우드 환경에서 적용하는 것은 문제 감지를 늦추고 또 장애에 대해 신속한 해결을 어렵게 만든다. 이 때문에 시스템 관리자들이 클라우드 환경에서의 모니터링 업무를 장애 또는 이슈를 관찰하는 역할이 아닌 자동화를 구성하기 위한 장치 또는 기초데이터로 인식하는 것이 필요하다.
점점 더 많은 기능이 클라우드에서 ‘As-a-Service’ 상태로 제공됨에 따라 서비스가 실시간으로 개선되고 업데이트될 것이라는 기대가 커지고 있다. 클라우드를 적극적으로 활용하기 위해서는 기존 IT 모델을 기반으로 시스템 관리자가 갖고 있는 업무 인식으로는 신속한 서비스 대응이 불가능하다. 단순히 인프라뿐만 아니라 시스템 관리자의 일하는 방식과 인식의 변화 또한 수반되어야 한다.
얼마나 자주 웹 사이트에 대한 트래픽이 최대 용량을 초과해 이슈를 발생시키고 있는지, 또 효율적으로 사용되지 않는 컴퓨팅 리소스를 구입하고 프로비저닝 및 유지 관리에는 얼마나 많은 비용을 지출하는지 등과 같은 문제 해결 방법은 클라우드를 활용에 대한 인식과도 직결된다.